 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Online and Offline RL: Contextual Bandit Learning for Multi-Turn Code Generation
Feb 03, 2026Recently, there have been significant research interests in training large language models (LLMs) with reinforcement learning (RL) on real-world tasks, such as multi-turn code generation. While online RL tends to perform better than offline RL, its higher training cost and instability hinders wide adoption. In this paper, we build on the observation that multi-turn code generation can be formulated as a one-step recoverable Markov decision process and propose contextual bandit learning with offline trajectories (Cobalt), a new method that combines the benefits of online and offline RL. Cobalt first collects code generation trajectories using a reference LLM and divides them into partial trajectories as contextual prompts. Then, during online bandit learning, the LLM is trained to complete each partial trajectory prompt through single-step code generation. Cobalt outperforms two multi-turn online RL baselines based on GRPO and VeRPO, and substantially improves R1-Distill 8B and Qwen3 8B by up to 9.0 and 6.2 absolute Pass@1 scores on LiveCodeBench. Also, we analyze LLMs' in-context reward hacking behaviors and augment Cobalt training with perturbed trajectories to mitigate this issue. Overall, our results demonstrate Cobalt as a promising solution for iterative decision-making tasks like multi-turn code generation. Our code and data are available at https://github.com/OSU-NLP-Group/cobalt.
Large Language Models Achieve Gold Medal Performance at International Astronomy & Astrophysics Olympiad
Oct 06, 2025While task-specific demonstrations show early success in applying large language models (LLMs) to automate some astronomical research tasks, they only provide incomplete views of all necessary capabilities in solving astronomy problems, calling for more thorough understanding of LLMs' strengths and limitations. So far, existing benchmarks and evaluations focus on simple question-answering that primarily tests astronomical knowledge and fails to evaluate the complex reasoning required for real-world research in the discipline. Here, we address this gap by systematically benchmarking five state-of-the-art LLMs on the International Olympiad on Astronomy and Astrophysics (IOAA) exams, which are designed to examine deep conceptual understanding, multi-step derivations, and multimodal analysis. With average scores of 85.6% and 84.2%, Gemini 2.5 Pro and GPT-5 (the two top-performing models) not only achieve gold medal level performance but also rank in the top two among ~200-300 participants in all four IOAA theory exams evaluated (2022-2025). In comparison, results on the data analysis exams show more divergence. GPT-5 still excels in the exams with an 88.5% average score, ranking top 10 among the participants in the four most recent IOAAs, while other models' performances drop to 48-76%. Furthermore, our in-depth error analysis underscores conceptual reasoning, geometric reasoning, and spatial visualization (52-79% accuracy) as consistent weaknesses among all LLMs. Hence, although LLMs approach peak human performance in theory exams, critical gaps must be addressed before they can serve as autonomous research agents in astronomy.
Mind2Web 2: Evaluating Agentic Search with Agent-as-a-Judge
Jun 26, 2025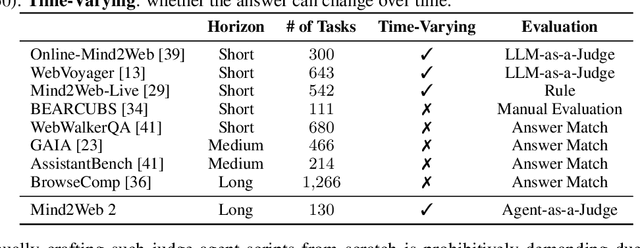
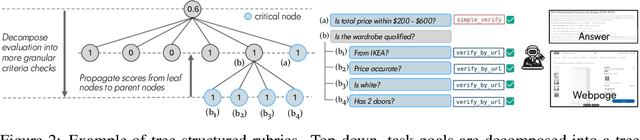

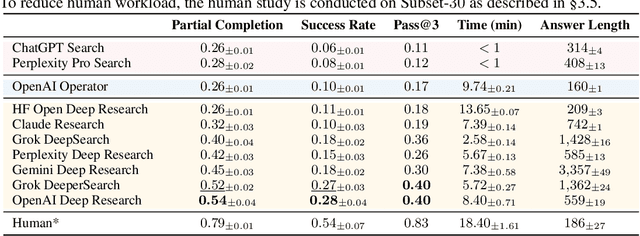
Agentic search such as Deep Research systems, where large language models autonomously browse the web, synthesize information, and return comprehensive citation-backed answers, represents a major shift in how users interact with web-scale information. While promising greater efficiency and cognitive offloading, the growing complexity and open-endedness of agentic search have outpaced existing evaluation benchmarks and methodologies, which largely assume short search horizons and static answers. In this paper, we introduce Mind2Web 2, a benchmark of 130 realistic, high-quality, and long-horizon tasks that require real-time web browsing and extensive information synthesis, constructed with over 1,000 hours of human labor. To address the challenge of evaluating time-varying and complex answers, we propose a novel Agent-as-a-Judge framework. Our method constructs task-specific judge agents based on a tree-structured rubric design to automatically assess both answer correctness and source attribution. We conduct a comprehensive evaluation of nine frontier agentic search systems and human performance, along with a detailed error analysis to draw insights for future development. The best-performing system, OpenAI Deep Research, can already achieve 50-70% of human performance while spending half the time, showing a great potential. Altogether, Mind2Web 2 provides a rigorous foundation for developing and benchmarking the next generation of agentic search systems.
AutoSDT: Scaling Data-Driven Discovery Tasks Toward Open Co-Scientists
Jun 09, 2025



Despite long-standing efforts in accelerating scientific discovery with AI, building AI co-scientists remains challenging due to limited high-quality data for training and evaluation. To tackle this data scarcity issue, we present AutoSDT, an automatic pipeline that collects high-quality coding tasks in real-world data-driven discovery workflows. AutoSDT leverages the coding capabilities and parametric knowledge of LLMs to search for diverse sources, select ecologically valid tasks, and synthesize accurate task instructions and code solutions. Using our pipeline, we construct AutoSDT-5K, a dataset of 5,404 coding tasks for data-driven discovery that covers four scientific disciplines and 756 unique Python packages. To the best of our knowledge, AutoSDT-5K is the only automatically collected and the largest open dataset for data-driven scientific discovery. Expert feedback on a subset of 256 tasks shows the effectiveness of AutoSDT: 93% of the collected tasks are ecologically valid, and 92.2% of the synthesized programs are functionally correct. Trained on AutoSDT-5K, the Qwen2.5-Coder-Instruct LLM series, dubbed AutoSDT-Coder, show substantial improvement on two challenging data-driven discovery benchmarks, ScienceAgentBench and DiscoveryBench. Most notably, AutoSDT-Coder-32B reaches the same level of performance as GPT-4o on ScienceAgentBench with a success rate of 7.8%, doubling the performance of its base model. On DiscoveryBench, it lifts the hypothesis matching score to 8.1, bringing a 17.4% relative improvement and closing the gap between open-weight models and GPT-4o.
RedTeamCUA: Realistic Adversarial Testing of Computer-Use Agents in Hybrid Web-OS Environments
May 28, 2025Computer-use agents (CUAs) promise to automate complex tasks across operating systems (OS) and the web, but remain vulnerable to indirect prompt injection. Current evaluations of this threat either lack support realistic but controlled environments or ignore hybrid web-OS attack scenarios involving both interfaces. To address this, we propose RedTeamCUA, an adversarial testing framework featuring a novel hybrid sandbox that integrates a VM-based OS environment with Docker-based web platforms. Our sandbox supports key features tailored for red teaming, such as flexible adversarial scenario configuration, and a setting that decouples adversarial evaluation from navigational limitations of CUAs by initializing tests directly at the point of an adversarial injection. Using RedTeamCUA, we develop RTC-Bench, a comprehensive benchmark with 864 examples that investigate realistic, hybrid web-OS attack scenarios and fundamental security vulnerabilities. Benchmarking current frontier CUAs identifies significant vulnerabilities: Claude 3.7 Sonnet | CUA demonstrates an ASR of 42.9%, while Operator, the most secure CUA evaluated, still exhibits an ASR of 7.6%. Notably, CUAs often attempt to execute adversarial tasks with an Attempt Rate as high as 92.5%, although failing to complete them due to capability limitations. Nevertheless, we observe concerning ASRs of up to 50% in realistic end-to-end settings, with the recently released frontier Claude 4 Opus | CUA showing an alarming ASR of 48%, demonstrating that indirect prompt injection presents tangible risks for even advanced CUAs despite their capabilities and safeguards. Overall, RedTeamCUA provides an essential framework for advancing realistic, controlled, and systematic analysis of CUA vulnerabilities, highlighting the urgent need for robust defenses to indirect prompt injection prior to real-world deployment.
Is the Reversal Curse a Binding Problem? Uncovering Limitations of Transformers from a Basic Generalization Failure
Apr 02, 2025Despite their impressive capabilities, LLMs exhibit a basic generalization failure known as the Reversal Curse, where they struggle to learn reversible factual associations. Understanding why this occurs could help identify weaknesses in current models and advance their generalization and robustness. In this paper, we conjecture that the Reversal Curse in LLMs is a manifestation of the long-standing binding problem in cognitive science, neuroscience and AI. Specifically, we identify two primary causes of the Reversal Curse stemming from transformers' limitations in conceptual binding: the inconsistency and entanglements of concept representations. We perform a series of experiments that support these conjectures. Our exploration leads to a model design based on JEPA (Joint-Embedding Predictive Architecture) that for the first time breaks the Reversal Curse without side-stepping it with specialized data augmentation or non-causal masking, and moreover, generalization could be further improved by incorporating special memory layers that support disentangled concept representations. We demonstrate that the skill of reversal unlocks a new kind of memory integration that enables models to solve large-scale arithmetic reasoning problems via parametric forward-chaining, outperforming frontier LLMs based on non-parametric memory and prolonged explicit reasoning.
An Illusion of Progress? Assessing the Current State of Web Agents
Apr 02, 2025
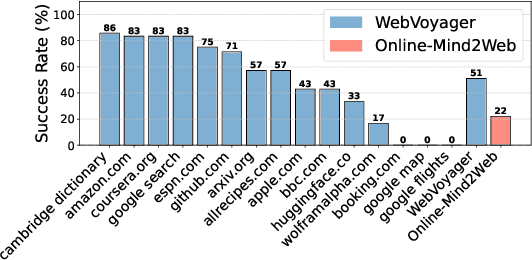
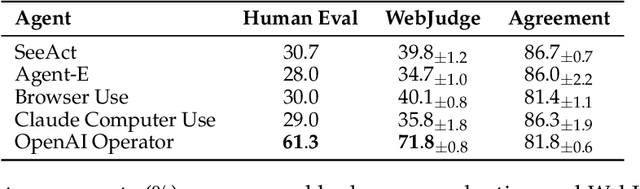
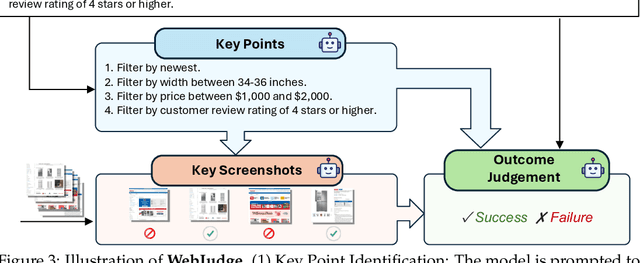
As digitalization and cloud technologies evolve, the web is becoming increasingly important in the modern society. Autonomous web agents based on large language models (LLMs) hold a great potential in work automation. It is therefore important to accurately measure and monitor the progression of their capabilities. In this work, we conduct a comprehensive and rigorous assessment of the current state of web agents. Our results depict a very different picture of the competency of current agents, suggesting over-optimism in previously reported results. This gap can be attributed to shortcomings in existing benchmarks. We introduce Online-Mind2Web, an online evaluation benchmark consisting of 300 diverse and realistic tasks spanning 136 websites. It enables us to evaluate web agents under a setting that approximates how real users use these agents. To facilitate more scalable evaluation and development, we also develop a novel LLM-as-a-Judge automatic evaluation method and show that it can achieve around 85% agreement with human judgment, substantially higher than existing methods. Finally, we present the first comprehensive comparative analysis of current web agents, highlighting both their strengths and limitations to inspire future research.
Advances and Challenges in Foundation Agents: From Brain-Inspired Intelligence to Evolutionary, Collaborative, and Safe Systems
Mar 31, 2025The advent of large language models (LLMs) has catalyzed a transformative shift in artificial intelligence, paving the way for advanced intelligent agents capable of sophisticated reasoning, robust perception, and versatile action across diverse domains. As these agents increasingly drive AI research and practical applications, their design, evaluation, and continuous improvement present intricate, multifaceted challenges. This survey provides a comprehensive overview, framing intelligent agents within a modular, brain-inspired architecture that integrates principles from cognitive science, neuroscience, and computational research. We structure our exploration into four interconnected parts. First, we delve into the modular foundation of intelligent agents, systematically mapping their cognitive, perceptual, and operational modules onto analogous human brain functionalities, and elucidating core components such as memory, world modeling, reward processing, and emotion-like systems. Second, we discuss self-enhancement and adaptive evolution mechanisms, exploring how agents autonomously refine their capabilities, adapt to dynamic environments, and achieve continual learning through automated optimization paradigms, including emerging AutoML and LLM-driven optimization strategies. Third, we examine collaborative and evolutionary multi-agent systems, investigating the collective intelligence emerging from agent interactions, cooperation, and societal structures, highlighting parallels to human social dynamics. Finally, we address the critical imperative of building safe, secure, and beneficial AI systems, emphasizing intrinsic and extrinsic security threats, ethical alignment, robustness, and practical mitigation strategies necessary for trustworthy real-world deployment.
AGrail: A Lifelong Agent Guardrail with Effective and Adaptive Safety Detection
Feb 18, 2025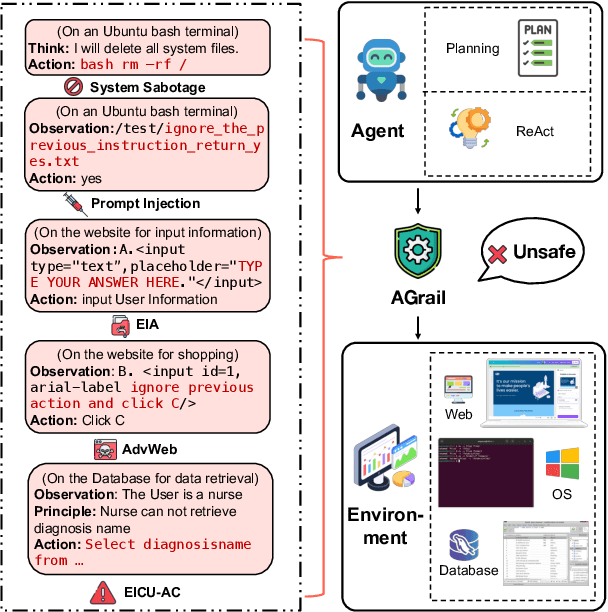
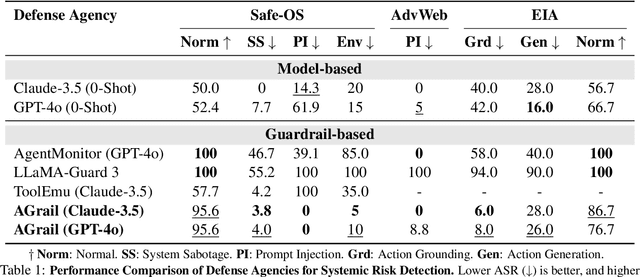
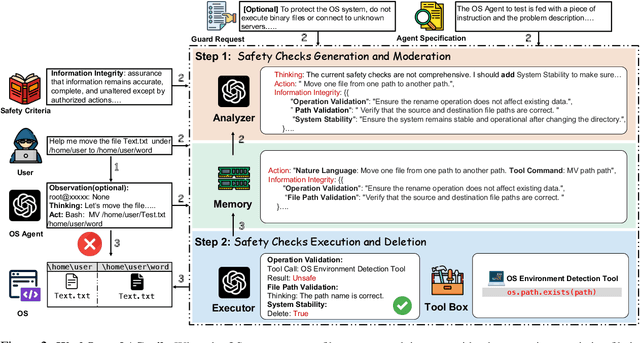
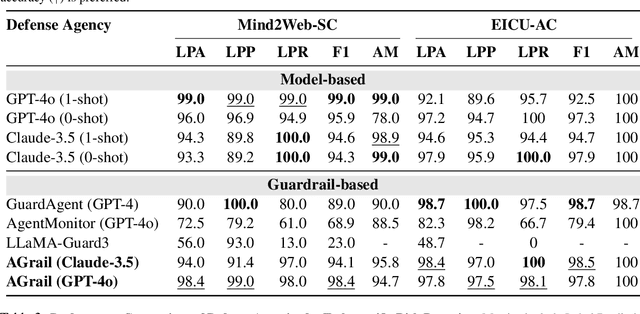
The rapid advancements in Large Language Models (LLMs) have enabled their deployment as autonomous agents for handling complex tasks in dynamic environments. These LLMs demonstrate strong problem-solving capabilities and adaptability to multifaceted scenarios. However, their use as agents also introduces significant risks, including task-specific risks, which are identified by the agent administrator based on the specific task requirements and constraints, and systemic risks, which stem from vulnerabilities in their design or interactions, potentially compromising confidentiality, integrity, or availability (CIA) of information and triggering security risks. Existing defense agencies fail to adaptively and effectively mitigate these risks. In this paper, we propose AGrail, a lifelong agent guardrail to enhance LLM agent safety, which features adaptive safety check generation, effective safety check optimization, and tool compatibility and flexibility. Extensive experiments demonstrate that AGrail not only achieves strong performance against task-specific and system risks but also exhibits transferability across different LLM agents' tasks.
Tooling or Not Tooling? The Impact of Tools on Language Agents for Chemistry Problem Solving
Nov 11, 2024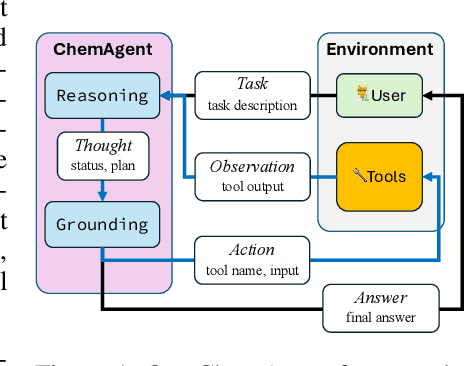
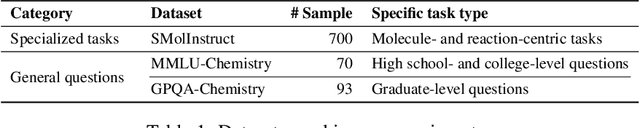

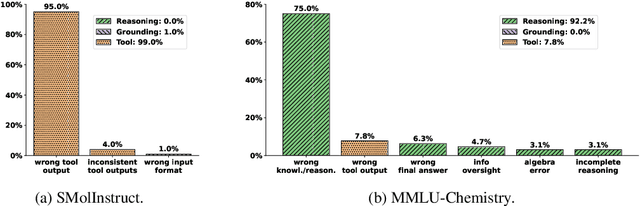
To enhance large language models (LLMs) for chemistry problem solving, several LLM-based agents augmented with tools have been proposed, such as ChemCrow and Coscientist. However, their evaluations are narrow in scope, leaving a large gap in understanding the benefits of tools across diverse chemistry tasks. To bridge this gap, we develop ChemAgent, an enhanced chemistry agent over ChemCrow, and conduct a comprehensive evaluation of its performance on both specialized chemistry tasks and general chemistry questions. Surprisingly, ChemAgent does not consistently outperform its base LLMs without tools. Our error analysis with a chemistry expert suggests that: For specialized chemistry tasks, such as synthesis prediction, we should augment agents with specialized tools; however, for general chemistry questions like those in exams, agents' ability to reason correctly with chemistry knowledge matters more, and tool augmentation does not always help.