 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Privacy Variance
Mar 16, 2025We propose the notion of empirical privacy variance and study it in the context of differentially private fine-tuning of language models. Specifically, we show that models calibrated to the same $(\varepsilon, \delta)$-DP guarantee using DP-SGD with different hyperparameter configurations can exhibit significant variations in empirical privacy, which we quantify through the lens of memorization. We investigate the generality of this phenomenon across multiple dimensions and discuss why it is surprising and relevant. Through regression analysis, we examine how individual and composite hyperparameters influence empirical privacy. The results reveal a no-free-lunch trade-off: existing practices of hyperparameter tuning in DP-SGD, which focus on optimizing utility under a fixed privacy budget, often come at the expense of empirical privacy. To address this, we propose refined heuristics for hyperparameter selection that explicitly account for empirical privacy, showing that they are both precise and practically useful. Finally, we take preliminary steps to understand empirical privacy variance. We propose two hypotheses, identify limitations in existing techniques like privacy auditing, and outline open questions for future research.
Tukey Depth Mechanisms for Practical Private Mean Estimation
Feb 25, 2025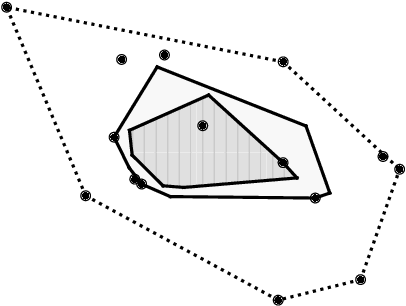
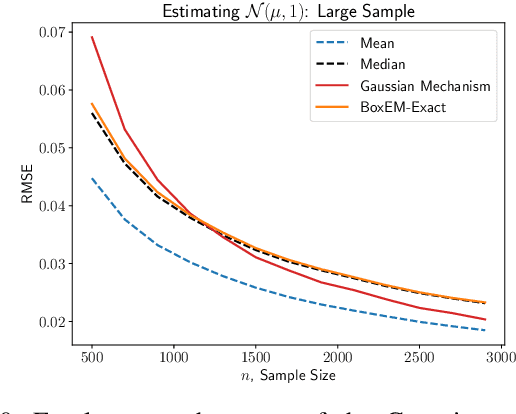
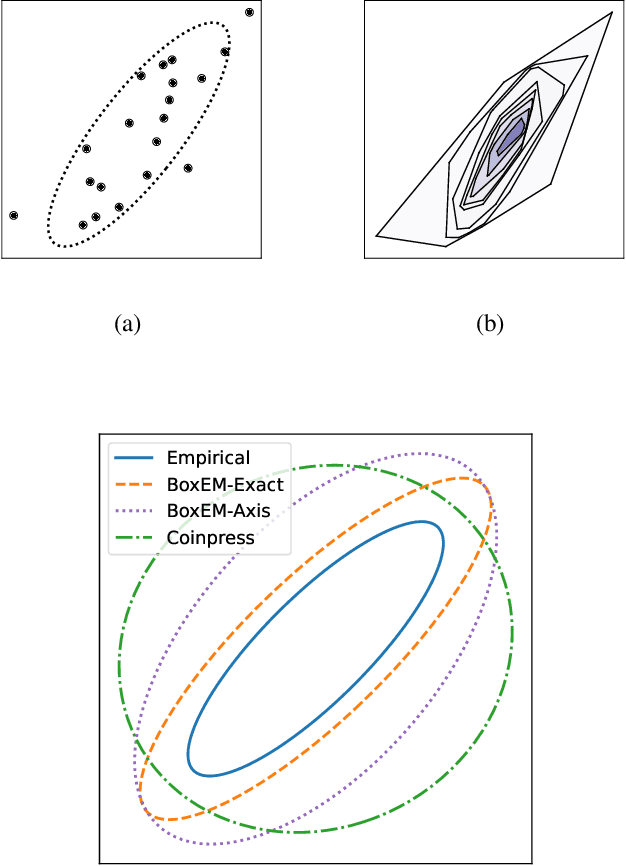
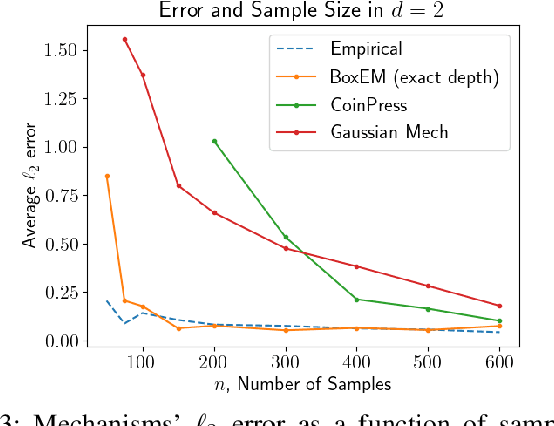
Mean estimation is a fundamental task in statistics and a focus within differentially private statistical estimation. While univariate methods based on the Gaussian mechanism are widely used in practice, more advanced techniques such as the exponential mechanism over quantiles offer robustness and improved performance, especially for small sample sizes. Tukey depth mechanisms carry these advantages to multivariate data, providing similar strong theoretical guarantees. However, practical implementations fall behind these theoretical developments. In this work, we take the first step to bridge this gap by implementing the (Restricted) Tukey Depth Mechanism, a theoretically optimal mean estimator for multivariate Gaussian distributions, yielding improved practical methods for private mean estimation. Our implementations enable the use of these mechanisms for small sample sizes or low-dimensional data. Additionally, we implement variants of these mechanisms that use approximate versions of Tukey depth, trading off accuracy for faster computation. We demonstrate their efficiency in practice, showing that they are viable options for modest dimensions. Given their strong accuracy and robustness guarantees, we contend that they are competitive approaches for mean estimation in this regime. We explore future directions for improving the computational efficiency of these algorithms by leveraging fast polytope volume approximation techniques, paving the way for more accurate private mean estimation in higher dimensions.
Dimension-free Private Mean Estimation for Anisotropic Distributions
Nov 01, 2024We present differentially private algorithms for high-dimensional mean estimation. Previous private estimators on distributions over $\mathbb{R}^d$ suffer from a curse of dimensionality, as they require $\Omega(d^{1/2})$ samples to achieve non-trivial error, even in cases where $O(1)$ samples suffice without privacy. This rate is unavoidable when the distribution is isotropic, namely, when the covariance is a multiple of the identity matrix, or when accuracy is measured with respect to the affine-invariant Mahalanobis distance. Yet, real-world data is often highly anisotropic, with signals concentrated on a small number of principal components. We develop estimators that are appropriate for such signals$\unicode{x2013}$our estimators are $(\varepsilon,\delta)$-differentially private and have sample complexity that is dimension-independent for anisotropic subgaussian distributions. Given $n$ samples from a distribution with known covariance-proxy $\Sigma$ and unknown mean $\mu$, we present an estimator $\hat{\mu}$ that achieves error $\|\hat{\mu}-\mu\|_2\leq \alpha$, as long as $n\gtrsim\mathrm{tr}(\Sigma)/\alpha^2+ \mathrm{tr}(\Sigma^{1/2})/(\alpha\varepsilon)$. In particular, when $\pmb{\sigma}^2=(\sigma_1^2, \ldots, \sigma_d^2)$ are the singular values of $\Sigma$, we have $\mathrm{tr}(\Sigma)=\|\pmb{\sigma}\|_2^2$ and $\mathrm{tr}(\Sigma^{1/2})=\|\pmb{\sigma}\|_1$, and hence our bound avoids dimension-dependence when the signal is concentrated in a few principal components. We show that this is the optimal sample complexity for this task up to logarithmic factors. Moreover, for the case of unknown covariance, we present an algorithm whose sample complexity has improved dependence on the dimension, from $d^{1/2}$ to $d^{1/4}$.
From Robustness to Privacy and Back
Feb 03, 2023We study the relationship between two desiderata of algorithms in statistical inference and machine learning: differential privacy and robustness to adversarial data corruptions. Their conceptual similarity was first observed by Dwork and Lei (STOC 2009), who observed that private algorithms satisfy robustness, and gave a general method for converting robust algorithms to private ones. However, all general methods for transforming robust algorithms into private ones lead to suboptimal error rates. Our work gives the first black-box transformation that converts any adversarially robust algorithm into one that satisfies pure differential privacy. Moreover, we show that for any low-dimensional estimation task, applying our transformation to an optimal robust estimator results in an optimal private estimator. Thus, we conclude that for any low-dimensional task, the optimal error rate for $\varepsilon$-differentially private estimators is essentially the same as the optimal error rate for estimators that are robust to adversarially corrupting $1/\varepsilon$ training samples. We apply our transformation to obtain new optimal private estimators for several high-dimensional tasks, including Gaussian (sparse) linear regression and PCA. Finally, we present an extension of our transformation that leads to approximate differentially private algorithms whose error does not depend on the range of the output space, which is impossible under pure differential privacy.
Multitask Learning via Shared Features: Algorithms and Hardness
Sep 07, 2022
We investigate the computational efficiency of multitask learning of Boolean functions over the $d$-dimensional hypercube, that are related by means of a feature representation of size $k \ll d$ shared across all tasks. We present a polynomial time multitask learning algorithm for the concept class of halfspaces with margin $\gamma$, which is based on a simultaneous boosting technique and requires only $\textrm{poly}(k/\gamma)$ samples-per-task and $\textrm{poly}(k\log(d)/\gamma)$ samples in total. In addition, we prove a computational separation, showing that assuming there exists a concept class that cannot be learned in the attribute-efficient model, we can construct another concept class such that can be learned in the attribute-efficient model, but cannot be multitask learned efficiently -- multitask learning this concept class either requires super-polynomial time complexity or a much larger total number of samples.
Covariance-Aware Private Mean Estimation Without Private Covariance Estimation
Jul 22, 2021We present two sample-efficient differentially private mean estimators for $d$-dimensional (sub)Gaussian distributions with unknown covariance. Informally, given $n \gtrsim d/\alpha^2$ samples from such a distribution with mean $\mu$ and covariance $\Sigma$, our estimators output $\tilde\mu$ such that $\| \tilde\mu - \mu \|_{\Sigma} \leq \alpha$, where $\| \cdot \|_{\Sigma}$ is the Mahalanobis distance. All previous estimators with the same guarantee either require strong a priori bounds on the covariance matrix or require $\Omega(d^{3/2})$ samples. Each of our estimators is based on a simple, general approach to designing differentially private mechanisms, but with novel technical steps to make the estimator private and sample-efficient. Our first estimator samples a point with approximately maximum Tukey depth using the exponential mechanism, but restricted to the set of points of large Tukey depth. Proving that this mechanism is private requires a novel analysis. Our second estimator perturbs the empirical mean of the data set with noise calibrated to the empirical covariance, without releasing the covariance itself. Its sample complexity guarantees hold more generally for subgaussian distributions, albeit with a slightly worse dependence on the privacy parameter. For both estimators, careful preprocessing of the data is required to satisfy differential privacy.
PAC-Bayes, MAC-Bayes and Conditional Mutual Information: Fast rate bounds that handle general VC classes
Jun 17, 2021

We give a novel, unified derivation of conditional PAC-Bayesian and mutual information (MI) generalization bounds. We derive conditional MI bounds as an instance, with special choice of prior, of conditional MAC-Bayesian (Mean Approximately Correct) bounds, itself derived from conditional PAC-Bayesian bounds, where `conditional' means that one can use priors conditioned on a joint training and ghost sample. This allows us to get nontrivial PAC-Bayes and MI-style bounds for general VC classes, something recently shown to be impossible with standard PAC-Bayesian/MI bounds. Second, it allows us to get faster rates of order $O \left(({\text{KL}}/n)^{\gamma}\right)$ for $\gamma > 1/2$ if a Bernstein condition holds and for exp-concave losses (with $\gamma=1$), which is impossible with both standard PAC-Bayes generalization and MI bounds. Our work extends the recent work by Steinke and Zakynthinou [2020] who handle MI with VC but neither PAC-Bayes nor fast rates, the recent work of Hellstr\"om and Durisi [2020] who extend the latter to the PAC-Bayes setting via a unifying exponential inequality, and Mhammedi et al. [2019] who initiated fast rate PAC-Bayes generalization error bounds but handle neither MI nor general VC classes.
Differentially Private Decomposable Submodular Maximization
May 29, 2020
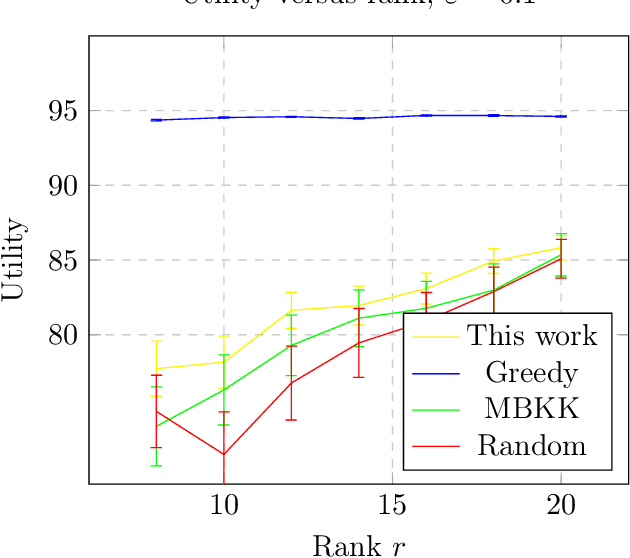
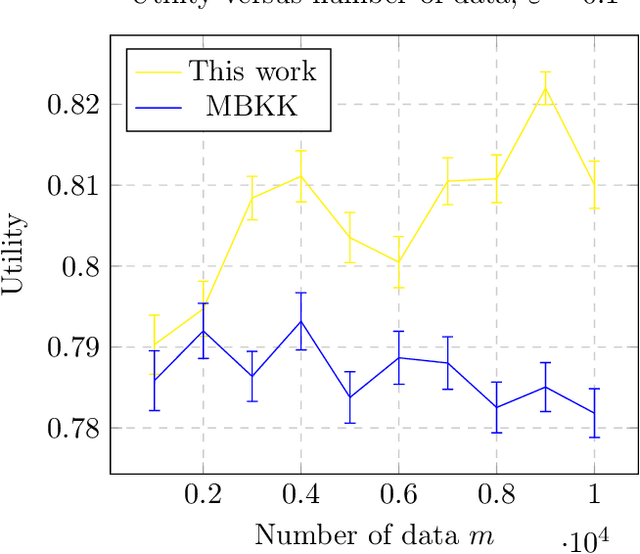
We study the problem of differentially private constrained maximization of decomposable submodular functions. A submodular function is decomposable if it takes the form of a sum of submodular functions. The special case of maximizing a monotone, decomposable submodular function under cardinality constraints is known as the Combinatorial Public Projects (CPP) problem [Papadimitriou et al., 2008]. Previous work by Gupta et al. [2010] gave a differentially private algorithm for the CPP problem. We extend this work by designing differentially private algorithms for both monotone and non-monotone decomposable submodular maximization under general matroid constraints, with competitive utility guarantees. We complement our theoretical bounds with experiments demonstrating empirical performance, which improves over the differentially private algorithms for the general case of submodular maximization and is close to the performance of non-private algorithms.
Reasoning About Generalization via Conditional Mutual Information
Feb 14, 2020We provide an information-theoretic framework for studying the generalization properties of machine learning algorithms. Our framework ties together existing approaches, including uniform convergence bounds and recent methods for adaptive data analysis. Specifically, we use Conditional Mutual Information (CMI) to quantify how well the input (i.e., the training data) can be recognized given the output (i.e., the trained model) of the learning algorithm. We show that bounds on CMI can be obtained from VC dimension, compression schemes, differential privacy, and other methods. We then show that bounded CMI implies various forms of generalization.
Private Identity Testing for High-Dimensional Distributions
May 28, 2019In this work we present novel differentially private identity (goodness-of-fit) testers for natural and widely studied classes of multivariate product distributions: Gaussians in $\mathbb{R}^d$ with known covariance and product distributions over $\{\pm 1\}^{d}$. Our testers have improved sample complexity compared to those derived from previous techniques, and are the first testers whose sample complexity matches the order-optimal minimax sample complexity of $O(d^{1/2}/\alpha^2)$ in many parameter regimes. We construct two types of testers, exhibiting tradeoffs between sample complexity and computational complexity. Finally, we provide a two-way reduction between testing a subclass of multivariate product distributions and testing univariate distributions, and thereby obtain upper and lower bounds for testing this subclass of product distributions.