 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-Optimal Pure Machine Unlearning for Smooth Strongly Convex Losses
Jun 01, 2026Machine unlearning is motivated by legal and user-facing requirements to remove the influence of individuals' data from trained models, such as the right to be forgotten. Prior work has developed algorithms and error bounds for unlearning in smooth strongly convex stochastic optimization, but the fundamental statistical cost of unlearning has remained unclear. We nearly resolve this problem by proving upper and lower bounds on the excess population risk of approximate $\varepsilon$-unlearning; our bounds are tight up to a condition-number factor. For mean estimation over the unit ball, our upper and lower bounds match. The optimal rate is the usual statistical error plus an unlearning penalty that interpolates between the retraining-from-scratch rate and an exponentially smaller term as $\varepsilon/d$ grows, where $d$ is the dimension of the model. In particular, when $\varepsilon \gg d$, our $\varepsilon$-unlearning algorithm offers an exponential accuracy improvement over retraining the model from scratch and differentially private baselines. On the other hand, when $\varepsilon \le d$, retraining from scratch is optimal.
Optimal Rates for Pure {\varepsilon}-Differentially Private Stochastic Convex Optimization with Heavy Tails
Apr 07, 2026We study stochastic convex optimization (SCO) with heavy-tailed gradients under pure epsilon-differential privacy (DP). Instead of assuming a bound on the worst-case Lipschitz parameter of the loss, we assume only a bounded k-th moment. This assumption allows for unbounded, heavy-tailed stochastic gradient distributions, and can yield sharper excess risk bounds. The minimax optimal rate for approximate (epsilon, delta)-DP SCO is known in this setting, but the pure epsilon-DP case has remained open. We characterize the minimax optimal excess-risk rate for pure epsilon-DP heavy-tailed SCO up to logarithmic factors. Our algorithm achieves this rate in polynomial time with high probability. Moreover, it runs in polynomial time with probability 1 when the worst-case Lipschitz parameter is polynomially bounded. For important structured problem classes - including hinge/ReLU-type and absolute-value losses on Euclidean balls, ellipsoids, and polytopes - we achieve the same excess-risk guarantee in polynomial time with probability 1 even when the worst-case Lipschitz parameter is infinite. Our approach is based on a novel framework for privately optimizing Lipschitz extensions of the empirical loss. We complement our excess risk upper bound with a novel high probability lower bound.
Optimal Rates for Robust Stochastic Convex Optimization
Dec 15, 2024The sensitivity of machine learning algorithms to outliers, particularly in high-dimensional spaces, necessitates the development of robust methods. Within the framework of $\epsilon$-contamination model, where the adversary can inspect and replace up to $\epsilon$ fraction of the samples, a fundamental open question is determining the optimal rates for robust stochastic convex optimization (robust SCO), provided the samples under $\epsilon$-contamination. We develop novel algorithms that achieve minimax-optimal excess risk (up to logarithmic factors) under the $\epsilon$-contamination model. Our approach advances beyonds existing algorithms, which are not only suboptimal but also constrained by stringent requirements, including Lipschitzness and smoothness conditions on sample functions.Our algorithms achieve optimal rates while removing these restrictive assumptions, and notably, remain effective for nonsmooth but Lipschitz population risks.
A Stochastic Optimization Framework for Private and Fair Learning From Decentralized Data
Nov 12, 2024



Machine learning models are often trained on sensitive data (e.g., medical records and race/gender) that is distributed across different "silos" (e.g., hospitals). These federated learning models may then be used to make consequential decisions, such as allocating healthcare resources. Two key challenges emerge in this setting: (i) maintaining the privacy of each person's data, even if other silos or an adversary with access to the central server tries to infer this data; (ii) ensuring that decisions are fair to different demographic groups (e.g., race/gender). In this paper, we develop a novel algorithm for private and fair federated learning (FL). Our algorithm satisfies inter-silo record-level differential privacy (ISRL-DP), a strong notion of private FL requiring that silo i's sent messages satisfy record-level differential privacy for all i. Our framework can be used to promote different fairness notions, including demographic parity and equalized odds. We prove that our algorithm converges under mild smoothness assumptions on the loss function, whereas prior work required strong convexity for convergence. As a byproduct of our analysis, we obtain the first convergence guarantee for ISRL-DP nonconvex-strongly concave min-max FL. Experiments demonstrate the state-of-the-art fairness-accuracy tradeoffs of our algorithm across different privacy levels.
Faster Algorithms for User-Level Private Stochastic Convex Optimization
Oct 24, 2024
We study private stochastic convex optimization (SCO) under user-level differential privacy (DP) constraints. In this setting, there are $n$ users (e.g., cell phones), each possessing $m$ data items (e.g., text messages), and we need to protect the privacy of each user's entire collection of data items. Existing algorithms for user-level DP SCO are impractical in many large-scale machine learning scenarios because: (i) they make restrictive assumptions on the smoothness parameter of the loss function and require the number of users to grow polynomially with the dimension of the parameter space; or (ii) they are prohibitively slow, requiring at least $(mn)^{3/2}$ gradient computations for smooth losses and $(mn)^3$ computations for non-smooth losses. To address these limitations, we provide novel user-level DP algorithms with state-of-the-art excess risk and runtime guarantees, without stringent assumptions. First, we develop a linear-time algorithm with state-of-the-art excess risk (for a non-trivial linear-time algorithm) under a mild smoothness assumption. Our second algorithm applies to arbitrary smooth losses and achieves optimal excess risk in $\approx (mn)^{9/8}$ gradient computations. Third, for non-smooth loss functions, we obtain optimal excess risk in $n^{11/8} m^{5/4}$ gradient computations. Moreover, our algorithms do not require the number of users to grow polynomially with the dimension.
Exploring User-level Gradient Inversion with a Diffusion Prior
Sep 11, 2024



We explore user-level gradient inversion as a new attack surface in distributed learning. We first investigate existing attacks on their ability to make inferences about private information beyond training data reconstruction. Motivated by the low reconstruction quality of existing methods, we propose a novel gradient inversion attack that applies a denoising diffusion model as a strong image prior in order to enhance recovery in the large batch setting. Unlike traditional attacks, which aim to reconstruct individual samples and suffer at large batch and image sizes, our approach instead aims to recover a representative image that captures the sensitive shared semantic information corresponding to the underlying user. Our experiments with face images demonstrate the ability of our methods to recover realistic facial images along with private user attributes.
Analyzing Inference Privacy Risks Through Gradients in Machine Learning
Aug 29, 2024



In distributed learning settings, models are iteratively updated with shared gradients computed from potentially sensitive user data. While previous work has studied various privacy risks of sharing gradients, our paper aims to provide a systematic approach to analyze private information leakage from gradients. We present a unified game-based framework that encompasses a broad range of attacks including attribute, property, distributional, and user disclosures. We investigate how different uncertainties of the adversary affect their inferential power via extensive experiments on five datasets across various data modalities. Our results demonstrate the inefficacy of solely relying on data aggregation to achieve privacy against inference attacks in distributed learning. We further evaluate five types of defenses, namely, gradient pruning, signed gradient descent, adversarial perturbations, variational information bottleneck, and differential privacy, under both static and adaptive adversary settings. We provide an information-theoretic view for analyzing the effectiveness of these defenses against inference from gradients. Finally, we introduce a method for auditing attribute inference privacy, improving the empirical estimation of worst-case privacy through crafting adversarial canary records.
Private Heterogeneous Federated Learning Without a Trusted Server Revisited: Error-Optimal and Communication-Efficient Algorithms for Convex Losses
Jul 12, 2024We revisit the problem of federated learning (FL) with private data from people who do not trust the server or other silos/clients. In this context, every silo (e.g. hospital) has data from several people (e.g. patients) and needs to protect the privacy of each person's data (e.g. health records), even if the server and/or other silos try to uncover this data. Inter-Silo Record-Level Differential Privacy (ISRL-DP) prevents each silo's data from being leaked, by requiring that silo i's communications satisfy item-level differential privacy. Prior work arXiv:2203.06735 characterized the optimal excess risk bounds for ISRL-DP algorithms with homogeneous (i.i.d.) silo data and convex loss functions. However, two important questions were left open: (1) Can the same excess risk bounds be achieved with heterogeneous (non-i.i.d.) silo data? (2) Can the optimal risk bounds be achieved with fewer communication rounds? In this paper, we give positive answers to both questions. We provide novel ISRL-DP FL algorithms that achieve the optimal excess risk bounds in the presence of heterogeneous silo data. Moreover, our algorithms are more communication-efficient than the prior state-of-the-art. For smooth loss functions, our algorithm achieves the optimal excess risk bound and has communication complexity that matches the non-private lower bound. Additionally, our algorithms are more computationally efficient than the previous state-of-the-art.
Efficient Differentially Private Fine-Tuning of Diffusion Models
Jun 07, 2024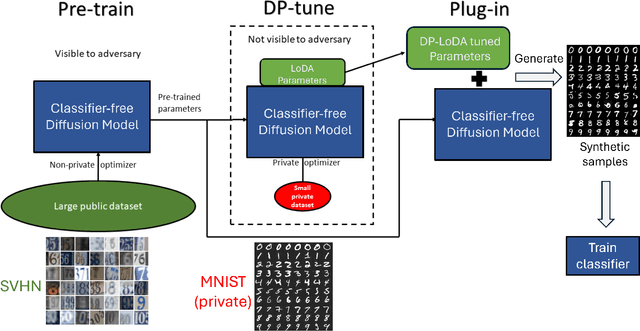
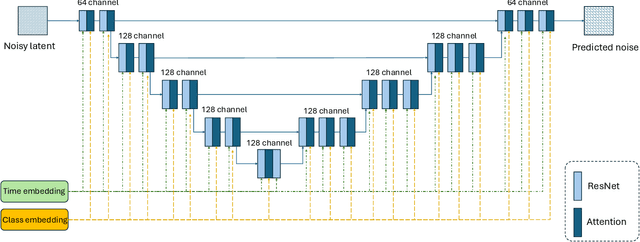
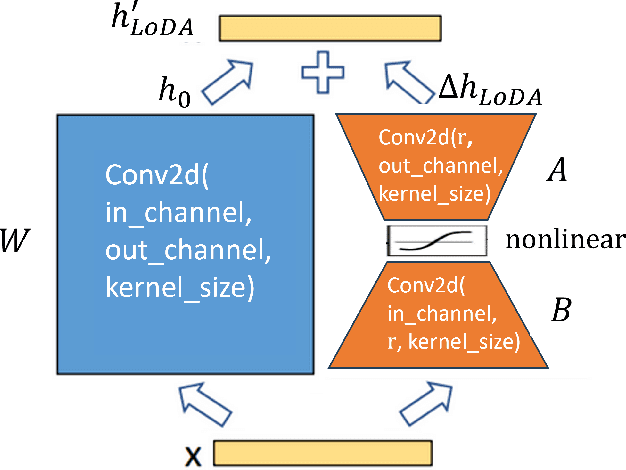

The recent developments of Diffusion Models (DMs) enable generation of astonishingly high-quality synthetic samples. Recent work showed that the synthetic samples generated by the diffusion model, which is pre-trained on public data and fully fine-tuned with differential privacy on private data, can train a downstream classifier, while achieving a good privacy-utility tradeoff. However, fully fine-tuning such large diffusion models with DP-SGD can be very resource-demanding in terms of memory usage and computation. In this work, we investigate Parameter-Efficient Fine-Tuning (PEFT) of diffusion models using Low-Dimensional Adaptation (LoDA) with Differential Privacy. We evaluate the proposed method with the MNIST and CIFAR-10 datasets and demonstrate that such efficient fine-tuning can also generate useful synthetic samples for training downstream classifiers, with guaranteed privacy protection of fine-tuning data. Our source code will be made available on GitHub.
How to Make the Gradients Small Privately: Improved Rates for Differentially Private Non-Convex Optimization
Feb 17, 2024We provide a simple and flexible framework for designing differentially private algorithms to find approximate stationary points of non-convex loss functions. Our framework is based on using a private approximate risk minimizer to "warm start" another private algorithm for finding stationary points. We use this framework to obtain improved, and sometimes optimal, rates for several classes of non-convex loss functions. First, we obtain improved rates for finding stationary points of smooth non-convex empirical loss functions. Second, we specialize to quasar-convex functions, which generalize star-convex functions and arise in learning dynamical systems and training some neural nets. We achieve the optimal rate for this class. Third, we give an optimal algorithm for finding stationary points of functions satisfying the Kurdyka-Lojasiewicz (KL) condition. For example, over-parameterized neural networks often satisfy this condition. Fourth, we provide new state-of-the-art rates for stationary points of non-convex population loss functions. Fifth, we obtain improved rates for non-convex generalized linear models. A modification of our algorithm achieves nearly the same rates for second-order stationary points of functions with Lipschitz Hessian, improving over the previous state-of-the-art for each of the above problems.