 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairLLaVA: Fairness-Aware Parameter-Efficient Fine-Tuning for Large Vision-Language Assistants
Mar 27, 2026While powerful in image-conditioned generation, multimodal large language models (MLLMs) can display uneven performance across demographic groups, highlighting fairness risks. In safety-critical clinical settings, such disparities risk producing unequal diagnostic narratives and eroding trust in AI-assisted decision-making. While fairness has been studied extensively in vision-only and language-only models, its impact on MLLMs remains largely underexplored. To address these biases, we introduce FairLLaVA, a parameter-efficient fine-tuning method that mitigates group disparities in visual instruction tuning without compromising overall performance. By minimizing the mutual information between target attributes, FairLLaVA regularizes the model's representations to be demographic-invariant. The method can be incorporated as a lightweight plug-in, maintaining efficiency with low-rank adapter fine-tuning, and provides an architecture-agnostic approach to fair visual instruction following. Extensive experiments on large-scale chest radiology report generation and dermoscopy visual question answering benchmarks show that FairLLaVA consistently reduces inter-group disparities while improving both equity-scaled clinical performance and natural language generation quality across diverse medical imaging modalities. Code can be accessed at https://github.com/bhosalems/FairLLaVA.
Refining 3D Medical Segmentation with Verbal Instruction
Mar 15, 2026Accurate 3D anatomical segmentation is essential for clinical diagnosis and surgical planning. However, automated models frequently generate suboptimal shape predictions due to factors such as limited and imbalanced training data, inadequate labeling quality, and distribution shifts between training and deployment settings. A natural solution is to iteratively refine the predicted shape based on the radiologists' verbal instructions. However, this is hindered by the scarcity of paired data that explicitly links erroneous shapes to corresponding corrective instructions. As an initial step toward addressing this limitation, we introduce CoWTalk, a benchmark comprising 3D arterial anatomies with controllable synthesized anatomical errors and their corresponding repairing instructions. Building on this benchmark, we further propose an iterative refinement model that represents 3D shapes as vector sets and interacts with textual instructions to progressively update the target shape. Experimental results demonstrate that our method achieves significant improvements over corrupted inputs and competitive baselines, highlighting the feasibility of language-driven clinician-in-the-loop refinement for 3D medical shapes modeling.
Volumetric Directional Diffusion: Anchoring Uncertainty Quantification in Anatomical Consensus for Ambiguous Medical Image Segmentation
Mar 04, 2026Equivocal 3D lesion segmentation exhibits high inter-observer variability. Conventional deterministic models ignore this aleatoric uncertainty, producing over-confident masks that obscure clinical risks. Conversely, while generative methods (e.g., standard diffusion) capture sample diversity, recovering complex topology from pure noise frequently leads to severe structural fractures and out-of-distribution anatomical hallucinations. To resolve this fidelity-diversity trade-off, we propose Volumetric Directional Diffusion (VDD). Unlike standard diffusion models that denoise isotropic Gaussian noise, VDD mathematically anchors the generative trajectory to a deterministic consensus prior. By restricting the generative search space to iteratively predict a 3D boundary residual field, VDD accurately explores the fine-grained geometric variations inherent in expert disagreements without risking topological collapse. Extensive validation on three multi-rater datasets (LIDC-IDRI, KiTS21, and ISBI 2015) demonstrates that VDD achieves state-of-the-art uncertainty quantification (significantly improving GED and CI) while remaining highly competitive in segmentation accuracy against deterministic upper bounds. Ultimately, VDD provides clinicians with anatomically coherent uncertainty maps, enabling safer decision-making and mitigating risks in downstream tasks (e.g., radiotherapy planning or surgical margin assessment).
From Efficiency to Adaptivity: A Deeper Look at Adaptive Reasoning in Large Language Models
Nov 13, 2025
Recent advances in large language models (LLMs) have made reasoning a central benchmark for evaluating intelligence. While prior surveys focus on efficiency by examining how to shorten reasoning chains or reduce computation, this view overlooks a fundamental challenge: current LLMs apply uniform reasoning strategies regardless of task complexity, generating long traces for trivial problems while failing to extend reasoning for difficult tasks. This survey reframes reasoning through the lens of {adaptivity}: the capability to allocate reasoning effort based on input characteristics such as difficulty and uncertainty. We make three contributions. First, we formalize deductive, inductive, and abductive reasoning within the LLM context, connecting these classical cognitive paradigms with their algorithmic realizations. Second, we formalize adaptive reasoning as a control-augmented policy optimization problem balancing task performance with computational cost, distinguishing learned policies from inference-time control mechanisms. Third, we propose a systematic taxonomy organizing existing methods into training-based approaches that internalize adaptivity through reinforcement learning, supervised fine-tuning, and learned controllers, and training-free approaches that achieve adaptivity through prompt conditioning, feedback-driven halting, and modular composition. This framework clarifies how different mechanisms realize adaptive reasoning in practice and enables systematic comparison across diverse strategies. We conclude by identifying open challenges in self-evaluation, meta-reasoning, and human-aligned reasoning control.
Model-Agnostic Gender Bias Control for Text-to-Image Generation via Sparse Autoencoder
Jul 28, 2025



Text-to-image (T2I) diffusion models often exhibit gender bias, particularly by generating stereotypical associations between professions and gendered subjects. This paper presents SAE Debias, a lightweight and model-agnostic framework for mitigating such bias in T2I generation. Unlike prior approaches that rely on CLIP-based filtering or prompt engineering, which often require model-specific adjustments and offer limited control, SAE Debias operates directly within the feature space without retraining or architectural modifications. By leveraging a k-sparse autoencoder pre-trained on a gender bias dataset, the method identifies gender-relevant directions within the sparse latent space, capturing professional stereotypes. Specifically, a biased direction per profession is constructed from sparse latents and suppressed during inference to steer generations toward more gender-balanced outputs. Trained only once, the sparse autoencoder provides a reusable debiasing direction, offering effective control and interpretable insight into biased subspaces. Extensive evaluations across multiple T2I models, including Stable Diffusion 1.4, 1.5, 2.1, and SDXL, demonstrate that SAE Debias substantially reduces gender bias while preserving generation quality. To the best of our knowledge, this is the first work to apply sparse autoencoders for identifying and intervening in gender bias within T2I models. These findings contribute toward building socially responsible generative AI, providing an interpretable and model-agnostic tool to support fairness in text-to-image generation.
Template-Guided Reconstruction of Pulmonary Segments with Neural Implicit Functions
May 13, 2025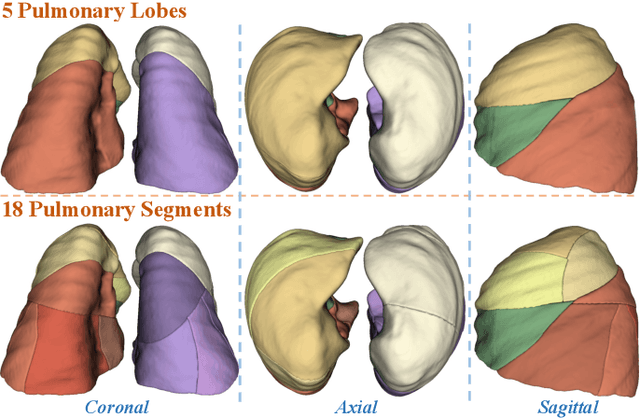
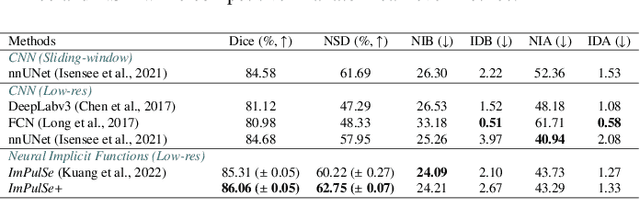
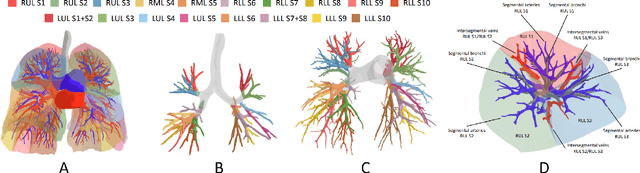
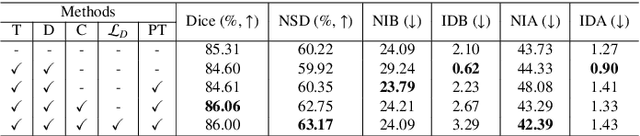
High-quality 3D reconstruction of pulmonary segments plays a crucial role in segmentectomy and surgical treatment planning for lung cancer. Due to the resolution requirement of the target reconstruction, conventional deep learning-based methods often suffer from computational resource constraints or limited granularity. Conversely, implicit modeling is favored due to its computational efficiency and continuous representation at any resolution. We propose a neural implicit function-based method to learn a 3D surface to achieve anatomy-aware, precise pulmonary segment reconstruction, represented as a shape by deforming a learnable template. Additionally, we introduce two clinically relevant evaluation metrics to assess the reconstruction comprehensively. Further, due to the absence of publicly available shape datasets to benchmark reconstruction algorithms, we developed a shape dataset named Lung3D, including the 3D models of 800 labeled pulmonary segments and the corresponding airways, arteries, veins, and intersegmental veins. We demonstrate that the proposed approach outperforms existing methods, providing a new perspective for pulmonary segment reconstruction. Code and data will be available at https://github.com/M3DV/ImPulSe.
Vision-Language Model Based Handwriting Verification
Jul 31, 2024

Handwriting Verification is a critical in document forensics. Deep learning based approaches often face skepticism from forensic document examiners due to their lack of explainability and reliance on extensive training data and handcrafted features. This paper explores using Vision Language Models (VLMs), such as OpenAI's GPT-4o and Google's PaliGemma, to address these challenges. By leveraging their Visual Question Answering capabilities and 0-shot Chain-of-Thought (CoT) reasoning, our goal is to provide clear, human-understandable explanations for model decisions. Our experiments on the CEDAR handwriting dataset demonstrate that VLMs offer enhanced interpretability, reduce the need for large training datasets, and adapt better to diverse handwriting styles. However, results show that the CNN-based ResNet-18 architecture outperforms the 0-shot CoT prompt engineering approach with GPT-4o (Accuracy: 70%) and supervised fine-tuned PaliGemma (Accuracy: 71%), achieving an accuracy of 84% on the CEDAR AND dataset. These findings highlight the potential of VLMs in generating human-interpretable decisions while underscoring the need for further advancements to match the performance of specialized deep learning models.
Self-Supervised Learning Based Handwriting Verification
May 28, 2024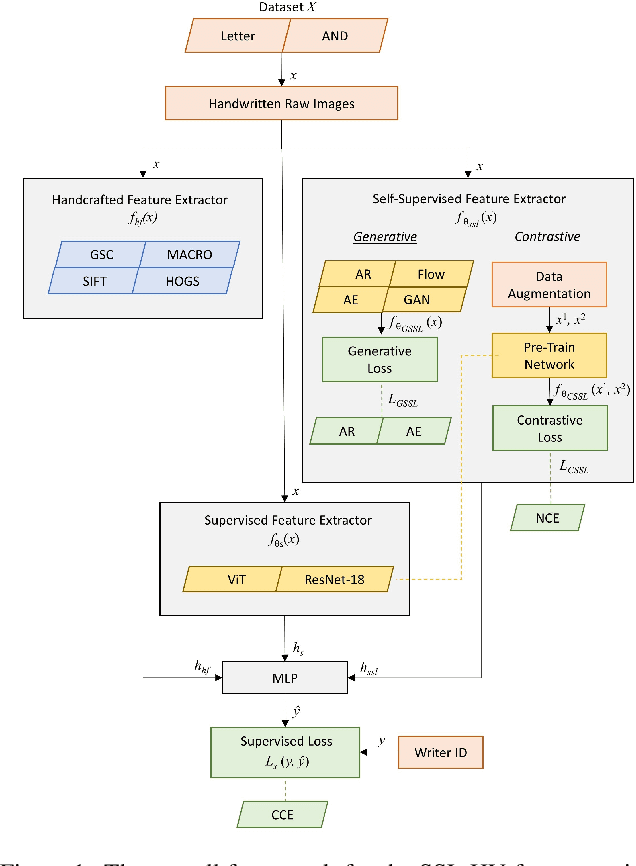
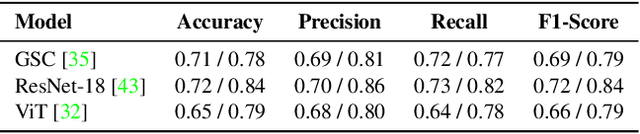
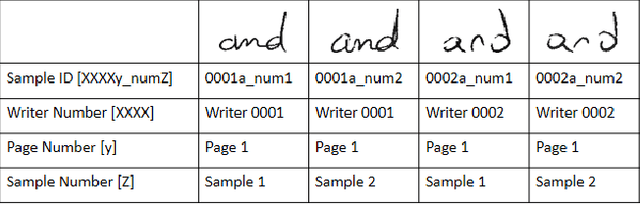

We present SSL-HV: Self-Supervised Learning approaches applied to the task of Handwriting Verification. This task involves determining whether a given pair of handwritten images originate from the same or different writer distribution. We have compared the performance of multiple generative, contrastive SSL approaches against handcrafted feature extractors and supervised learning on CEDAR AND dataset. We show that ResNet based Variational Auto-Encoder (VAE) outperforms other generative approaches achieving 76.3% accuracy, while ResNet-18 fine-tuned using Variance-Invariance-Covariance Regularization (VICReg) outperforms other contrastive approaches achieving 78% accuracy. Using a pre-trained VAE and VICReg for the downstream task of writer verification we observed a relative improvement in accuracy of 6.7% and 9% over ResNet-18 supervised baseline with 10% writer labels.
Looking Beyond What You See: An Empirical Analysis on Subgroup Intersectional Fairness for Multi-label Chest X-ray Classification Using Social Determinants of Racial Health Inequities
Mar 27, 2024There has been significant progress in implementing deep learning models in disease diagnosis using chest X- rays. Despite these advancements, inherent biases in these models can lead to disparities in prediction accuracy across protected groups. In this study, we propose a framework to achieve accurate diagnostic outcomes and ensure fairness across intersectional groups in high-dimensional chest X- ray multi-label classification. Transcending traditional protected attributes, we consider complex interactions within social determinants, enabling a more granular benchmark and evaluation of fairness. We present a simple and robust method that involves retraining the last classification layer of pre-trained models using a balanced dataset across groups. Additionally, we account for fairness constraints and integrate class-balanced fine-tuning for multi-label settings. The evaluation of our method on the MIMIC-CXR dataset demonstrates that our framework achieves an optimal tradeoff between accuracy and fairness compared to baseline methods.
Continual Domain Adversarial Adaptation via Double-Head Discriminators
Feb 05, 2024Domain adversarial adaptation in a continual setting poses a significant challenge due to the limitations on accessing previous source domain data. Despite extensive research in continual learning, the task of adversarial adaptation cannot be effectively accomplished using only a small number of stored source domain data, which is a standard setting in memory replay approaches. This limitation arises from the erroneous empirical estimation of $\gH$-divergence with few source domain samples. To tackle this problem, we propose a double-head discriminator algorithm, by introducing an addition source-only domain discriminator that are trained solely on source learning phase. We prove that with the introduction of a pre-trained source-only domain discriminator, the empirical estimation error of $\gH$-divergence related adversarial loss is reduced from the source domain side. Further experiments on existing domain adaptation benchmark show that our proposed algorithm achieves more than 2$\%$ improvement on all categories of target domain adaptation task while significantly mitigating the forgetting on source domain.