 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformal Reachability for Safe Control in Unknown Environments
Feb 03, 2026Designing provably safe control is a core problem in trustworthy autonomy. However, most prior work in this regard assumes either that the system dynamics are known or deterministic, or that the state and action space are finite, significantly limiting application scope. We address this limitation by developing a probabilistic verification framework for unknown dynamical systems which combines conformal prediction with reachability analysis. In particular, we use conformal prediction to obtain valid uncertainty intervals for the unknown dynamics at each time step, with reachability then verifying whether safety is maintained within the conformal uncertainty bounds. Next, we develop an algorithmic approach for training control policies that optimize nominal reward while also maximizing the planning horizon with sound probabilistic safety guarantees. We evaluate the proposed approach in seven safe control settings spanning four domains -- cartpole, lane following, drone control, and safe navigation -- for both affine and nonlinear safety specifications. Our experiments show that the policies we learn achieve the strongest provable safety guarantees while still maintaining high average reward.
CoFineLLM: Conformal Finetuning of LLMs for Language-Instructed Robot Planning
Nov 09, 2025



Large Language Models (LLMs) have recently emerged as planners for language-instructed agents, generating sequences of actions to accomplish natural language tasks. However, their reliability remains a challenge, especially in long-horizon tasks, since they often produce overconfident yet wrong outputs. Conformal Prediction (CP) has been leveraged to address this issue by wrapping LLM outputs into prediction sets that contain the correct action with a user-defined confidence. When the prediction set is a singleton, the planner executes that action; otherwise, it requests help from a user. This has led to LLM-based planners that can ensure plan correctness with a user-defined probability. However, as LLMs are trained in an uncertainty-agnostic manner, without awareness of prediction sets, they tend to produce unnecessarily large sets, particularly at higher confidence levels, resulting in frequent human interventions limiting autonomous deployment. To address this, we introduce CoFineLLM (Conformal Finetuning for LLMs), the first CP-aware finetuning framework for LLM-based planners that explicitly reduces prediction-set size and, in turn, the need for user interventions. We evaluate our approach on multiple language-instructed robot planning problems and show consistent improvements over uncertainty-aware and uncertainty-agnostic finetuning baselines in terms of prediction-set size, and help rates. Finally, we demonstrate robustness of our method to out-of-distribution scenarios in hardware experiments.
Online Feedback Efficient Active Target Discovery in Partially Observable Environments
May 10, 2025In various scientific and engineering domains, where data acquisition is costly, such as in medical imaging, environmental monitoring, or remote sensing, strategic sampling from unobserved regions, guided by prior observations, is essential to maximize target discovery within a limited sampling budget. In this work, we introduce Diffusion-guided Active Target Discovery (DiffATD), a novel method that leverages diffusion dynamics for active target discovery. DiffATD maintains a belief distribution over each unobserved state in the environment, using this distribution to dynamically balance exploration-exploitation. Exploration reduces uncertainty by sampling regions with the highest expected entropy, while exploitation targets areas with the highest likelihood of discovering the target, indicated by the belief distribution and an incrementally trained reward model designed to learn the characteristics of the target. DiffATD enables efficient target discovery in a partially observable environment within a fixed sampling budget, all without relying on any prior supervised training. Furthermore, DiffATD offers interpretability, unlike existing black-box policies that require extensive supervised training. Through extensive experiments and ablation studies across diverse domains, including medical imaging and remote sensing, we show that DiffATD performs significantly better than baselines and competitively with supervised methods that operate under full environmental observability.
To Give or Not to Give? The Impacts of Strategically Withheld Recourse
Apr 08, 2025Individuals often aim to reverse undesired outcomes in interactions with automated systems, like loan denials, by either implementing system-recommended actions (recourse), or manipulating their features. While providing recourse benefits users and enhances system utility, it also provides information about the decision process that can be used for more effective strategic manipulation, especially when the individuals collectively share such information with each other. We show that this tension leads rational utility-maximizing systems to frequently withhold recourse, resulting in decreased population utility, particularly impacting sensitive groups. To mitigate these effects, we explore the role of recourse subsidies, finding them effective in increasing the provision of recourse actions by rational systems, as well as lowering the potential social cost and mitigating unfairness caused by recourse withholding.
Active Geospatial Search for Efficient Tenant Eviction Outreach
Dec 19, 2024Tenant evictions threaten housing stability and are a major concern for many cities. An open question concerns whether data-driven methods enhance outreach programs that target at-risk tenants to mitigate their risk of eviction. We propose a novel active geospatial search (AGS) modeling framework for this problem. AGS integrates property-level information in a search policy that identifies a sequence of rental units to canvas to both determine their eviction risk and provide support if needed. We propose a hierarchical reinforcement learning approach to learn a search policy for AGS that scales to large urban areas containing thousands of parcels, balancing exploration and exploitation and accounting for travel costs and a budget constraint. Crucially, the search policy adapts online to newly discovered information about evictions. Evaluation using eviction data for a large urban area demonstrates that the proposed framework and algorithmic approach are considerably more effective at sequentially identifying eviction cases than baseline methods.
AutoDAN-Turbo: A Lifelong Agent for Strategy Self-Exploration to Jailbreak LLMs
Oct 14, 2024



In this paper, we propose AutoDAN-Turbo, a black-box jailbreak method that can automatically discover as many jailbreak strategies as possible from scratch, without any human intervention or predefined scopes (e.g., specified candidate strategies), and use them for red-teaming. As a result, AutoDAN-Turbo can significantly outperform baseline methods, achieving a 74.3% higher average attack success rate on public benchmarks. Notably, AutoDAN-Turbo achieves an 88.5 attack success rate on GPT-4-1106-turbo. In addition, AutoDAN-Turbo is a unified framework that can incorporate existing human-designed jailbreak strategies in a plug-and-play manner. By integrating human-designed strategies, AutoDAN-Turbo can even achieve a higher attack success rate of 93.4 on GPT-4-1106-turbo.
Adaptive Recruitment Resource Allocation to Improve Cohort Representativeness in Participatory Biomedical Datasets
Aug 02, 2024Large participatory biomedical studies, studies that recruit individuals to join a dataset, are gaining popularity and investment, especially for analysis by modern AI methods. Because they purposively recruit participants, these studies are uniquely able to address a lack of historical representation, an issue that has affected many biomedical datasets. In this work, we define representativeness as the similarity to a target population distribution of a set of attributes and our goal is to mirror the U.S. population across distributions of age, gender, race, and ethnicity. Many participatory studies recruit at several institutions, so we introduce a computational approach to adaptively allocate recruitment resources among sites to improve representativeness. In simulated recruitment of 10,000-participant cohorts from medical centers in the STAR Clinical Research Network, we show that our approach yields a more representative cohort than existing baselines. Thus, we highlight the value of computational modeling in guiding recruitment efforts.
Dataset Representativeness and Downstream Task Fairness
Jun 28, 2024



Our society collects data on people for a wide range of applications, from building a census for policy evaluation to running meaningful clinical trials. To collect data, we typically sample individuals with the goal of accurately representing a population of interest. However, current sampling processes often collect data opportunistically from data sources, which can lead to datasets that are biased and not representative, i.e., the collected dataset does not accurately reflect the distribution of demographics of the true population. This is a concern because subgroups within the population can be under- or over-represented in a dataset, which may harm generalizability and lead to an unequal distribution of benefits and harms from downstream tasks that use such datasets (e.g., algorithmic bias in medical decision-making algorithms). In this paper, we assess the relationship between dataset representativeness and group-fairness of classifiers trained on that dataset. We demonstrate that there is a natural tension between dataset representativeness and classifier fairness; empirically we observe that training datasets with better representativeness can frequently result in classifiers with higher rates of unfairness. We provide some intuition as to why this occurs via a set of theoretical results in the case of univariate classifiers. We also find that over-sampling underrepresented groups can result in classifiers which exhibit greater bias to those groups. Lastly, we observe that fairness-aware sampling strategies (i.e., those which are specifically designed to select data with high downstream fairness) will often over-sample members of majority groups. These results demonstrate that the relationship between dataset representativeness and downstream classifier fairness is complex; balancing these two quantities requires special care from both model- and dataset-designers.
Adversarial Machine Unlearning
Jun 11, 2024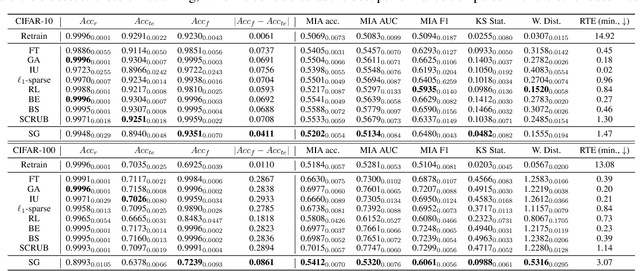
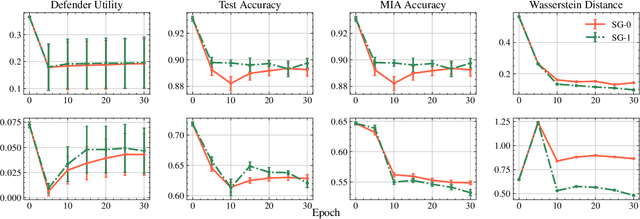
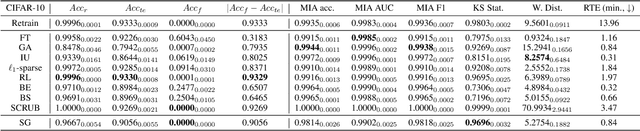
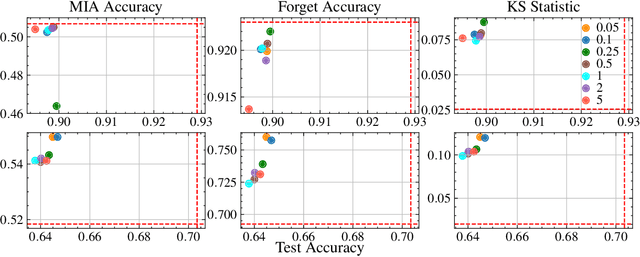
This paper focuses on the challenge of machine unlearning, aiming to remove the influence of specific training data on machine learning models. Traditionally, the development of unlearning algorithms runs parallel with that of membership inference attacks (MIA), a type of privacy threat to determine whether a data instance was used for training. However, the two strands are intimately connected: one can view machine unlearning through the lens of MIA success with respect to removed data. Recognizing this connection, we propose a game-theoretic framework that integrates MIAs into the design of unlearning algorithms. Specifically, we model the unlearning problem as a Stackelberg game in which an unlearner strives to unlearn specific training data from a model, while an auditor employs MIAs to detect the traces of the ostensibly removed data. Adopting this adversarial perspective allows the utilization of new attack advancements, facilitating the design of unlearning algorithms. Our framework stands out in two ways. First, it takes an adversarial approach and proactively incorporates the attacks into the design of unlearning algorithms. Secondly, it uses implicit differentiation to obtain the gradients that limit the attacker's success, thus benefiting the process of unlearning. We present empirical results to demonstrate the effectiveness of the proposed approach for machine unlearning.
GOMAA-Geo: GOal Modality Agnostic Active Geo-localization
Jun 04, 2024



We consider the task of active geo-localization (AGL) in which an agent uses a sequence of visual cues observed during aerial navigation to find a target specified through multiple possible modalities. This could emulate a UAV involved in a search-and-rescue operation navigating through an area, observing a stream of aerial images as it goes. The AGL task is associated with two important challenges. Firstly, an agent must deal with a goal specification in one of multiple modalities (e.g., through a natural language description) while the search cues are provided in other modalities (aerial imagery). The second challenge is limited localization time (e.g., limited battery life, urgency) so that the goal must be localized as efficiently as possible, i.e. the agent must effectively leverage its sequentially observed aerial views when searching for the goal. To address these challenges, we propose GOMAA-Geo - a goal modality agnostic active geo-localization agent - for zero-shot generalization between different goal modalities. Our approach combines cross-modality contrastive learning to align representations across modalities with supervised foundation model pretraining and reinforcement learning to obtain highly effective navigation and localization policies. Through extensive evaluations, we show that GOMAA-Geo outperforms alternative learnable approaches and that it generalizes across datasets - e.g., to disaster-hit areas without seeing a single disaster scenario during training - and goal modalities - e.g., to ground-level imagery or textual descriptions, despite only being trained with goals specified as aerial views. Code and models are publicly available at https://github.com/mvrl/GOMAA-Geo/tree/main.