 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Does Multi-Agent RL Improve LLM Workflows? Workflow, Scale, and Policy-Sharing Tradeoffs
May 22, 2026Multi-agent LLM workflows route inference through specialized roles to lift end-task accuracy, but jointly training those roles with reinforcement learning is unstable in ways that are poorly understood. We study when end-to-end RL training of multi-agent LLM workflows improves over their base models, comparing Shared-Policy training, where all roles update one policy, with Isolated-Policy training, where each role has its own parameters. Our experimental matrix spans Eval-Opt, Voting, and Orch-Workers workflows, math and code tasks, and three model scales (0.6B, 1.7B, 4B). We find that multi-agent RL usually improves over base models, but gains depend jointly on workflow, task, and scale, not on policy sharing alone. Isolated-Policy tends to reach higher peak accuracy yet more often falls off a terminal accuracy cliff, while Shared-Policy training does not eliminate failure; it redistributes failure into qualitatively different patterns. We then explain the strongest of these patterns through role-level gradient dynamics induced by workflow topology and policy routing: under Isolated-Policy, parallel same-role agents on shared prompts amplify per-role gradients and drive terminal degradation in Voting and Orch-Workers workflows; under Shared-Policy, asymmetric per-step gradient mass causes the shared policy to be captured by the dominant role, producing different failure signatures by task and workflow. Together, the empirical map and its underlying mechanisms show that policy sharing routes training pressure through different channels rather than offering uniform stability, making it a design choice with workflow- and task-conditional tradeoffs.
MetaAgent-X : Breaking the Ceiling of Automatic Multi-Agent Systems via End-to-End Reinforcement Learning
May 14, 2026Automatic multi-agent systems aim to instantiate agent workflows without relying on manually designed or fixed orchestration. However, existing automatic MAS approaches remain only partially adaptive: they either perform training-free test-time search or optimize the meta-level designer while keeping downstream execution agents frozen, which creating a frozen-executor ceiling and leaving the end-to-end training of self-designing and self-executing agentic models unexplored. To address this, we introduce MetaAgent-X, an end-to-end reinforcement learning framework that jointly optimizes automatic MAS design and execution. MetaAgent-X enables script-based MAS generation, execution rollout collection, and credit assignment for both designer and executor trajectories. To support stable and scalable optimization, we propose Executor Designer Hierarchical Rollout and Stagewise Co-evolution to improve training stability and expose the dynamics of designer-executor co-evolution. MetaAgent-X consistently outperforms existing automatic MAS baselines, achieving up to 21.7% gains. Comprehensive ablations show that both designer and executor improve throughout training, and that effective automatic MAS learning follows a stagewise co-evolution process. These results establish end-to-end trainable automatic MAS as a practical paradigm for building self-designing and self-executing agentic models.
On Emotion-Sensitive Decision Making of Small Language Model Agents
Apr 08, 2026Small language models (SLM) are increasingly used as interactive decision-making agents, yet most decision-oriented evaluations ignore emotion as a causal factor influencing behavior. We study emotion-sensitive decision making by combining representation-level emotion induction with a structured game-theoretic evaluation. Emotional states are induced using activation steering derived from crowd-validated, real-world emotion-eliciting texts, enabling controlled and transferable interventions beyond prompt-based methods. We introduce a benchmark built around canonical decision templates that span cooperative and competitive incentives under both complete and incomplete information. These templates are instantiated using strategic scenarios from \textsc{Diplomacy}, \textsc{StarCraft II}, and diverse real-world personas. Experiments across multiple model families in various architecture and modalities, show that emotional perturbations systematically affect strategic choices, but the resulting behaviors are often unstable and not fully aligned with human expectations. Finally, we outline an approach to improve robustness to emotion-driven perturbations.
MemCollab: Cross-Agent Memory Collaboration via Contrastive Trajectory Distillation
Mar 24, 2026Large language model (LLM)-based agents rely on memory mechanisms to reuse knowledge from past problem-solving experiences. Existing approaches typically construct memory in a per-agent manner, tightly coupling stored knowledge to a single model's reasoning style. In modern deployments with heterogeneous agents, a natural question arises: can a single memory system be shared across different models? We found that naively transferring memory between agents often degrades performance, as such memory entangles task-relevant knowledge with agent-specific biases. To address this challenge, we propose MemCollab, a collaborative memory framework that constructs agent-agnostic memory by contrasting reasoning trajectories generated by different agents on the same task. This contrastive process distills abstract reasoning constraints that capture shared task-level invariants while suppressing agent-specific artifacts. We further introduce a task-aware retrieval mechanism that conditions memory access on task category, ensuring that only relevant constraints are used at inference time. Experiments on mathematical reasoning and code generation benchmarks demonstrate that MemCollab consistently improves both accuracy and inference-time efficiency across diverse agents, including cross-modal-family settings. Our results show that the collaboratively constructed memory can function as a shared reasoning resource for diverse LLM-based agents.
Live-Evo: Online Evolution of Agentic Memory from Continuous Feedback
Feb 02, 2026Large language model (LLM) agents are increasingly equipped with memory, which are stored experience and reusable guidance that can improve task-solving performance. Recent \emph{self-evolving} systems update memory based on interaction outcomes, but most existing evolution pipelines are developed for static train/test splits and only approximate online learning by folding static benchmarks, making them brittle under true distribution shift and continuous feedback. We introduce \textsc{Live-Evo}, an online self-evolving memory system that learns from a stream of incoming data over time. \textsc{Live-Evo} decouples \emph{what happened} from \emph{how to use it} via an Experience Bank and a Meta-Guideline Bank, compiling task-adaptive guidelines from retrieved experiences for each task. To manage memory online, \textsc{Live-Evo} maintains experience weights and updates them from feedback: experiences that consistently help are reinforced and retrieved more often, while misleading or stale experiences are down-weighted and gradually forgotten, analogous to reinforcement and decay in human memory. On the live \textit{Prophet Arena} benchmark over a 10-week horizon, \textsc{Live-Evo} improves Brier score by 20.8\% and increases market returns by 12.9\%, while also transferring to deep-research benchmarks with consistent gains over strong baselines. Our code is available at https://github.com/ag2ai/Live-Evo.
Do Images Speak Louder than Words? Investigating the Effect of Textual Misinformation in VLMs
Jan 27, 2026Vision-Language Models (VLMs) have shown strong multimodal reasoning capabilities on Visual-Question-Answering (VQA) benchmarks. However, their robustness against textual misinformation remains under-explored. While existing research has studied the effect of misinformation in text-only domains, it is not clear how VLMs arbitrate between contradictory information from different modalities. To bridge the gap, we first propose the CONTEXT-VQA (i.e., Conflicting Text) dataset, consisting of image-question pairs together with systematically generated persuasive prompts that deliberately conflict with visual evidence. Then, a thorough evaluation framework is designed and executed to benchmark the susceptibility of various models to these conflicting multimodal inputs. Comprehensive experiments over 11 state-of-the-art VLMs reveal that these models are indeed vulnerable to misleading textual prompts, often overriding clear visual evidence in favor of the conflicting text, and show an average performance drop of over 48.2% after only one round of persuasive conversation. Our findings highlight a critical limitation in current VLMs and underscore the need for improved robustness against textual manipulation.
Sliding Window Attention Adaptation
Dec 16, 2025The self-attention mechanism in Transformer-based Large Language Models (LLMs) scales quadratically with input length, making long-context inference expensive. Sliding window attention (SWA) reduces this cost to linear complexity, but naively enabling complete SWA at inference-time for models pretrained with full attention (FA) causes severe long-context performance degradation due to training-inference mismatch. This makes us wonder: Can FA-pretrained LLMs be well adapted to SWA without pretraining? We investigate this by proposing Sliding Window Attention Adaptation (SWAA), a set of practical recipes that combine five methods for better adaptation: (1) applying SWA only during prefilling; (2) preserving "sink" tokens; (3) interleaving FA/SWA layers; (4) chain-of-thought (CoT); and (5) fine-tuning. Our experiments show that SWA adaptation is feasible while non-trivial: no single method suffices, yet specific synergistic combinations effectively recover the original long-context performance. We further analyze the performance-efficiency trade-offs of different SWAA configurations and provide recommended recipes for diverse scenarios, which can greatly and fundamentally accelerate LLM long-context inference speed by up to 100%. Our code is available at https://github.com/yuyijiong/sliding-window-attention-adaptation
A Survey of Self-Evolving Agents: On Path to Artificial Super Intelligence
Jul 28, 2025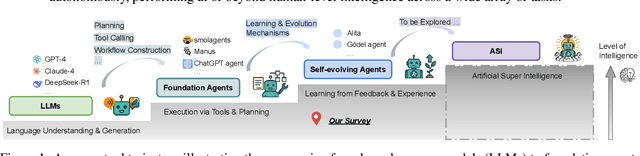

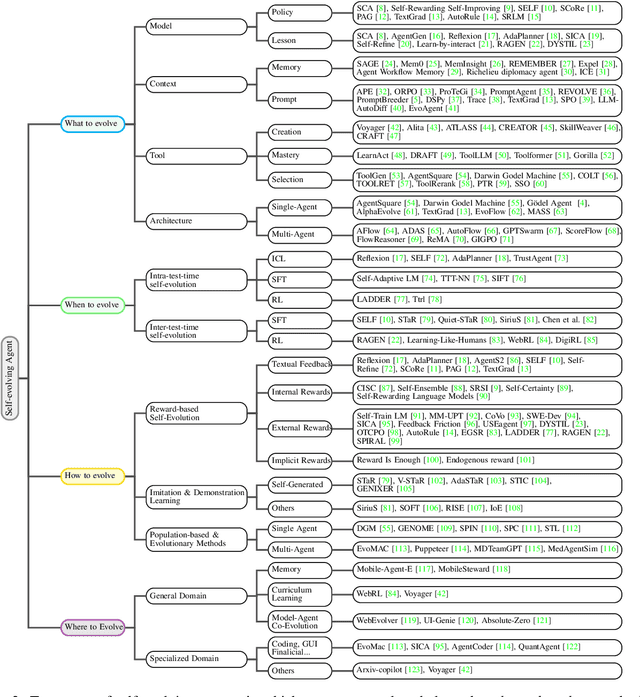
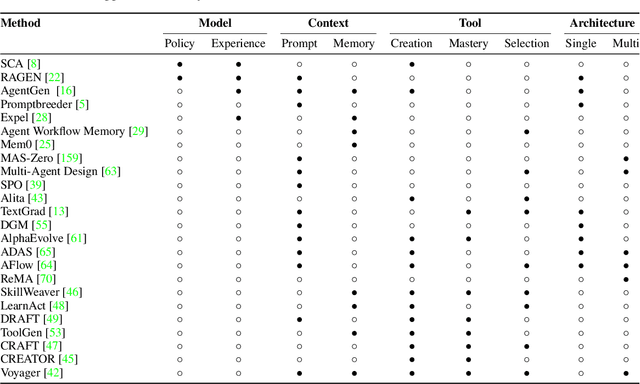
Large Language Models (LLMs) have demonstrated strong capabilities but remain fundamentally static, unable to adapt their internal parameters to novel tasks, evolving knowledge domains, or dynamic interaction contexts. As LLMs are increasingly deployed in open-ended, interactive environments, this static nature has become a critical bottleneck, necessitating agents that can adaptively reason, act, and evolve in real time. This paradigm shift -- from scaling static models to developing self-evolving agents -- has sparked growing interest in architectures and methods enabling continual learning and adaptation from data, interactions, and experiences. This survey provides the first systematic and comprehensive review of self-evolving agents, organized around three foundational dimensions -- what to evolve, when to evolve, and how to evolve. We examine evolutionary mechanisms across agent components (e.g., models, memory, tools, architecture), categorize adaptation methods by stages (e.g., intra-test-time, inter-test-time), and analyze the algorithmic and architectural designs that guide evolutionary adaptation (e.g., scalar rewards, textual feedback, single-agent and multi-agent systems). Additionally, we analyze evaluation metrics and benchmarks tailored for self-evolving agents, highlight applications in domains such as coding, education, and healthcare, and identify critical challenges and research directions in safety, scalability, and co-evolutionary dynamics. By providing a structured framework for understanding and designing self-evolving agents, this survey establishes a roadmap for advancing adaptive agentic systems in both research and real-world deployments, ultimately shedding lights to pave the way for the realization of Artificial Super Intelligence (ASI), where agents evolve autonomously, performing at or beyond human-level intelligence across a wide array of tasks.
Absolute Zero: Reinforced Self-play Reasoning with Zero Data
May 07, 2025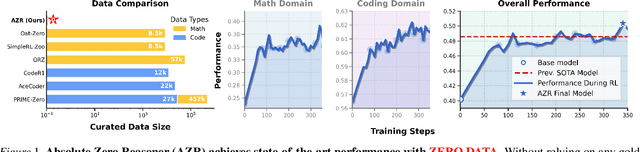
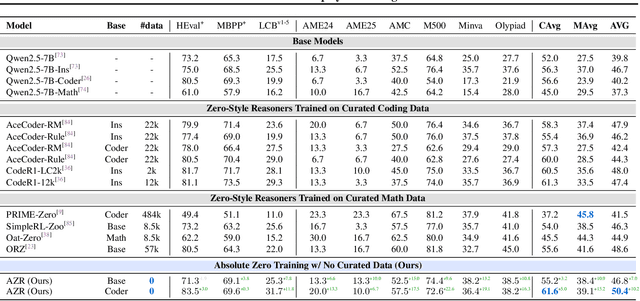

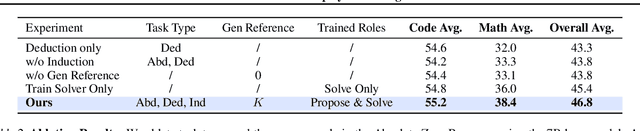
Reinforcement learning with verifiable rewards (RLVR) has shown promise in enhancing the reasoning capabilities of large language models by learning directly from outcome-based rewards. Recent RLVR works that operate under the zero setting avoid supervision in labeling the reasoning process, but still depend on manually curated collections of questions and answers for training. The scarcity of high-quality, human-produced examples raises concerns about the long-term scalability of relying on human supervision, a challenge already evident in the domain of language model pretraining. Furthermore, in a hypothetical future where AI surpasses human intelligence, tasks provided by humans may offer limited learning potential for a superintelligent system. To address these concerns, we propose a new RLVR paradigm called Absolute Zero, in which a single model learns to propose tasks that maximize its own learning progress and improves reasoning by solving them, without relying on any external data. Under this paradigm, we introduce the Absolute Zero Reasoner (AZR), a system that self-evolves its training curriculum and reasoning ability by using a code executor to both validate proposed code reasoning tasks and verify answers, serving as an unified source of verifiable reward to guide open-ended yet grounded learning. Despite being trained entirely without external data, AZR achieves overall SOTA performance on coding and mathematical reasoning tasks, outperforming existing zero-setting models that rely on tens of thousands of in-domain human-curated examples. Furthermore, we demonstrate that AZR can be effectively applied across different model scales and is compatible with various model classes.
Divide, Optimize, Merge: Fine-Grained LLM Agent Optimization at Scale
May 06, 2025LLM-based optimization has shown remarkable potential in enhancing agentic systems. However, the conventional approach of prompting LLM optimizer with the whole training trajectories on training dataset in a single pass becomes untenable as datasets grow, leading to context window overflow and degraded pattern recognition. To address these challenges, we propose Fine-Grained Optimization (FGO), a scalable framework that divides large optimization tasks into manageable subsets, performs targeted optimizations, and systematically combines optimized components through progressive merging. Evaluation across ALFWorld, LogisticsQA, and GAIA benchmarks demonstrate that FGO outperforms existing approaches by 1.6-8.6% while reducing average prompt token consumption by 56.3%. Our framework provides a practical solution for scaling up LLM-based optimization of increasingly sophisticated agent systems. Further analysis demonstrates that FGO achieves the most consistent performance gain in all training dataset sizes, showcasing its scalability and efficiency.