 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Sample Complexity of Membership Inference and Privacy Auditing
Aug 26, 2025A membership-inference attack gets the output of a learning algorithm, and a target individual, and tries to determine whether this individual is a member of the training data or an independent sample from the same distribution. A successful membership-inference attack typically requires the attacker to have some knowledge about the distribution that the training data was sampled from, and this knowledge is often captured through a set of independent reference samples from that distribution. In this work we study how much information the attacker needs for membership inference by investigating the sample complexity-the minimum number of reference samples required-for a successful attack. We study this question in the fundamental setting of Gaussian mean estimation where the learning algorithm is given $n$ samples from a Gaussian distribution $\mathcal{N}(\mu,\Sigma)$ in $d$ dimensions, and tries to estimate $\hat\mu$ up to some error $\mathbb{E}[\|\hat \mu - \mu\|^2_{\Sigma}]\leq \rho^2 d$. Our result shows that for membership inference in this setting, $\Omega(n + n^2 \rho^2)$ samples can be necessary to carry out any attack that competes with a fully informed attacker. Our result is the first to show that the attacker sometimes needs many more samples than the training algorithm uses to train the model. This result has significant implications for practice, as all attacks used in practice have a restricted form that uses $O(n)$ samples and cannot benefit from $\omega(n)$ samples. Thus, these attacks may be underestimating the possibility of membership inference, and better attacks may be possible when information about the distribution is easy to obtain.
Lower Bounds for Public-Private Learning under Distribution Shift
Jul 23, 2025The most effective differentially private machine learning algorithms in practice rely on an additional source of purportedly public data. This paradigm is most interesting when the two sources combine to be more than the sum of their parts. However, there are settings such as mean estimation where we have strong lower bounds, showing that when the two data sources have the same distribution, there is no complementary value to combining the two data sources. In this work we extend the known lower bounds for public-private learning to setting where the two data sources exhibit significant distribution shift. Our results apply to both Gaussian mean estimation where the two distributions have different means, and to Gaussian linear regression where the two distributions exhibit parameter shift. We find that when the shift is small (relative to the desired accuracy), either public or private data must be sufficiently abundant to estimate the private parameter. Conversely, when the shift is large, public data provides no benefit.
Privacy in Metalearning and Multitask Learning: Modeling and Separations
Dec 16, 2024Model personalization allows a set of individuals, each facing a different learning task, to train models that are more accurate for each person than those they could develop individually. The goals of personalization are captured in a variety of formal frameworks, such as multitask learning and metalearning. Combining data for model personalization poses risks for privacy because the output of an individual's model can depend on the data of other individuals. In this work we undertake a systematic study of differentially private personalized learning. Our first main contribution is to construct a taxonomy of formal frameworks for private personalized learning. This taxonomy captures different formal frameworks for learning as well as different threat models for the attacker. Our second main contribution is to prove separations between the personalized learning problems corresponding to different choices. In particular, we prove a novel separation between private multitask learning and private metalearning.
Private Geometric Median
Jun 11, 2024In this paper, we study differentially private (DP) algorithms for computing the geometric median (GM) of a dataset: Given $n$ points, $x_1,\dots,x_n$ in $\mathbb{R}^d$, the goal is to find a point $\theta$ that minimizes the sum of the Euclidean distances to these points, i.e., $\sum_{i=1}^{n} \|\theta - x_i\|_2$. Off-the-shelf methods, such as DP-GD, require strong a priori knowledge locating the data within a ball of radius $R$, and the excess risk of the algorithm depends linearly on $R$. In this paper, we ask: can we design an efficient and private algorithm with an excess error guarantee that scales with the (unknown) radius containing the majority of the datapoints? Our main contribution is a pair of polynomial-time DP algorithms for the task of private GM with an excess error guarantee that scales with the effective diameter of the datapoints. Additionally, we propose an inefficient algorithm based on the inverse smooth sensitivity mechanism, which satisfies the more restrictive notion of pure DP. We complement our results with a lower bound and demonstrate the optimality of our polynomial-time algorithms in terms of sample complexity.
Private Mean Estimation with Person-Level Differential Privacy
May 30, 2024We study differentially private (DP) mean estimation in the case where each person holds multiple samples. Commonly referred to as the "user-level" setting, DP here requires the usual notion of distributional stability when all of a person's datapoints can be modified. Informally, if $n$ people each have $m$ samples from an unknown $d$-dimensional distribution with bounded $k$-th moments, we show that \[n = \tilde \Theta\left(\frac{d}{\alpha^2 m} + \frac{d }{ \alpha m^{1/2} \varepsilon} + \frac{d}{\alpha^{k/(k-1)} m \varepsilon} + \frac{d}{\varepsilon}\right)\] people are necessary and sufficient to estimate the mean up to distance $\alpha$ in $\ell_2$-norm under $\varepsilon$-differential privacy (and its common relaxations). In the multivariate setting, we give computationally efficient algorithms under approximate DP (with slightly degraded sample complexity) and computationally inefficient algorithms under pure DP, and our nearly matching lower bounds hold for the most permissive case of approximate DP. Our computationally efficient estimators are based on the well known noisy-clipped-mean approach, but the analysis for our setting requires new bounds on the tails of sums of independent, vector-valued, bounded-moments random variables, and a new argument for bounding the bias introduced by clipping.
How to Make the Gradients Small Privately: Improved Rates for Differentially Private Non-Convex Optimization
Feb 17, 2024We provide a simple and flexible framework for designing differentially private algorithms to find approximate stationary points of non-convex loss functions. Our framework is based on using a private approximate risk minimizer to "warm start" another private algorithm for finding stationary points. We use this framework to obtain improved, and sometimes optimal, rates for several classes of non-convex loss functions. First, we obtain improved rates for finding stationary points of smooth non-convex empirical loss functions. Second, we specialize to quasar-convex functions, which generalize star-convex functions and arise in learning dynamical systems and training some neural nets. We achieve the optimal rate for this class. Third, we give an optimal algorithm for finding stationary points of functions satisfying the Kurdyka-Lojasiewicz (KL) condition. For example, over-parameterized neural networks often satisfy this condition. Fourth, we provide new state-of-the-art rates for stationary points of non-convex population loss functions. Fifth, we obtain improved rates for non-convex generalized linear models. A modification of our algorithm achieves nearly the same rates for second-order stationary points of functions with Lipschitz Hessian, improving over the previous state-of-the-art for each of the above problems.
Metalearning with Very Few Samples Per Task
Dec 21, 2023
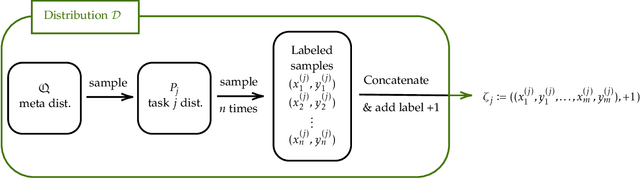
Metalearning and multitask learning are two frameworks for solving a group of related learning tasks more efficiently than we could hope to solve each of the individual tasks on their own. In multitask learning, we are given a fixed set of related learning tasks and need to output one accurate model per task, whereas in metalearning we are given tasks that are drawn i.i.d. from a metadistribution and need to output some common information that can be easily specialized to new, previously unseen tasks from the metadistribution. In this work, we consider a binary classification setting where tasks are related by a shared representation, that is, every task $P$ of interest can be solved by a classifier of the form $f_{P} \circ h$ where $h \in H$ is a map from features to some representation space that is shared across tasks, and $f_{P} \in F$ is a task-specific classifier from the representation space to labels. The main question we ask in this work is how much data do we need to metalearn a good representation? Here, the amount of data is measured in terms of both the number of tasks $t$ that we need to see and the number of samples $n$ per task. We focus on the regime where the number of samples per task is extremely small. Our main result shows that, in a distribution-free setting where the feature vectors are in $\mathbb{R}^d$, the representation is a linear map from $\mathbb{R}^d \to \mathbb{R}^k$, and the task-specific classifiers are halfspaces in $\mathbb{R}^k$, we can metalearn a representation with error $\varepsilon$ using just $n = k+2$ samples per task, and $d \cdot (1/\varepsilon)^{O(k)}$ tasks. Learning with so few samples per task is remarkable because metalearning would be impossible with $k+1$ samples per task, and because we cannot even hope to learn an accurate task-specific classifier with just $k+2$ samples per task.
Chameleon: Increasing Label-Only Membership Leakage with Adaptive Poisoning
Oct 05, 2023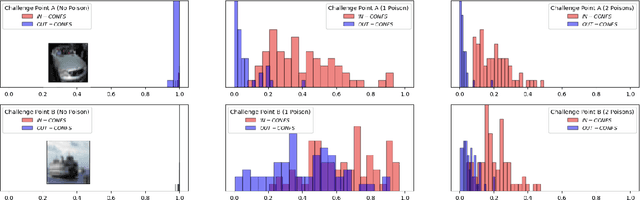

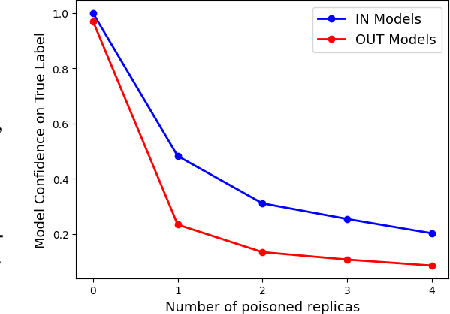

The integration of machine learning (ML) in numerous critical applications introduces a range of privacy concerns for individuals who provide their datasets for model training. One such privacy risk is Membership Inference (MI), in which an attacker seeks to determine whether a particular data sample was included in the training dataset of a model. Current state-of-the-art MI attacks capitalize on access to the model's predicted confidence scores to successfully perform membership inference, and employ data poisoning to further enhance their effectiveness. In this work, we focus on the less explored and more realistic label-only setting, where the model provides only the predicted label on a queried sample. We show that existing label-only MI attacks are ineffective at inferring membership in the low False Positive Rate (FPR) regime. To address this challenge, we propose a new attack Chameleon that leverages a novel adaptive data poisoning strategy and an efficient query selection method to achieve significantly more accurate membership inference than existing label-only attacks, especially at low FPRs.
Smooth Lower Bounds for Differentially Private Algorithms via Padding-and-Permuting Fingerprinting Codes
Jul 14, 2023Fingerprinting arguments, first introduced by Bun, Ullman, and Vadhan (STOC 2014), are the most widely used method for establishing lower bounds on the sample complexity or error of approximately differentially private (DP) algorithms. Still, there are many problems in differential privacy for which we don't know suitable lower bounds, and even for problems that we do, the lower bounds are not smooth, and usually become vacuous when the error is larger than some threshold. In this work, we present a simple method to generate hard instances by applying a padding-and-permuting transformation to a fingerprinting code. We illustrate the applicability of this method by providing new lower bounds in various settings: 1. A tight lower bound for DP averaging in the low-accuracy regime, which in particular implies a new lower bound for the private 1-cluster problem introduced by Nissim, Stemmer, and Vadhan (PODS 2016). 2. A lower bound on the additive error of DP algorithms for approximate k-means clustering, as a function of the multiplicative error, which is tight for a constant multiplication error. 3. A lower bound for estimating the top singular vector of a matrix under DP in low-accuracy regimes, which is a special case of DP subspace estimation studied by Singhal and Steinke (NeurIPS 2021). Our main technique is to apply a padding-and-permuting transformation to a fingerprinting code. However, rather than proving our results using a black-box access to an existing fingerprinting code (e.g., Tardos' code), we develop a new fingerprinting lemma that is stronger than those of Dwork et al. (FOCS 2015) and Bun et al. (SODA 2017), and prove our lower bounds directly from the lemma. Our lemma, in particular, gives a simpler fingerprinting code construction with optimal rate (up to polylogarithmic factors) that is of independent interest.
TMI! Finetuned Models Leak Private Information from their Pretraining Data
Jun 01, 2023Transfer learning has become an increasingly popular technique in machine learning as a way to leverage a pretrained model trained for one task to assist with building a finetuned model for a related task. This paradigm has been especially popular for privacy in machine learning, where the pretrained model is considered public, and only the data for finetuning is considered sensitive. However, there are reasons to believe that the data used for pretraining is still sensitive, making it essential to understand how much information the finetuned model leaks about the pretraining data. In this work we propose a new membership-inference threat model where the adversary only has access to the finetuned model and would like to infer the membership of the pretraining data. To realize this threat model, we implement a novel metaclassifier-based attack, TMI, that leverages the influence of memorized pretraining samples on predictions in the downstream task. We evaluate TMI on both vision and natural language tasks across multiple transfer learning settings, including finetuning with differential privacy. Through our evaluation, we find that TMI can successfully infer membership of pretraining examples using query access to the finetuned model.