 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnmasking Societal Biases in Respiratory Support for ICU Patients through Social Determinants of Health
Feb 23, 2025In critical care settings, where precise and timely interventions are crucial for health outcomes, evaluating disparities in patient outcomes is essential. Current approaches often fail to fully capture the impact of respiratory support interventions on individuals affected by social determinants of health. While attributes such as gender, race, and age are commonly assessed and provide valuable insights, they offer only a partial view of the complexities faced by diverse populations. In this study, we focus on two clinically motivated tasks: prolonged mechanical ventilation and successful weaning. Additionally, we conduct fairness audits on the models' predictions across demographic groups and social determinants of health to better understand health inequities in respiratory interventions within the intensive care unit. Furthermore, we release a temporal benchmark dataset, verified by clinical experts, to facilitate benchmarking of clinical respiratory intervention tasks.
Looking Beyond What You See: An Empirical Analysis on Subgroup Intersectional Fairness for Multi-label Chest X-ray Classification Using Social Determinants of Racial Health Inequities
Mar 27, 2024There has been significant progress in implementing deep learning models in disease diagnosis using chest X- rays. Despite these advancements, inherent biases in these models can lead to disparities in prediction accuracy across protected groups. In this study, we propose a framework to achieve accurate diagnostic outcomes and ensure fairness across intersectional groups in high-dimensional chest X- ray multi-label classification. Transcending traditional protected attributes, we consider complex interactions within social determinants, enabling a more granular benchmark and evaluation of fairness. We present a simple and robust method that involves retraining the last classification layer of pre-trained models using a balanced dataset across groups. Additionally, we account for fairness constraints and integrate class-balanced fine-tuning for multi-label settings. The evaluation of our method on the MIMIC-CXR dataset demonstrates that our framework achieves an optimal tradeoff between accuracy and fairness compared to baseline methods.
DengueNet: Dengue Prediction using Spatiotemporal Satellite Imagery for Resource-Limited Countries
Jan 23, 2024



Dengue fever presents a substantial challenge in developing countries where sanitation infrastructure is inadequate. The absence of comprehensive healthcare systems exacerbates the severity of dengue infections, potentially leading to life-threatening circumstances. Rapid response to dengue outbreaks is also challenging due to limited information exchange and integration. While timely dengue outbreak forecasts have the potential to prevent such outbreaks, the majority of dengue prediction studies have predominantly relied on data that impose significant burdens on individual countries for collection. In this study, our aim is to improve health equity in resource-constrained countries by exploring the effectiveness of high-resolution satellite imagery as a nontraditional and readily accessible data source. By leveraging the wealth of publicly available and easily obtainable satellite imagery, we present a scalable satellite extraction framework based on Sentinel Hub, a cloud-based computing platform. Furthermore, we introduce DengueNet, an innovative architecture that combines Vision Transformer, Radiomics, and Long Short-term Memory to extract and integrate spatiotemporal features from satellite images. This enables dengue predictions on an epi-week basis. To evaluate the effectiveness of our proposed method, we conducted experiments on five municipalities in Colombia. We utilized a dataset comprising 780 high-resolution Sentinel-2 satellite images for training and evaluation. The performance of DengueNet was assessed using the mean absolute error (MAE) metric. Across the five municipalities, DengueNet achieved an average MAE of 43.92. Our findings strongly support the efficacy of satellite imagery as a valuable resource for dengue prediction, particularly in informing public health policies within countries where manually collected data is scarce and dengue virus prevalence is severe.
Early Diagnosis of Chronic Obstructive Pulmonary Disease from Chest X-Rays using Transfer Learning and Fusion Strategies
Nov 13, 2022Chronic obstructive pulmonary disease (COPD) is one of the most common chronic illnesses in the world and the third leading cause of mortality worldwide. It is often underdiagnosed or not diagnosed until later in the disease course. Spirometry tests are the gold standard for diagnosing COPD but can be difficult to obtain, especially in resource-poor countries. Chest X-rays (CXRs), however, are readily available and may serve as a screening tool to identify patients with COPD who should undergo further testing. Currently, no research applies deep learning (DL) algorithms that use large multi-site and multi-modal data to detect COPD patients and evaluate fairness across demographic groups. We use three CXR datasets in our study, CheXpert to pre-train models, MIMIC-CXR to develop, and Emory-CXR to validate our models. The CXRs from patients in the early stage of COPD and not on mechanical ventilation are selected for model training and validation. We visualize the Grad-CAM heatmaps of the true positive cases on the base model for both MIMIC-CXR and Emory-CXR test datasets. We further propose two fusion schemes, (1) model-level fusion, including bagging and stacking methods using MIMIC-CXR, and (2) data-level fusion, including multi-site data using MIMIC-CXR and Emory-CXR, and multi-modal using MIMIC-CXRs and MIMIC-IV EHR, to improve the overall model performance. Fairness analysis is performed to evaluate if the fusion schemes have a discrepancy in the performance among different demographic groups. The results demonstrate that DL models can detect COPD using CXRs, which can facilitate early screening, especially in low-resource regions where CXRs are more accessible than spirometry. The multi-site data fusion scheme could improve the model generalizability on the Emory-CXR test data. Further studies on using CXR or other modalities to predict COPD ought to be in future work.
Learning to Ask Like a Physician
Jun 06, 2022
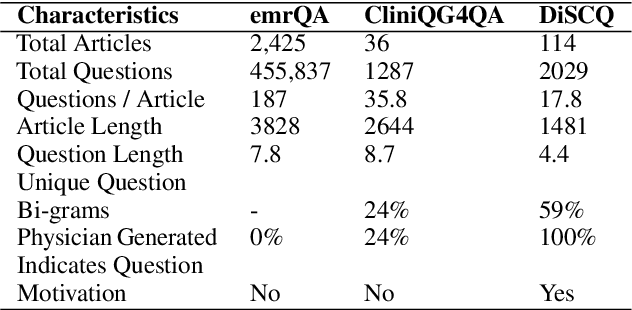

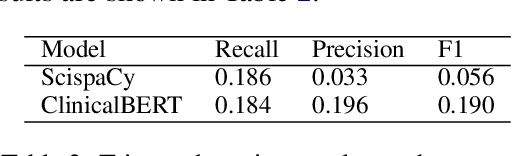
Existing question answering (QA) datasets derived from electronic health records (EHR) are artificially generated and consequently fail to capture realistic physician information needs. We present Discharge Summary Clinical Questions (DiSCQ), a newly curated question dataset composed of 2,000+ questions paired with the snippets of text (triggers) that prompted each question. The questions are generated by medical experts from 100+ MIMIC-III discharge summaries. We analyze this dataset to characterize the types of information sought by medical experts. We also train baseline models for trigger detection and question generation (QG), paired with unsupervised answer retrieval over EHRs. Our baseline model is able to generate high quality questions in over 62% of cases when prompted with human selected triggers. We release this dataset (and all code to reproduce baseline model results) to facilitate further research into realistic clinical QA and QG: https://github.com/elehman16/discq.
Improving Joint Learning of Chest X-Ray and Radiology Report by Word Region Alignment
Sep 04, 2021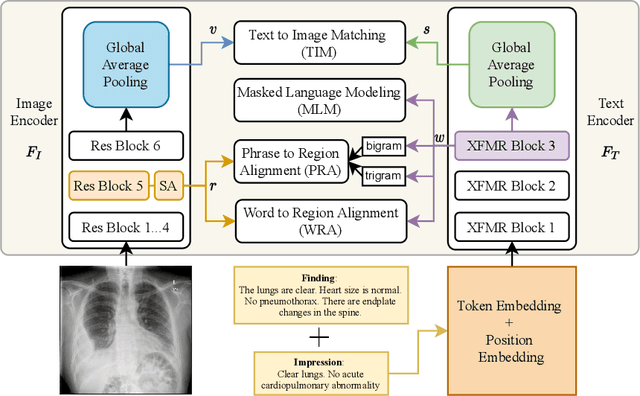
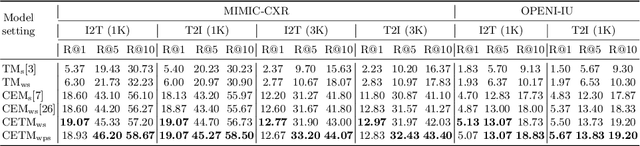
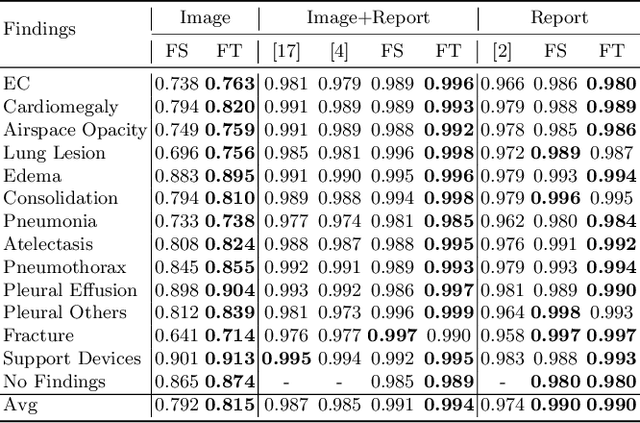
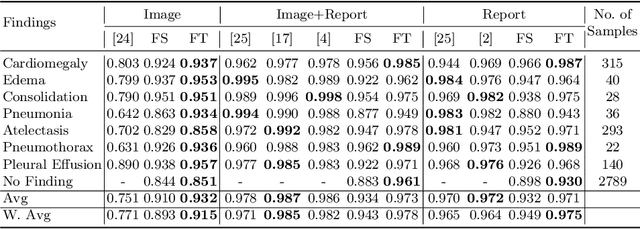
Self-supervised learning provides an opportunity to explore unlabeled chest X-rays and their associated free-text reports accumulated in clinical routine without manual supervision. This paper proposes a Joint Image Text Representation Learning Network (JoImTeRNet) for pre-training on chest X-ray images and their radiology reports. The model was pre-trained on both the global image-sentence level and the local image region-word level for visual-textual matching. Both are bidirectionally constrained on Cross-Entropy based and ranking-based Triplet Matching Losses. The region-word matching is calculated using the attention mechanism without direct supervision about their mapping. The pre-trained multi-modal representation learning paves the way for downstream tasks concerning image and/or text encoding. We demonstrate the representation learning quality by cross-modality retrievals and multi-label classifications on two datasets: OpenI-IU and MIMIC-CXR
LAViTeR: Learning Aligned Visual and Textual Representations Assisted by Image and Caption Generation
Sep 04, 2021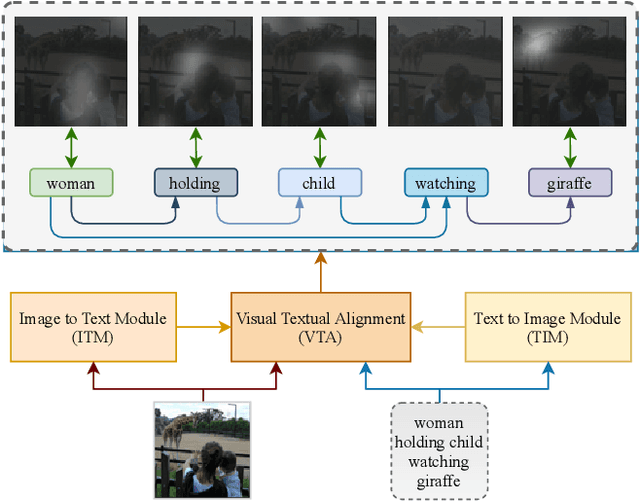
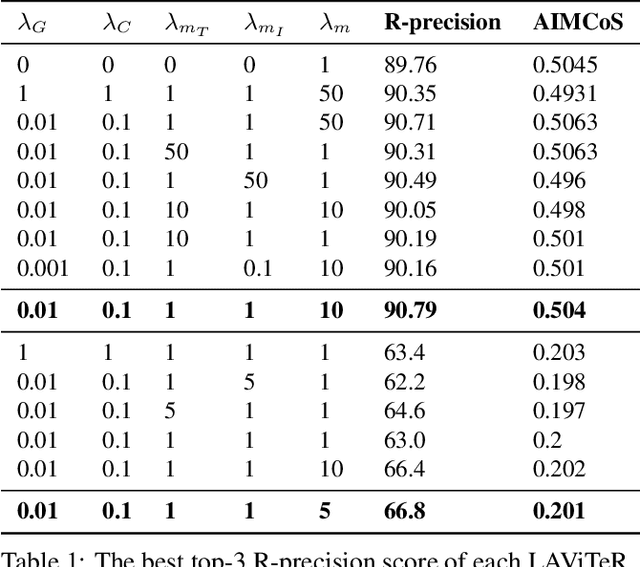
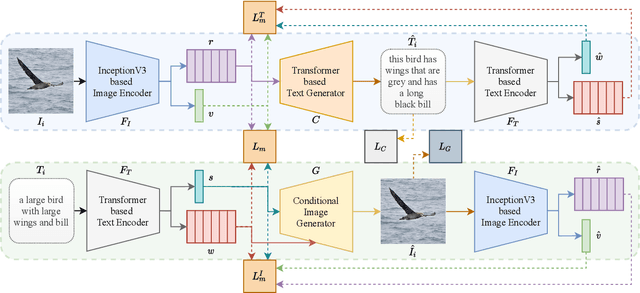
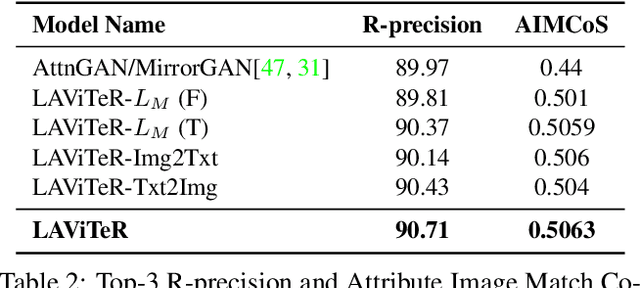
Pre-training visual and textual representations from large-scale image-text pairs is becoming a standard approach for many downstream vision-language tasks. The transformer-based models learn inter and intra-modal attention through a list of self-supervised learning tasks. This paper proposes LAViTeR, a novel architecture for visual and textual representation learning. The main module, Visual Textual Alignment (VTA) will be assisted by two auxiliary tasks, GAN-based image synthesis and Image Captioning. We also propose a new evaluation metric measuring the similarity between the learnt visual and textual embedding. The experimental results on two public datasets, CUB and MS-COCO, demonstrate superior visual and textual representation alignment in the joint feature embedding space