 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Complexity Distributed Combining Design for Near-Field Cell-Free XL-MIMO Systems
Feb 03, 2026In this paper, we investigate the low-complexity distributed combining scheme design for near-field cell-free extremely large-scale multiple-input-multiple-output (CF XL-MIMO) systems. Firstly, we construct the uplink spectral efficiency (SE) performance analysis framework for CF XL-MIMO systems over centralized and distributed processing schemes. Notably, we derive the centralized minimum mean-square error (CMMSE) and local minimum mean-square error (LMMSE) combining schemes over arbitrary channel estimators. Then, focusing on the CMMSE and LMMSE combining schemes, we propose five low-complexity distributed combining schemes based on the matrix approximation methodology or the symmetric successive over relaxation (SSOR) algorithm. More specifically, we propose two matrix approximation methodology-aided combining schemes: Global Statistics \& Local Instantaneous information-based MMSE (GSLI-MMSE) and Statistics matrix Inversion-based LMMSE (SI-LMMSE). These two schemes are derived by approximating the global instantaneous information in the CMMSE combining and the local instantaneous information in the LMMSE combining with the global and local statistics information by asymptotic analysis and matrix expectation approximation, respectively. Moreover, by applying the low-complexity SSOR algorithm to iteratively solve the matrix inversion in the LMMSE combining, we derive three distributed SSOR-based LMMSE combining schemes, distinguished from the applied information and initial values.
AOrchestra: Automating Sub-Agent Creation for Agentic Orchestration
Feb 03, 2026Language agents have shown strong promise for task automation. Realizing this promise for increasingly complex, long-horizon tasks has driven the rise of a sub-agent-as-tools paradigm for multi-turn task solving. However, existing designs still lack a dynamic abstraction view of sub-agents, thereby hurting adaptability. We address this challenge with a unified, framework-agnostic agent abstraction that models any agent as a tuple Instruction, Context, Tools, Model. This tuple acts as a compositional recipe for capabilities, enabling the system to spawn specialized executors for each task on demand. Building on this abstraction, we introduce an agentic system AOrchestra, where the central orchestrator concretizes the tuple at each step: it curates task-relevant context, selects tools and models, and delegates execution via on-the-fly automatic agent creation. Such designs enable reducing human engineering efforts, and remain framework-agnostic with plug-and-play support for diverse agents as task executors. It also enables a controllable performance-cost trade-off, allowing the system to approach Pareto-efficient. Across three challenging benchmarks (GAIA, SWE-Bench, Terminal-Bench), AOrchestra achieves 16.28% relative improvement against the strongest baseline when paired with Gemini-3-Flash. The code is available at: https://github.com/FoundationAgents/AOrchestra
Statistics Approximation-Enabled Distributed Beamforming for Cell-Free Massive MIMO
Feb 03, 2026We study a distributed beamforming approach for cell-free massive multiple-input multiple-output networks, referred to as Global Statistics \& Local Instantaneous information-based minimum mean-square error (GSLI-MMSE). The scenario with multi-antenna access points (APs) is considered over three different channel models: correlated Rician fading with fixed or random line-of-sight (LoS) phase-shifts, and correlated Rayleigh fading. With the aid of matrix inversion derivations, we can construct the conventional MMSE combining from the perspective of each AP, where global instantaneous information is involved. Then, for an arbitrary AP, we apply the statistics approximation methodology to approximate instantaneous terms related to other APs by channel statistics to construct the distributed combining scheme at each AP with local instantaneous information and global statistics. With the aid of uplink-downlink duality, we derive the respective GSLI-MMSE precoding schemes. Numerical results showcase that the proposed GSLI-MMSE scheme demonstrates performance comparable to the optimal centralized MMSE scheme, under the stable LoS conditions, e.g., with static users having Rician fading with a fixed LoS path.
Low-Complexity Multi-Agent Continual Learning for Stacked Intelligent Metasurface-Assisted Secure Communications
Feb 02, 2026Stacked intelligent metasurfaces (SIMs), composed of multiple layers of reconfigurable transmissive metasurfaces, are gaining prominence as a transformative technology for future wireless communication security. This paper investigates the integration of SIM into multi-user multiple-input multiple-output (MIMO) systems to enhance physical layer security. A novel system architecture is proposed, wherein each base station (BS) antenna transmits a dedicated single-user stream, while a multi-layer SIM executes wave-based beamforming in the electromagnetic domain, thereby avoiding the need for complex baseband digital precoding and significantly reducing hardware overhead. To maximize the weighted sum secrecy rate (WSSR), we formulate a joint precoding optimization problem over BS power allocation and SIM phase shifts, which is high-dimensional and non-convex due to the complexity of the objective function and the coupling among optimization variables. To address this, we propose a manifold-enhanced heterogeneous multi-agent continual learning (MHACL) framework that incorporates gradient representation and dual-scale policy optimization to achieve robust performance in dynamic environments with high demands for secure communication. Furthermore, we develop SIM-MHACL (SIMHACL), a low-complexity learning template that embeds phase coordination into a product manifold structure, reducing the exponential search space to linear complexity while maintaining physical feasibility. Simulation results validate that the proposed framework achieves millisecond-level per-iteratio ntraining in SIM-assisted systems, significantly outperforming various baseline schemes, with SIMHACL achieving comparable WSSR to MHACL while reducing computation time by 30\%.
XGuardian: Towards Explainable and Generalized AI Anti-Cheat on FPS Games
Jan 26, 2026Aim-assist cheats are the most prevalent and infamous form of cheating in First-Person Shooter (FPS) games, which help cheaters illegally reveal the opponent's location and auto-aim and shoot, and thereby pose significant threats to the game industry. Although a considerable research effort has been made to automatically detect aim-assist cheats, existing works suffer from unreliable frameworks, limited generalizability, high overhead, low detection performance, and a lack of explainability of detection results. In this paper, we propose XGuardian, a server-side generalized and explainable system for detecting aim-assist cheats to overcome these limitations. It requires only two raw data inputs, pitch and yaw, which are all FPS games' must-haves, to construct novel temporal features and describe aim trajectories, which are essential for distinguishing cheaters and normal players. XGuardian is evaluated with the latest mainstream FPS game CS2, and validates its generalizability with another two different games. It achieves high detection performance and low overhead compared to prior works across different games with real-world and large-scale datasets, demonstrating wide generalizability and high effectiveness. It is able to justify its predictions and thereby shorten the ban cycle. We make XGuardian as well as our datasets publicly available.
Using Large Language Models to Detect Socially Shared Regulation of Collaborative Learning
Jan 08, 2026The field of learning analytics has made notable strides in automating the detection of complex learning processes in multimodal data. However, most advancements have focused on individualized problem-solving instead of collaborative, open-ended problem-solving, which may offer both affordances (richer data) and challenges (low cohesion) to behavioral prediction. Here, we extend predictive models to automatically detect socially shared regulation of learning (SSRL) behaviors in collaborative computational modeling environments using embedding-based approaches. We leverage large language models (LLMs) as summarization tools to generate task-aware representations of student dialogue aligned with system logs. These summaries, combined with text-only embeddings, context-enriched embeddings, and log-derived features, were used to train predictive models. Results show that text-only embeddings often achieve stronger performance in detecting SSRL behaviors related to enactment or group dynamics (e.g., off-task behavior or requesting assistance). In contrast, contextual and multimodal features provide complementary benefits for constructs such as planning and reflection. Overall, our findings highlight the promise of embedding-based models for extending learning analytics by enabling scalable detection of SSRL behaviors, ultimately supporting real-time feedback and adaptive scaffolding in collaborative learning environments that teachers value.
Decoding Human and AI Persuasion in National College Debate: Analyzing Prepared Arguments Through Aristotle's Rhetorical Principles
Dec 14, 2025Debate has been widely adopted as a strategy to enhance critical thinking skills in English Language Arts (ELA). One important skill in debate is forming effective argumentation, which requires debaters to select supportive evidence from literature and construct compelling claims. However, the training of this skill largely depends on human coaching, which is labor-intensive and difficult to scale. To better support students in preparing for debates, this study explores the potential of leveraging artificial intelligence to generate effective arguments. Specifically, we prompted GPT-4 to create an evidence card and compared it to those produced by human debaters. The evidence cards outline the arguments students will present and how those arguments will be delivered, including components such as literature-based evidence quotations, summaries of core ideas, verbatim reading scripts, and tags (i.e., titles of the arguments). We compared the quality of the arguments in the evidence cards created by GPT and student debaters using Aristotle's rhetorical principles: ethos (credibility), pathos (emotional appeal), and logos (logical reasoning). Through a systematic qualitative and quantitative analysis, grounded in the rhetorical principles, we identify the strengths and limitations of human and GPT in debate reasoning, outlining areas where AI's focus and justifications align with or diverge from human reasoning. Our findings contribute to the evolving role of AI-assisted learning interventions, offering insights into how student debaters can develop strategies that enhance their argumentation and reasoning skills.
Reasoning via Video: The First Evaluation of Video Models' Reasoning Abilities through Maze-Solving Tasks
Nov 19, 2025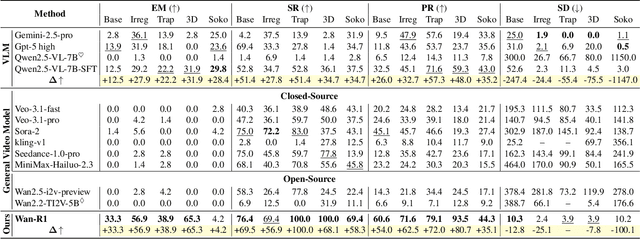

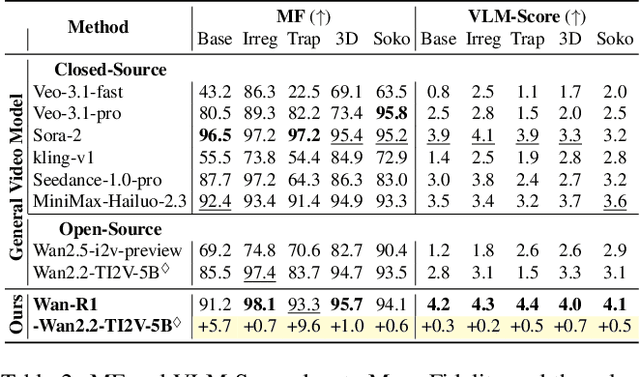
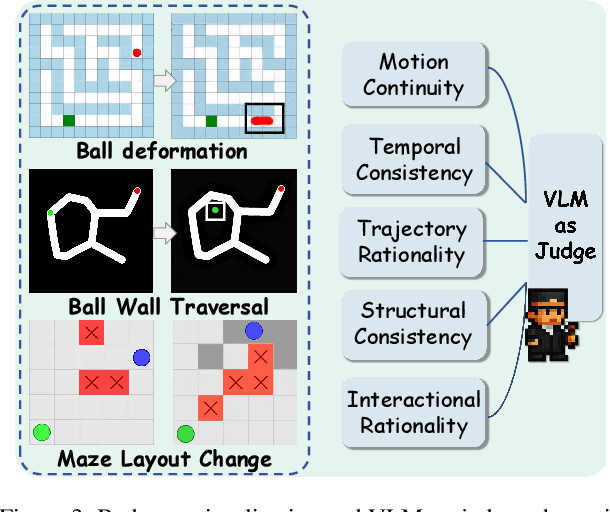
Video Models have achieved remarkable success in high-fidelity video generation with coherent motion dynamics. Analogous to the development from text generation to text-based reasoning in language modeling, the development of video models motivates us to ask: Can video models reason via video generation? Compared with the discrete text corpus, video grounds reasoning in explicit spatial layouts and temporal continuity, which serves as an ideal substrate for spatial reasoning. In this work, we explore the reasoning via video paradigm and introduce VR-Bench -- a comprehensive benchmark designed to systematically evaluate video models' reasoning capabilities. Grounded in maze-solving tasks that inherently require spatial planning and multi-step reasoning, VR-Bench contains 7,920 procedurally generated videos across five maze types and diverse visual styles. Our empirical analysis demonstrates that SFT can efficiently elicit the reasoning ability of video model. Video models exhibit stronger spatial perception during reasoning, outperforming leading VLMs and generalizing well across diverse scenarios, tasks, and levels of complexity. We further discover a test-time scaling effect, where diverse sampling during inference improves reasoning reliability by 10--20%. These findings highlight the unique potential and scalability of reasoning via video for spatial reasoning tasks.
Opinion: Towards Unified Expressive Policy Optimization for Robust Robot Learning
Nov 13, 2025

Offline-to-online reinforcement learning (O2O-RL) has emerged as a promising paradigm for safe and efficient robotic policy deployment but suffers from two fundamental challenges: limited coverage of multimodal behaviors and distributional shifts during online adaptation. We propose UEPO, a unified generative framework inspired by large language model pretraining and fine-tuning strategies. Our contributions are threefold: (1) a multi-seed dynamics-aware diffusion policy that efficiently captures diverse modalities without training multiple models; (2) a dynamic divergence regularization mechanism that enforces physically meaningful policy diversity; and (3) a diffusion-based data augmentation module that enhances dynamics model generalization. On the D4RL benchmark, UEPO achieves +5.9\% absolute improvement over Uni-O4 on locomotion tasks and +12.4\% on dexterous manipulation, demonstrating strong generalization and scalability.
Multi-modal Dynamic Proxy Learning for Personalized Multiple Clustering
Nov 10, 2025Multiple clustering aims to discover diverse latent structures from different perspectives, yet existing methods generate exhaustive clusterings without discerning user interest, necessitating laborious manual screening. Current multi-modal solutions suffer from static semantic rigidity: predefined candidate words fail to adapt to dataset-specific concepts, and fixed fusion strategies ignore evolving feature interactions. To overcome these limitations, we propose Multi-DProxy, a novel multi-modal dynamic proxy learning framework that leverages cross-modal alignment through learnable textual proxies. Multi-DProxy introduces 1) gated cross-modal fusion that synthesizes discriminative joint representations by adaptively modeling feature interactions. 2) dual-constraint proxy optimization where user interest constraints enforce semantic consistency with domain concepts while concept constraints employ hard example mining to enhance cluster discrimination. 3) dynamic candidate management that refines textual proxies through iterative clustering feedback. Therefore, Multi-DProxy not only effectively captures a user's interest through proxies but also enables the identification of relevant clusterings with greater precision. Extensive experiments demonstrate state-of-the-art performance with significant improvements over existing methods across a broad set of multi-clustering benchmarks.