 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadOT-Eval: Auditable Structured-Evidence Transport for Radiology Report Evaluation
Jun 07, 2026Automatic evaluation is critical for high-stakes text generation, where errors often involve omitted findings, hallucinated content, polarity reversals, location changes, uncertainty mismatches, and temporal-comparison errors rather than low surface similarity alone. Radiology report generation provides a challenging test case because generated reports must preserve structured clinical evidence across sources. We present RadOT-Eval, an interpretable structured-evidence optimal transport framework for offline auditing of radiology report generation. RadOT-Eval decomposes reference and candidate reports into attribute-structured clinical evidence units, aligns corresponding evidence using entropy-regularized optimal transport, and uses clinically meaningful side-channel discrepancies in a monotone risk model to predict error burden. All transport, feature, and readout choices are selected using the ReXVal dataset, and the frozen system is evaluated on the independent RadEvalX dataset. RadOT-Eval achieves Spearman correlations of 0.715, 0.548, and 0.399 with total, clinically significant, and clinically insignificant annotated error burden, respectively, yielding higher point estimates than standard evaluation metrics and the open-source large language model (LLM)-based evaluator GREEN-radllama2-7B. In a frozen auxiliary corruption-sensitivity stress test on ReXErr-v1, RadOT-Eval achieves 0.768 AUROC and a 0.990 corrupted-greater-than-clean paired win rate. These results show that structured evidence transport provides an auditable, rank-oriented evaluation tool for high-stakes generated clinical text under ReXVal-only model selection and frozen RadEvalX testing.
Robust Nasality Representation Learning for Cleft Palate-Related Velopharyngeal Dysfunction Screening in Real-World Settings
Mar 18, 2026Velopharyngeal dysfunction (VPD) is characterized by inadequate velopharyngeal closure during speech and often causes hypernasality and reduced intelligibility. Although speech-based machine learning models can perform well under standardized clinical recording conditions, their performance often drops in real-world settings because of domain shift caused by differences in devices, channels, noise, and room acoustics. To improve robustness, we propose a two-stage framework for VPD screening. First, a nasality-focused speech representation is learned by supervised contrastive pre-training on an auxiliary corpus with phoneme alignments, using oral-context versus nasal-context supervision. Second, the encoder is frozen and used with lightweight classifiers on 0.5-second speech chunks, whose probabilities are aggregated to produce recording-level decisions with a fixed threshold. On an in-domain clinical cohort of 82 subjects, the proposed method achieved perfect recording-level screening performance (macro-F1 = 1.000, accuracy = 1.000). On a separate out-of-domain set of 131 heterogeneous public Internet recordings, large pretrained speech representations degraded substantially, while MFCC was the strongest baseline (macro-F1 = 0.612, accuracy = 0.641). The proposed method achieved the best out-of-domain performance (macro-F1 = 0.679, accuracy = 0.695), improving on the strongest baseline under the same evaluation protocol. These results suggest that learning a nasality-focused representation before clinical classification can reduce sensitivity to recording artifacts and improve robustness for deployable speech-based VPD screening.
Optimizing Domain-Adaptive Self-Supervised Learning for Clinical Voice-Based Disease Classification
Jan 29, 2026The human voice is a promising non-invasive digital biomarker, yet deep learning for voice-based health analysis is hindered by data scarcity and domain mismatch, where models pre-trained on general audio fail to capture the subtle pathological features characteristic of clinical voice data. To address these challenges, we investigate domain-adaptive self-supervised learning (SSL) with Masked Autoencoders (MAE) and demonstrate that standard configurations are suboptimal for health-related audio. Using the Bridge2AI-Voice dataset, a multi-institutional collection of pathological voices, we systematically examine three performance-critical factors: reconstruction loss (Mean Absolute Error vs. Mean Squared Error), normalization (patch-wise vs. global), and masking (random vs. content-aware). Our optimized design, which combines Mean Absolute Error (MA-Error) loss, patch-wise normalization, and content-aware masking, achieves a Macro F1 of $0.688 \pm 0.009$ (over 10 fine-tuning runs), outperforming a strong out-of-domain SSL baseline pre-trained on large-scale general audio, which has a Macro F1 of $0.663 \pm 0.011$. The results show that MA-Error loss improves robustness and content-aware masking boosts performance by emphasizing information-rich regions. These findings highlight the importance of component-level optimization in data-constrained medical applications that rely on audio data.
From Passive Metric to Active Signal: The Evolving Role of Uncertainty Quantification in Large Language Models
Jan 22, 2026While Large Language Models (LLMs) show remarkable capabilities, their unreliability remains a critical barrier to deployment in high-stakes domains. This survey charts a functional evolution in addressing this challenge: the evolution of uncertainty from a passive diagnostic metric to an active control signal guiding real-time model behavior. We demonstrate how uncertainty is leveraged as an active control signal across three frontiers: in \textbf{advanced reasoning} to optimize computation and trigger self-correction; in \textbf{autonomous agents} to govern metacognitive decisions about tool use and information seeking; and in \textbf{reinforcement learning} to mitigate reward hacking and enable self-improvement via intrinsic rewards. By grounding these advancements in emerging theoretical frameworks like Bayesian methods and Conformal Prediction, we provide a unified perspective on this transformative trend. This survey provides a comprehensive overview, critical analysis, and practical design patterns, arguing that mastering the new trend of uncertainty is essential for building the next generation of scalable, reliable, and trustworthy AI.
A Consensus Privacy Metrics Framework for Synthetic Data
Mar 06, 2025Synthetic data generation is one approach for sharing individual-level data. However, to meet legislative requirements, it is necessary to demonstrate that the individuals' privacy is adequately protected. There is no consolidated standard for measuring privacy in synthetic data. Through an expert panel and consensus process, we developed a framework for evaluating privacy in synthetic data. Our findings indicate that current similarity metrics fail to measure identity disclosure, and their use is discouraged. For differentially private synthetic data, a privacy budget other than close to zero was not considered interpretable. There was consensus on the importance of membership and attribute disclosure, both of which involve inferring personal information about an individual without necessarily revealing their identity. The resultant framework provides precise recommendations for metrics that address these types of disclosures effectively. Our findings further present specific opportunities for future research that can help with widespread adoption of synthetic data.
Scale-up Unlearnable Examples Learning with High-Performance Computing
Jan 10, 2025
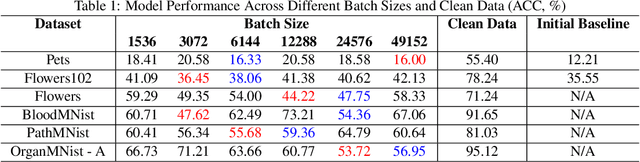
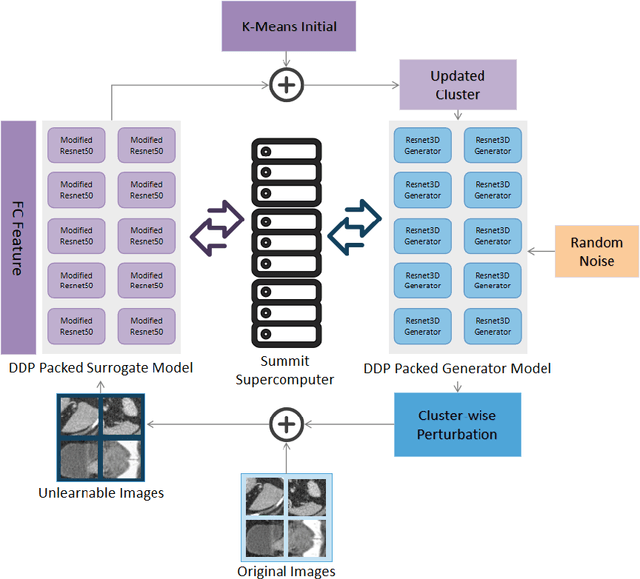
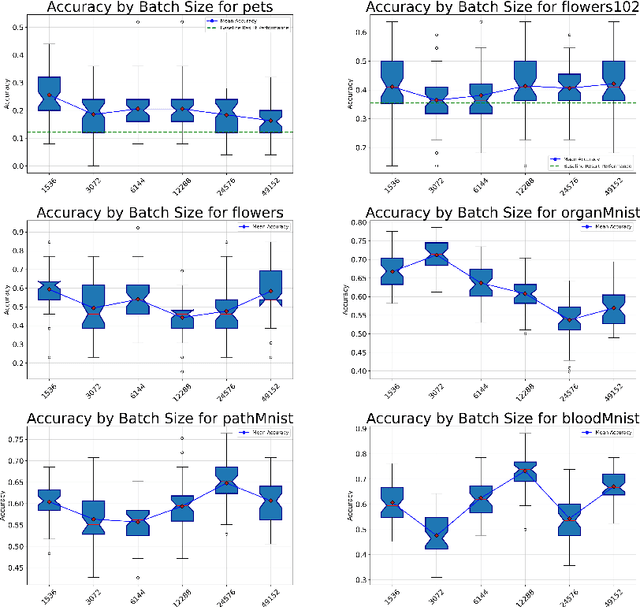
Recent advancements in AI models are structured to retain user interactions, which could inadvertently include sensitive healthcare data. In the healthcare field, particularly when radiologists use AI-driven diagnostic tools hosted on online platforms, there is a risk that medical imaging data may be repurposed for future AI training without explicit consent, spotlighting critical privacy and intellectual property concerns around healthcare data usage. Addressing these privacy challenges, a novel approach known as Unlearnable Examples (UEs) has been introduced, aiming to make data unlearnable to deep learning models. A prominent method within this area, called Unlearnable Clustering (UC), has shown improved UE performance with larger batch sizes but was previously limited by computational resources. To push the boundaries of UE performance with theoretically unlimited resources, we scaled up UC learning across various datasets using Distributed Data Parallel (DDP) training on the Summit supercomputer. Our goal was to examine UE efficacy at high-performance computing (HPC) levels to prevent unauthorized learning and enhance data security, particularly exploring the impact of batch size on UE's unlearnability. Utilizing the robust computational capabilities of the Summit, extensive experiments were conducted on diverse datasets such as Pets, MedMNist, Flowers, and Flowers102. Our findings reveal that both overly large and overly small batch sizes can lead to performance instability and affect accuracy. However, the relationship between batch size and unlearnability varied across datasets, highlighting the necessity for tailored batch size strategies to achieve optimal data protection. Our results underscore the critical role of selecting appropriate batch sizes based on the specific characteristics of each dataset to prevent learning and ensure data security in deep learning applications.
Exploring User-level Gradient Inversion with a Diffusion Prior
Sep 11, 2024



We explore user-level gradient inversion as a new attack surface in distributed learning. We first investigate existing attacks on their ability to make inferences about private information beyond training data reconstruction. Motivated by the low reconstruction quality of existing methods, we propose a novel gradient inversion attack that applies a denoising diffusion model as a strong image prior in order to enhance recovery in the large batch setting. Unlike traditional attacks, which aim to reconstruct individual samples and suffer at large batch and image sizes, our approach instead aims to recover a representative image that captures the sensitive shared semantic information corresponding to the underlying user. Our experiments with face images demonstrate the ability of our methods to recover realistic facial images along with private user attributes.
Analyzing Inference Privacy Risks Through Gradients in Machine Learning
Aug 29, 2024



In distributed learning settings, models are iteratively updated with shared gradients computed from potentially sensitive user data. While previous work has studied various privacy risks of sharing gradients, our paper aims to provide a systematic approach to analyze private information leakage from gradients. We present a unified game-based framework that encompasses a broad range of attacks including attribute, property, distributional, and user disclosures. We investigate how different uncertainties of the adversary affect their inferential power via extensive experiments on five datasets across various data modalities. Our results demonstrate the inefficacy of solely relying on data aggregation to achieve privacy against inference attacks in distributed learning. We further evaluate five types of defenses, namely, gradient pruning, signed gradient descent, adversarial perturbations, variational information bottleneck, and differential privacy, under both static and adaptive adversary settings. We provide an information-theoretic view for analyzing the effectiveness of these defenses against inference from gradients. Finally, we introduce a method for auditing attribute inference privacy, improving the empirical estimation of worst-case privacy through crafting adversarial canary records.
Adaptive Recruitment Resource Allocation to Improve Cohort Representativeness in Participatory Biomedical Datasets
Aug 02, 2024Large participatory biomedical studies, studies that recruit individuals to join a dataset, are gaining popularity and investment, especially for analysis by modern AI methods. Because they purposively recruit participants, these studies are uniquely able to address a lack of historical representation, an issue that has affected many biomedical datasets. In this work, we define representativeness as the similarity to a target population distribution of a set of attributes and our goal is to mirror the U.S. population across distributions of age, gender, race, and ethnicity. Many participatory studies recruit at several institutions, so we introduce a computational approach to adaptively allocate recruitment resources among sites to improve representativeness. In simulated recruitment of 10,000-participant cohorts from medical centers in the STAR Clinical Research Network, we show that our approach yields a more representative cohort than existing baselines. Thus, we highlight the value of computational modeling in guiding recruitment efforts.
Dataset Representativeness and Downstream Task Fairness
Jun 28, 2024



Our society collects data on people for a wide range of applications, from building a census for policy evaluation to running meaningful clinical trials. To collect data, we typically sample individuals with the goal of accurately representing a population of interest. However, current sampling processes often collect data opportunistically from data sources, which can lead to datasets that are biased and not representative, i.e., the collected dataset does not accurately reflect the distribution of demographics of the true population. This is a concern because subgroups within the population can be under- or over-represented in a dataset, which may harm generalizability and lead to an unequal distribution of benefits and harms from downstream tasks that use such datasets (e.g., algorithmic bias in medical decision-making algorithms). In this paper, we assess the relationship between dataset representativeness and group-fairness of classifiers trained on that dataset. We demonstrate that there is a natural tension between dataset representativeness and classifier fairness; empirically we observe that training datasets with better representativeness can frequently result in classifiers with higher rates of unfairness. We provide some intuition as to why this occurs via a set of theoretical results in the case of univariate classifiers. We also find that over-sampling underrepresented groups can result in classifiers which exhibit greater bias to those groups. Lastly, we observe that fairness-aware sampling strategies (i.e., those which are specifically designed to select data with high downstream fairness) will often over-sample members of majority groups. These results demonstrate that the relationship between dataset representativeness and downstream classifier fairness is complex; balancing these two quantities requires special care from both model- and dataset-designers.