 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Robustness Tradeoff in Fine-Tuning
Mar 19, 2025Fine-tuning has become the standard practice for adapting pre-trained (upstream) models to downstream tasks. However, the impact on model robustness is not well understood. In this work, we characterize the robustness-accuracy trade-off in fine-tuning. We evaluate the robustness and accuracy of fine-tuned models over 6 benchmark datasets and 7 different fine-tuning strategies. We observe a consistent trade-off between adversarial robustness and accuracy. Peripheral updates such as BitFit are more effective for simple tasks--over 75% above the average measured with area under the Pareto frontiers on CIFAR-10 and CIFAR-100. In contrast, fine-tuning information-heavy layers, such as attention layers via Compacter, achieves a better Pareto frontier on more complex tasks--57.5% and 34.6% above the average on Caltech-256 and CUB-200, respectively. Lastly, we observe that robustness of fine-tuning against out-of-distribution data closely tracks accuracy. These insights emphasize the need for robustness-aware fine-tuning to ensure reliable real-world deployments.
Adversarial Agents: Black-Box Evasion Attacks with Reinforcement Learning
Mar 03, 2025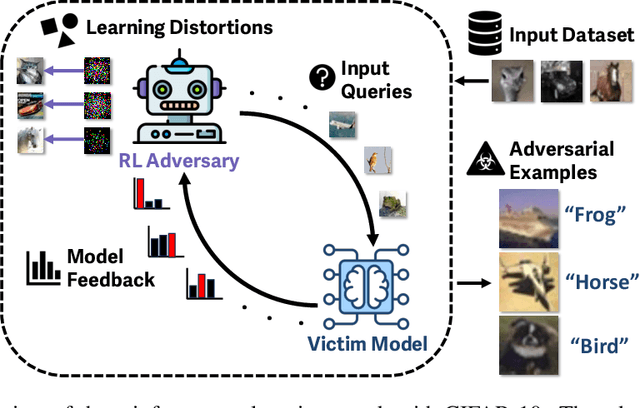

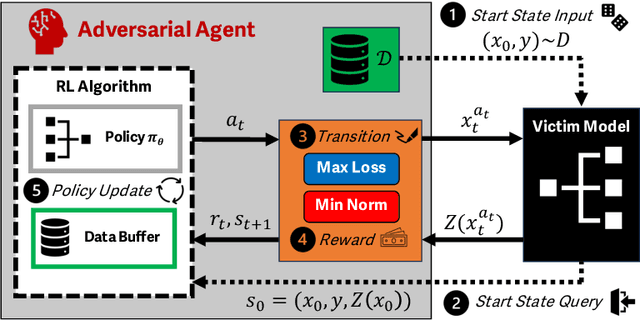

Reinforcement learning (RL) offers powerful techniques for solving complex sequential decision-making tasks from experience. In this paper, we demonstrate how RL can be applied to adversarial machine learning (AML) to develop a new class of attacks that learn to generate adversarial examples: inputs designed to fool machine learning models. Unlike traditional AML methods that craft adversarial examples independently, our RL-based approach retains and exploits past attack experience to improve future attacks. We formulate adversarial example generation as a Markov Decision Process and evaluate RL's ability to (a) learn effective and efficient attack strategies and (b) compete with state-of-the-art AML. On CIFAR-10, our agent increases the success rate of adversarial examples by 19.4% and decreases the median number of victim model queries per adversarial example by 53.2% from the start to the end of training. In a head-to-head comparison with a state-of-the-art image attack, SquareAttack, our approach enables an adversary to generate adversarial examples with 13.1% more success after 5000 episodes of training. From a security perspective, this work demonstrates a powerful new attack vector that uses RL to attack ML models efficiently and at scale.
Alignment and Adversarial Robustness: Are More Human-Like Models More Secure?
Feb 17, 2025Representational alignment refers to the extent to which a model's internal representations mirror biological vision, offering insights into both neural similarity and functional correspondence. Recently, some more aligned models have demonstrated higher resiliency to adversarial examples, raising the question of whether more human-aligned models are inherently more secure. In this work, we conduct a large-scale empirical analysis to systematically investigate the relationship between representational alignment and adversarial robustness. We evaluate 118 models spanning diverse architectures and training paradigms, measuring their neural and behavioral alignment and engineering task performance across 106 benchmarks as well as their adversarial robustness via AutoAttack. Our findings reveal that while average alignment and robustness exhibit a weak overall correlation, specific alignment benchmarks serve as strong predictors of adversarial robustness, particularly those that measure selectivity towards texture or shape. These results suggest that different forms of alignment play distinct roles in model robustness, motivating further investigation into how alignment-driven approaches can be leveraged to build more secure and perceptually-grounded vision models.
Targeting Alignment: Extracting Safety Classifiers of Aligned LLMs
Jan 27, 2025



Alignment in large language models (LLMs) is used to enforce guidelines such as safety. Yet, alignment fails in the face of jailbreak attacks that modify inputs to induce unsafe outputs. In this paper, we present and evaluate a method to assess the robustness of LLM alignment. We observe that alignment embeds a safety classifier in the target model that is responsible for deciding between refusal and compliance. We seek to extract an approximation of this classifier, called a surrogate classifier, from the LLM. We develop an algorithm for identifying candidate classifiers from subsets of the LLM model. We evaluate the degree to which the candidate classifiers approximate the model's embedded classifier in benign (F1 score) and adversarial (using surrogates in a white-box attack) settings. Our evaluation shows that the best candidates achieve accurate agreement (an F1 score above 80%) using as little as 20% of the model architecture. Further, we find attacks mounted on the surrogate models can be transferred with high accuracy. For example, a surrogate using only 50% of the Llama 2 model achieved an attack success rate (ASR) of 70%, a substantial improvement over attacking the LLM directly, where we only observed a 22% ASR. These results show that extracting surrogate classifiers is a viable (and highly effective) means for modeling (and therein addressing) the vulnerability of aligned models to jailbreaking attacks.
Err on the Side of Texture: Texture Bias on Real Data
Dec 13, 2024



Bias significantly undermines both the accuracy and trustworthiness of machine learning models. To date, one of the strongest biases observed in image classification models is texture bias-where models overly rely on texture information rather than shape information. Yet, existing approaches for measuring and mitigating texture bias have not been able to capture how textures impact model robustness in real-world settings. In this work, we introduce the Texture Association Value (TAV), a novel metric that quantifies how strongly models rely on the presence of specific textures when classifying objects. Leveraging TAV, we demonstrate that model accuracy and robustness are heavily influenced by texture. Our results show that texture bias explains the existence of natural adversarial examples, where over 90% of these samples contain textures that are misaligned with the learned texture of their true label, resulting in confident mispredictions.
AutoDAN-Turbo: A Lifelong Agent for Strategy Self-Exploration to Jailbreak LLMs
Oct 14, 2024



In this paper, we propose AutoDAN-Turbo, a black-box jailbreak method that can automatically discover as many jailbreak strategies as possible from scratch, without any human intervention or predefined scopes (e.g., specified candidate strategies), and use them for red-teaming. As a result, AutoDAN-Turbo can significantly outperform baseline methods, achieving a 74.3% higher average attack success rate on public benchmarks. Notably, AutoDAN-Turbo achieves an 88.5 attack success rate on GPT-4-1106-turbo. In addition, AutoDAN-Turbo is a unified framework that can incorporate existing human-designed jailbreak strategies in a plug-and-play manner. By integrating human-designed strategies, AutoDAN-Turbo can even achieve a higher attack success rate of 93.4 on GPT-4-1106-turbo.
On Synthetic Texture Datasets: Challenges, Creation, and Curation
Sep 16, 2024



The influence of textures on machine learning models has been an ongoing investigation, specifically in texture bias/learning, interpretability, and robustness. However, due to the lack of large and diverse texture data available, the findings in these works have been limited, as more comprehensive evaluations have not been feasible. Image generative models are able to provide data creation at scale, but utilizing these models for texture synthesis has been unexplored and poses additional challenges both in creating accurate texture images and validating those images. In this work, we introduce an extensible methodology and corresponding new dataset for generating high-quality, diverse texture images capable of supporting a broad set of texture-based tasks. Our pipeline consists of: (1) developing prompts from a range of descriptors to serve as input to text-to-image models, (2) adopting and adapting Stable Diffusion pipelines to generate and filter the corresponding images, and (3) further filtering down to the highest quality images. Through this, we create the Prompted Textures Dataset (PTD), a dataset of 362,880 texture images that span 56 textures. During the process of generating images, we find that NSFW safety filters in image generation pipelines are highly sensitive to texture (and flag up to 60\% of our texture images), uncovering a potential bias in these models and presenting unique challenges when working with texture data. Through both standard metrics and a human evaluation, we find that our dataset is high quality and diverse.
Explorations in Texture Learning
Mar 14, 2024In this work, we investigate \textit{texture learning}: the identification of textures learned by object classification models, and the extent to which they rely on these textures. We build texture-object associations that uncover new insights about the relationships between texture and object classes in CNNs and find three classes of results: associations that are strong and expected, strong and not expected, and expected but not present. Our analysis demonstrates that investigations in texture learning enable new methods for interpretability and have the potential to uncover unexpected biases.
A New Era in LLM Security: Exploring Security Concerns in Real-World LLM-based Systems
Feb 28, 2024



Large Language Model (LLM) systems are inherently compositional, with individual LLM serving as the core foundation with additional layers of objects such as plugins, sandbox, and so on. Along with the great potential, there are also increasing concerns over the security of such probabilistic intelligent systems. However, existing studies on LLM security often focus on individual LLM, but without examining the ecosystem through the lens of LLM systems with other objects (e.g., Frontend, Webtool, Sandbox, and so on). In this paper, we systematically analyze the security of LLM systems, instead of focusing on the individual LLMs. To do so, we build on top of the information flow and formulate the security of LLM systems as constraints on the alignment of the information flow within LLM and between LLM and other objects. Based on this construction and the unique probabilistic nature of LLM, the attack surface of the LLM system can be decomposed into three key components: (1) multi-layer security analysis, (2) analysis of the existence of constraints, and (3) analysis of the robustness of these constraints. To ground this new attack surface, we propose a multi-layer and multi-step approach and apply it to the state-of-art LLM system, OpenAI GPT4. Our investigation exposes several security issues, not just within the LLM model itself but also in its integration with other components. We found that although the OpenAI GPT4 has designed numerous safety constraints to improve its safety features, these safety constraints are still vulnerable to attackers. To further demonstrate the real-world threats of our discovered vulnerabilities, we construct an end-to-end attack where an adversary can illicitly acquire the user's chat history, all without the need to manipulate the user's input or gain direct access to OpenAI GPT4. Our demo is in the link: https://fzwark.github.io/LLM-System-Attack-Demo/
Mitigating Fine-tuning Jailbreak Attack with Backdoor Enhanced Alignment
Feb 27, 2024



Despite the general capabilities of Large Language Models (LLMs) like GPT-4 and Llama-2, these models still request fine-tuning or adaptation with customized data when it comes to meeting the specific business demands and intricacies of tailored use cases. However, this process inevitably introduces new safety threats, particularly against the Fine-tuning based Jailbreak Attack (FJAttack), where incorporating just a few harmful examples into the fine-tuning dataset can significantly compromise the model safety. Though potential defenses have been proposed by incorporating safety examples into the fine-tuning dataset to reduce the safety issues, such approaches require incorporating a substantial amount of safety examples, making it inefficient. To effectively defend against the FJAttack with limited safety examples, we propose a Backdoor Enhanced Safety Alignment method inspired by an analogy with the concept of backdoor attacks. In particular, we construct prefixed safety examples by integrating a secret prompt, acting as a "backdoor trigger", that is prefixed to safety examples. Our comprehensive experiments demonstrate that through the Backdoor Enhanced Safety Alignment with adding as few as 11 prefixed safety examples, the maliciously fine-tuned LLMs will achieve similar safety performance as the original aligned models. Furthermore, we also explore the effectiveness of our method in a more practical setting where the fine-tuning data consists of both FJAttack examples and the fine-tuning task data. Our method shows great efficacy in defending against FJAttack without harming the performance of fine-tuning tasks.