 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Nano Omni: Efficient and Open Multimodal Intelligence
Apr 27, 2026We introduce Nemotron 3 Nano Omni, the latest model in the Nemotron multimodal series and the first to natively support audio inputs alongside text, images, and video. Nemotron 3 Nano Omni delivers consistent accuracy improvements over its predecessor, Nemotron Nano V2 VL, across all modalities, enabled by advances in architecture, training data and recipes. In particular, Nemotron 3 delivers leading results in real-world document understanding, long audio-video comprehension, and agentic computer use. Built on the highly efficient Nemotron 3 Nano 30B-A3B backbone, Nemotron 3 Nano Omni further incorporates innovative multimodal token-reduction techniques to deliver substantially lower inference latency and higher throughput than other models of similar size. We are releasing model checkpoints in BF16, FP8, and FP4 formats, along with portions of the training data and codebase to facilitate further research and development.
ProRL Agent: Rollout-as-a-Service for RL Training of Multi-Turn LLM Agents
Mar 19, 2026Multi-turn LLM agents are increasingly important for solving complex, interactive tasks, and reinforcement learning (RL) is a key ingredient for improving their long-horizon behavior. However, RL training requires generating large numbers of sandboxed rollout trajectories, and existing infrastructures often couple rollout orchestration with the training loop, making systems hard to migrate and maintain. Under the rollout-as-a-service philosophy, we present ProRL Agent , a scalable infrastructure that serves the full agentic rollout lifecycle through an API service. ProRL Agent also provides standardized and extensible sandbox environments that support diverse agentic tasks in rootless HPC settings. We validate ProRL Agent through RL training on software engineering, math, STEM, and coding tasks. ProRL Agent is open-sourced and integrated as part of NVIDIA NeMo Gym.
Golden Goose: A Simple Trick to Synthesize Unlimited RLVR Tasks from Unverifiable Internet Text
Jan 30, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has become a cornerstone for unlocking complex reasoning in Large Language Models (LLMs). Yet, scaling up RL is bottlenecked by limited existing verifiable data, where improvements increasingly saturate over prolonged training. To overcome this, we propose Golden Goose, a simple trick to synthesize unlimited RLVR tasks from unverifiable internet text by constructing a multiple-choice question-answering version of the fill-in-the-middle task. Given a source text, we prompt an LLM to identify and mask key reasoning steps, then generate a set of diverse, plausible distractors. This enables us to leverage reasoning-rich unverifiable corpora typically excluded from prior RLVR data construction (e.g., science textbooks) to synthesize GooseReason-0.7M, a large-scale RLVR dataset with over 0.7 million tasks spanning mathematics, programming, and general scientific domains. Empirically, GooseReason effectively revives models saturated on existing RLVR data, yielding robust, sustained gains under continuous RL and achieving new state-of-the-art results for 1.5B and 4B-Instruct models across 15 diverse benchmarks. Finally, we deploy Golden Goose in a real-world setting, synthesizing RLVR tasks from raw FineWeb scrapes for the cybersecurity domain, where no prior RLVR data exists. Training Qwen3-4B-Instruct on the resulting data GooseReason-Cyber sets a new state-of-the-art in cybersecurity, surpassing a 7B domain-specialized model with extensive domain-specific pre-training and post-training. This highlights the potential of automatically scaling up RLVR data by exploiting abundant, reasoning-rich, unverifiable internet text.
NVIDIA Nemotron Nano V2 VL
Nov 07, 2025We introduce Nemotron Nano V2 VL, the latest model of the Nemotron vision-language series designed for strong real-world document understanding, long video comprehension, and reasoning tasks. Nemotron Nano V2 VL delivers significant improvements over our previous model, Llama-3.1-Nemotron-Nano-VL-8B, across all vision and text domains through major enhancements in model architecture, datasets, and training recipes. Nemotron Nano V2 VL builds on Nemotron Nano V2, a hybrid Mamba-Transformer LLM, and innovative token reduction techniques to achieve higher inference throughput in long document and video scenarios. We are releasing model checkpoints in BF16, FP8, and FP4 formats and sharing large parts of our datasets, recipes and training code.
A Survey of Self-Evolving Agents: On Path to Artificial Super Intelligence
Jul 28, 2025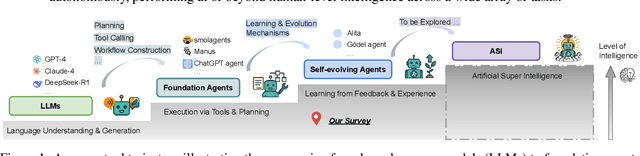

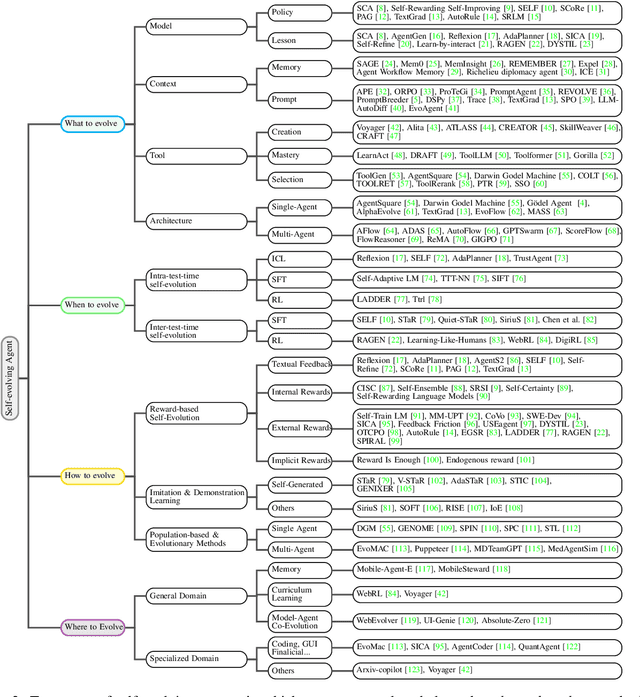
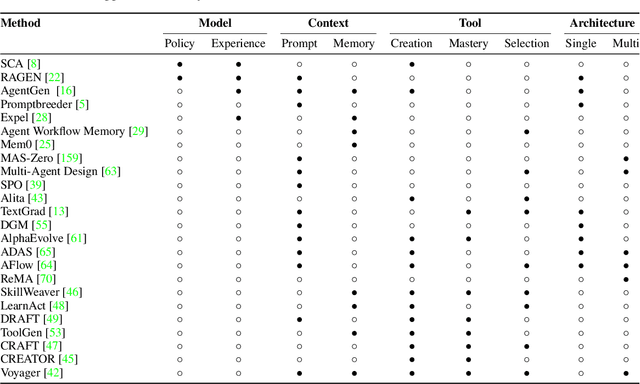
Large Language Models (LLMs) have demonstrated strong capabilities but remain fundamentally static, unable to adapt their internal parameters to novel tasks, evolving knowledge domains, or dynamic interaction contexts. As LLMs are increasingly deployed in open-ended, interactive environments, this static nature has become a critical bottleneck, necessitating agents that can adaptively reason, act, and evolve in real time. This paradigm shift -- from scaling static models to developing self-evolving agents -- has sparked growing interest in architectures and methods enabling continual learning and adaptation from data, interactions, and experiences. This survey provides the first systematic and comprehensive review of self-evolving agents, organized around three foundational dimensions -- what to evolve, when to evolve, and how to evolve. We examine evolutionary mechanisms across agent components (e.g., models, memory, tools, architecture), categorize adaptation methods by stages (e.g., intra-test-time, inter-test-time), and analyze the algorithmic and architectural designs that guide evolutionary adaptation (e.g., scalar rewards, textual feedback, single-agent and multi-agent systems). Additionally, we analyze evaluation metrics and benchmarks tailored for self-evolving agents, highlight applications in domains such as coding, education, and healthcare, and identify critical challenges and research directions in safety, scalability, and co-evolutionary dynamics. By providing a structured framework for understanding and designing self-evolving agents, this survey establishes a roadmap for advancing adaptive agentic systems in both research and real-world deployments, ultimately shedding lights to pave the way for the realization of Artificial Super Intelligence (ASI), where agents evolve autonomously, performing at or beyond human-level intelligence across a wide array of tasks.
Divide, Optimize, Merge: Fine-Grained LLM Agent Optimization at Scale
May 06, 2025LLM-based optimization has shown remarkable potential in enhancing agentic systems. However, the conventional approach of prompting LLM optimizer with the whole training trajectories on training dataset in a single pass becomes untenable as datasets grow, leading to context window overflow and degraded pattern recognition. To address these challenges, we propose Fine-Grained Optimization (FGO), a scalable framework that divides large optimization tasks into manageable subsets, performs targeted optimizations, and systematically combines optimized components through progressive merging. Evaluation across ALFWorld, LogisticsQA, and GAIA benchmarks demonstrate that FGO outperforms existing approaches by 1.6-8.6% while reducing average prompt token consumption by 56.3%. Our framework provides a practical solution for scaling up LLM-based optimization of increasingly sophisticated agent systems. Further analysis demonstrates that FGO achieves the most consistent performance gain in all training dataset sizes, showcasing its scalability and efficiency.
Which Agent Causes Task Failures and When? On Automated Failure Attribution of LLM Multi-Agent Systems
Apr 30, 2025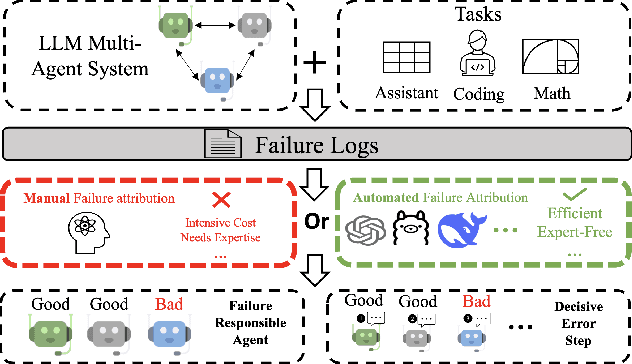
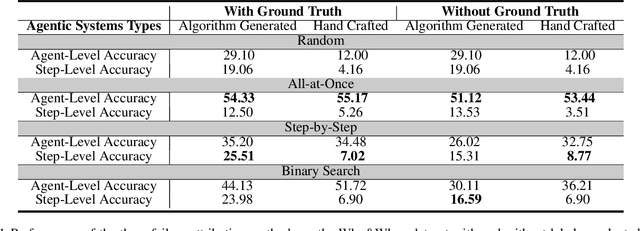
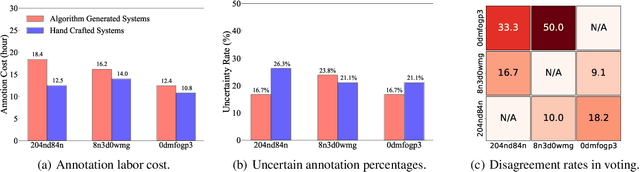

Failure attribution in LLM multi-agent systems-identifying the agent and step responsible for task failures-provides crucial clues for systems debugging but remains underexplored and labor-intensive. In this paper, we propose and formulate a new research area: automated failure attribution for LLM multi-agent systems. To support this initiative, we introduce the Who&When dataset, comprising extensive failure logs from 127 LLM multi-agent systems with fine-grained annotations linking failures to specific agents and decisive error steps. Using the Who&When, we develop and evaluate three automated failure attribution methods, summarizing their corresponding pros and cons. The best method achieves 53.5% accuracy in identifying failure-responsible agents but only 14.2% in pinpointing failure steps, with some methods performing below random. Even SOTA reasoning models, such as OpenAI o1 and DeepSeek R1, fail to achieve practical usability. These results highlight the task's complexity and the need for further research in this area. Code and dataset are available at https://github.com/mingyin1/Agents_Failure_Attribution
Nemotron-Research-Tool-N1: Tool-Using Language Models with Reinforced Reasoning
Apr 25, 2025Enabling large language models with external tools has become a pivotal strategy for extending their functionality beyond text generation tasks. Prior work typically enhances tool-use abilities by either applying supervised fine-tuning (SFT) to enforce tool-call correctness or distilling reasoning traces from stronger models for SFT. However, both approaches fall short, either omitting reasoning entirely or producing imitative reasoning that limits generalization. Inspired by the success of DeepSeek-R1 in eliciting reasoning through rule-based reinforcement learning, we develop the Nemotron-Research-Tool-N1 series of tool-using language models using a similar training paradigm. Instead of restrictively supervising intermediate reasoning traces distilled from stronger models, Nemotron-Research-Tool-N1 is optimized with a binary reward that evaluates only the structural validity and functional correctness of tool invocations. This lightweight supervision allows the model to autonomously internalize reasoning strategies, without the need for annotated reasoning trajectories. Experiments on the BFCL and API-Bank benchmarks show that Nemotron-Research-Tool-N1-7B and Nemotron-Research-Tool-N1-14B, built on Qwen-2.5-7B/14B-Instruct, achieve state-of-the-art results, outperforming GPT-4o on both evaluations.
Advances and Challenges in Foundation Agents: From Brain-Inspired Intelligence to Evolutionary, Collaborative, and Safe Systems
Mar 31, 2025The advent of large language models (LLMs) has catalyzed a transformative shift in artificial intelligence, paving the way for advanced intelligent agents capable of sophisticated reasoning, robust perception, and versatile action across diverse domains. As these agents increasingly drive AI research and practical applications, their design, evaluation, and continuous improvement present intricate, multifaceted challenges. This survey provides a comprehensive overview, framing intelligent agents within a modular, brain-inspired architecture that integrates principles from cognitive science, neuroscience, and computational research. We structure our exploration into four interconnected parts. First, we delve into the modular foundation of intelligent agents, systematically mapping their cognitive, perceptual, and operational modules onto analogous human brain functionalities, and elucidating core components such as memory, world modeling, reward processing, and emotion-like systems. Second, we discuss self-enhancement and adaptive evolution mechanisms, exploring how agents autonomously refine their capabilities, adapt to dynamic environments, and achieve continual learning through automated optimization paradigms, including emerging AutoML and LLM-driven optimization strategies. Third, we examine collaborative and evolutionary multi-agent systems, investigating the collective intelligence emerging from agent interactions, cooperation, and societal structures, highlighting parallels to human social dynamics. Finally, we address the critical imperative of building safe, secure, and beneficial AI systems, emphasizing intrinsic and extrinsic security threats, ethical alignment, robustness, and practical mitigation strategies necessary for trustworthy real-world deployment.
EcoAct: Economic Agent Determines When to Register What Action
Nov 03, 2024



Recent advancements have enabled Large Language Models (LLMs) to function as agents that can perform actions using external tools. This requires registering, i.e., integrating tool information into the LLM context prior to taking actions. Current methods indiscriminately incorporate all candidate tools into the agent's context and retain them across multiple reasoning steps. This process remains opaque to LLM agents and is not integrated into their reasoning procedures, leading to inefficiencies due to increased context length from irrelevant tools. To address this, we introduce EcoAct, a tool using algorithm that allows LLMs to selectively register tools as needed, optimizing context use. By integrating the tool registration process into the reasoning procedure, EcoAct reduces computational costs by over 50% in multiple steps reasoning tasks while maintaining performance, as demonstrated through extensive experiments. Moreover, it can be plugged into any reasoning pipeline with only minor modifications to the prompt, making it applicable to LLM agents now and future.