 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKunlun: Establishing Scaling Laws for Massive-Scale Recommendation Systems through Unified Architecture Design
Feb 13, 2026Deriving predictable scaling laws that govern the relationship between model performance and computational investment is crucial for designing and allocating resources in massive-scale recommendation systems. While such laws are established for large language models, they remain challenging for recommendation systems, especially those processing both user history and context features. We identify poor scaling efficiency as the main barrier to predictable power-law scaling, stemming from inefficient modules with low Model FLOPs Utilization (MFU) and suboptimal resource allocation. We introduce Kunlun, a scalable architecture that systematically improves model efficiency and resource allocation. Our low-level optimizations include Generalized Dot-Product Attention (GDPA), Hierarchical Seed Pooling (HSP), and Sliding Window Attention. Our high-level innovations feature Computation Skip (CompSkip) and Event-level Personalization. These advances increase MFU from 17% to 37% on NVIDIA B200 GPUs and double scaling efficiency over state-of-the-art methods. Kunlun is now deployed in major Meta Ads models, delivering significant production impact.
External Large Foundation Model: How to Efficiently Serve Trillions of Parameters for Online Ads Recommendation
Feb 26, 2025



Ads recommendation is a prominent service of online advertising systems and has been actively studied. Recent studies indicate that scaling-up and advanced design of the recommendation model can bring significant performance improvement. However, with a larger model scale, such prior studies have a significantly increasing gap from industry as they often neglect two fundamental challenges in industrial-scale applications. First, training and inference budgets are restricted for the model to be served, exceeding which may incur latency and impair user experience. Second, large-volume data arrive in a streaming mode with data distributions dynamically shifting, as new users/ads join and existing users/ads leave the system. We propose the External Large Foundation Model (ExFM) framework to address the overlooked challenges. Specifically, we develop external distillation and a data augmentation system (DAS) to control the computational cost of training/inference while maintaining high performance. We design the teacher in a way like a foundation model (FM) that can serve multiple students as vertical models (VMs) to amortize its building cost. We propose Auxiliary Head and Student Adapter to mitigate the data distribution gap between FM and VMs caused by the streaming data issue. Comprehensive experiments on internal industrial-scale applications and public datasets demonstrate significant performance gain by ExFM.
Meta-Learning with Less Forgetting on Large-Scale Non-Stationary Task Distributions
Sep 03, 2022

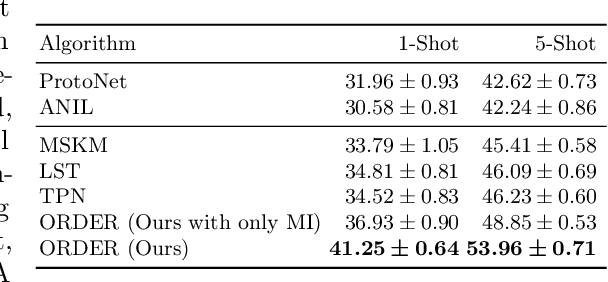
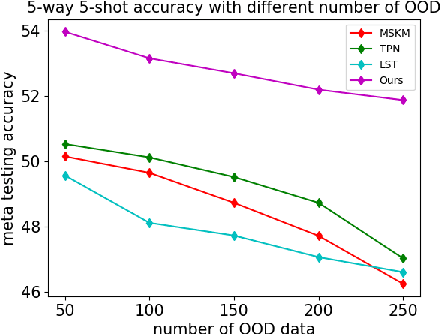
The paradigm of machine intelligence moves from purely supervised learning to a more practical scenario when many loosely related unlabeled data are available and labeled data is scarce. Most existing algorithms assume that the underlying task distribution is stationary. Here we consider a more realistic and challenging setting in that task distributions evolve over time. We name this problem as Semi-supervised meta-learning with Evolving Task diStributions, abbreviated as SETS. Two key challenges arise in this more realistic setting: (i) how to use unlabeled data in the presence of a large amount of unlabeled out-of-distribution (OOD) data; and (ii) how to prevent catastrophic forgetting on previously learned task distributions due to the task distribution shift. We propose an OOD Robust and knowleDge presErved semi-supeRvised meta-learning approach (ORDER), to tackle these two major challenges. Specifically, our ORDER introduces a novel mutual information regularization to robustify the model with unlabeled OOD data and adopts an optimal transport regularization to remember previously learned knowledge in feature space. In addition, we test our method on a very challenging dataset: SETS on large-scale non-stationary semi-supervised task distributions consisting of (at least) 72K tasks. With extensive experiments, we demonstrate the proposed ORDER alleviates forgetting on evolving task distributions and is more robust to OOD data than related strong baselines.
Improving Task-free Continual Learning by Distributionally Robust Memory Evolution
Jul 15, 2022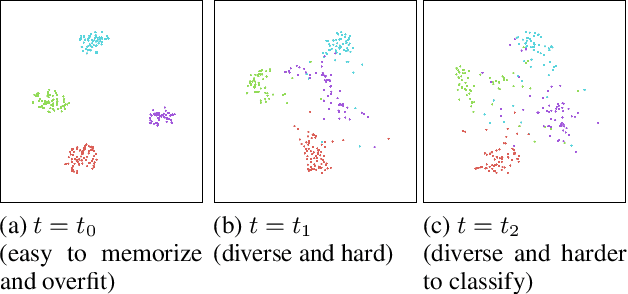
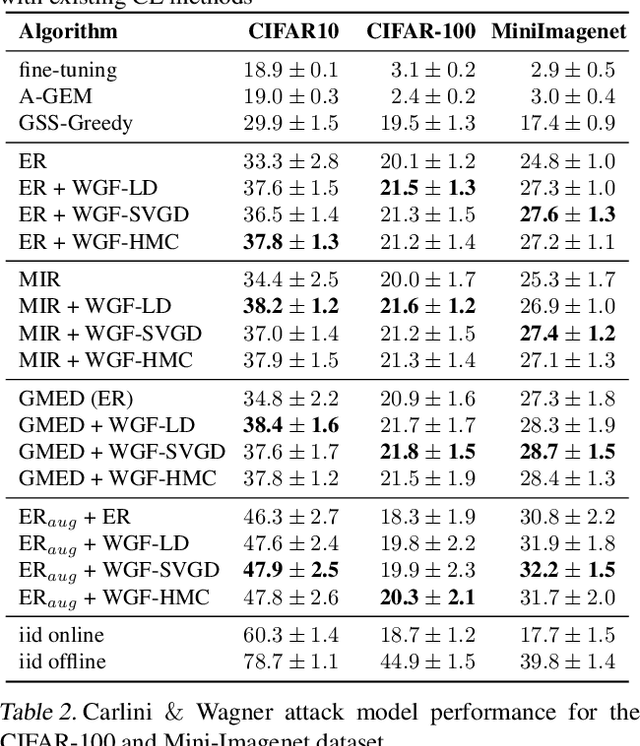
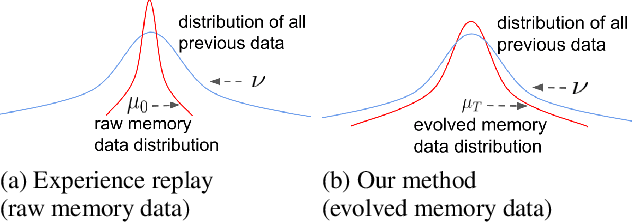
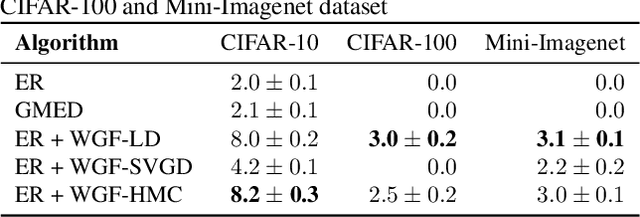
Task-free continual learning (CL) aims to learn a non-stationary data stream without explicit task definitions and not forget previous knowledge. The widely adopted memory replay approach could gradually become less effective for long data streams, as the model may memorize the stored examples and overfit the memory buffer. Second, existing methods overlook the high uncertainty in the memory data distribution since there is a big gap between the memory data distribution and the distribution of all the previous data examples. To address these problems, for the first time, we propose a principled memory evolution framework to dynamically evolve the memory data distribution by making the memory buffer gradually harder to be memorized with distributionally robust optimization (DRO). We then derive a family of methods to evolve the memory buffer data in the continuous probability measure space with Wasserstein gradient flow (WGF). The proposed DRO is w.r.t the worst-case evolved memory data distribution, thus guarantees the model performance and learns significantly more robust features than existing memory-replay-based methods. Extensive experiments on existing benchmarks demonstrate the effectiveness of the proposed methods for alleviating forgetting. As a by-product of the proposed framework, our method is more robust to adversarial examples than existing task-free CL methods.
Meta Learning on a Sequence of Imbalanced Domains with Difficulty Awareness
Sep 29, 2021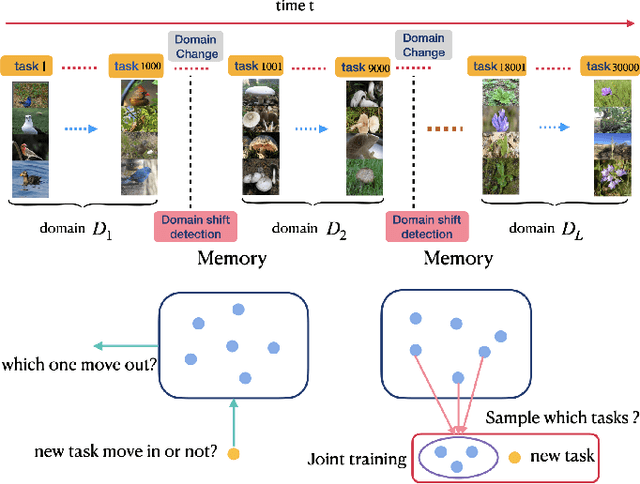
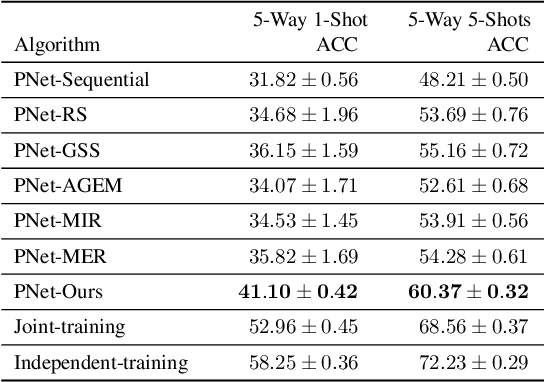
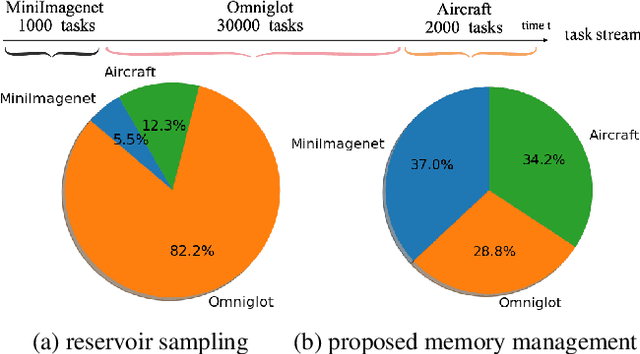
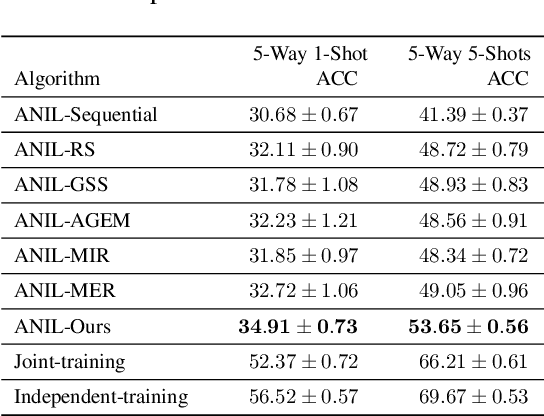
Recognizing new objects by learning from a few labeled examples in an evolving environment is crucial to obtain excellent generalization ability for real-world machine learning systems. A typical setting across current meta learning algorithms assumes a stationary task distribution during meta training. In this paper, we explore a more practical and challenging setting where task distribution changes over time with domain shift. Particularly, we consider realistic scenarios where task distribution is highly imbalanced with domain labels unavailable in nature. We propose a kernel-based method for domain change detection and a difficulty-aware memory management mechanism that jointly considers the imbalanced domain size and domain importance to learn across domains continuously. Furthermore, we introduce an efficient adaptive task sampling method during meta training, which significantly reduces task gradient variance with theoretical guarantees. Finally, we propose a challenging benchmark with imbalanced domain sequences and varied domain difficulty. We have performed extensive evaluations on the proposed benchmark, demonstrating the effectiveness of our method. We made our code publicly available.