 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrozen Foundation-Model Embeddings Discard Small-Lesion Signal in Chest Radiography: Implications for Pre-Deployment Evaluation
Jun 10, 2026Frozen vision-transformer (ViT) foundation-model embeddings increasingly serve as the substrate for downstream chest-radiography (CXR) pipelines, yet where small-scale, low-contrast signal is retained or lost in the frozen forward pass has not been systematically quantified across architectures, pretraining domains, and objectives. We probed five frozen ViTs (RAD-DINO, DINOv2-B/14, DINOv3 ViT-7B, BiomedCLIP, MedSigLIP) and a frozen DINO-pretrained ResNet-50 architectural control across three large CXR cohorts (NIH-CXR14, MIMIC-CXR, Emory-CXR; aggregate pool n=492,724) and ChestX-Det10 (n=3,543; 1,462 small-lesion bounding boxes across Calcification, Nodule, Mass). Each model was evaluated with a small-scale-perturbation panel and a region-aware bounding-box-stratified probe on real lesions, comparing three pooling modes from the same forward pass: classification token (CLS), patch-mean (mean over all final-layer patch tokens), and bounding-box-restricted patch-local. On the perturbation panel, CLS embeddings sat at the chance floor (area under the ROC curve [AUC] 0.500-0.524); patch-mean was indistinguishable from CLS on iso-blur and reticular-fine cells but rose with CLS on larger directional-blur footprints, while disease AUC on globally decided tasks ranged 0.642-0.913. Patch-local probes recovered AUC ~1.0 from the same forward pass (per-model mean improvement +0.412 to +0.488); the ResNet-50 control reproduced the chance floor. On ChestX-Det10, image-level CLS classification showed within-class small-versus-large stratum gaps up to +0.243 AUC; bounding-box-level patch-local pooling on the same forward pass recovered AUC >= 0.899 on every (model x class) cell. Frozen ViT embeddings silently suppress small-scale signal at the global-aggregation step; the signal is recoverable from patch tokens conditional on a region of interest.
Human-Guided Agentic AI for Multimodal Clinical Prediction: Lessons from the AgentDS Healthcare Benchmark
Feb 23, 2026Agentic AI systems are increasingly capable of autonomous data science workflows, yet clinical prediction tasks demand domain expertise that purely automated approaches struggle to provide. We investigate how human guidance of agentic AI can improve multimodal clinical prediction, presenting our approach to all three AgentDS Healthcare benchmark challenges: 30-day hospital readmission prediction (Macro-F1 = 0.8986), emergency department cost forecasting (MAE = $465.13), and discharge readiness assessment (Macro-F1 = 0.7939). Across these tasks, human analysts directed the agentic workflow at key decision points, multimodal feature engineering from clinical notes, scanned PDF billing receipts, and time-series vital signs; task-appropriate model selection; and clinically informed validation strategies. Our approach ranked 5th overall in the healthcare domain, with a 3rd-place finish on the discharge readiness task. Ablation studies reveal that human-guided decisions compounded to a cumulative gain of +0.065 F1 over automated baselines, with multimodal feature extraction contributing the largest single improvement (+0.041 F1). We distill three generalizable lessons: (1) domain-informed feature engineering at each pipeline stage yields compounding gains that outperform extensive automated search; (2) multimodal data integration requires task-specific human judgment that no single extraction strategy generalizes across clinical text, PDFs, and time-series; and (3) deliberate ensemble diversity with clinically motivated model configurations outperforms random hyperparameter search. These findings offer practical guidance for teams deploying agentic AI in healthcare settings where interpretability, reproducibility, and clinical validity are essential.
Feature Quality and Adaptability of Medical Foundation Models: A Comparative Evaluation for Radiographic Classification and Segmentation
Nov 12, 2025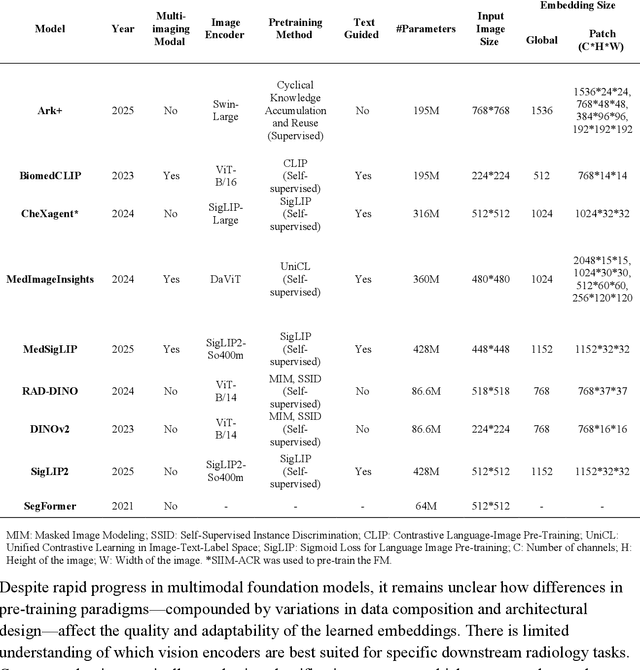
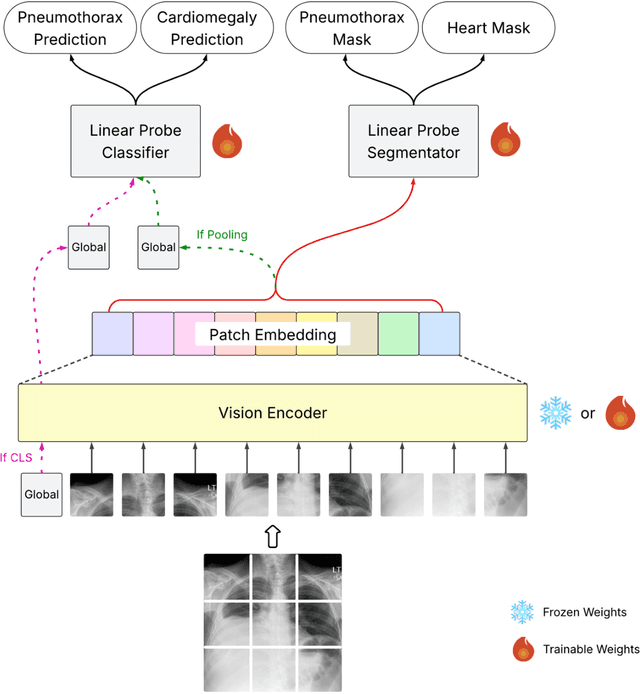
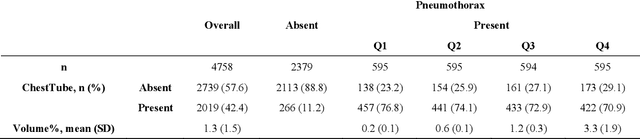
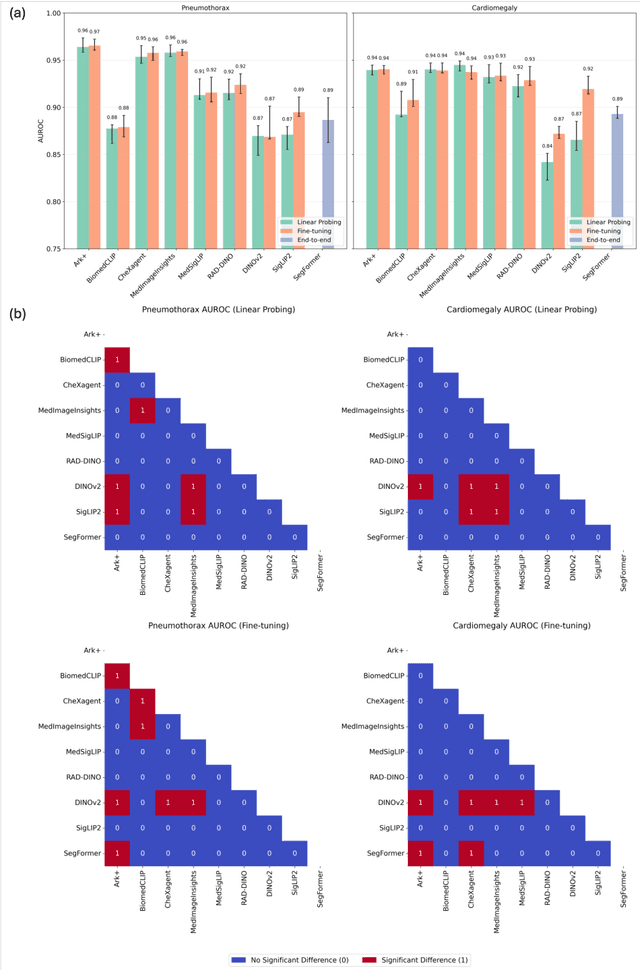
Foundation models (FMs) promise to generalize medical imaging, but their effectiveness varies. It remains unclear how pre-training domain (medical vs. general), paradigm (e.g., text-guided), and architecture influence embedding quality, hindering the selection of optimal encoders for specific radiology tasks. To address this, we evaluate vision encoders from eight medical and general-domain FMs for chest X-ray analysis. We benchmark classification (pneumothorax, cardiomegaly) and segmentation (pneumothorax, cardiac boundary) using linear probing and fine-tuning. Our results show that domain-specific pre-training provides a significant advantage; medical FMs consistently outperformed general-domain models in linear probing, establishing superior initial feature quality. However, feature utility is highly task-dependent. Pre-trained embeddings were strong for global classification and segmenting salient anatomy (e.g., heart). In contrast, for segmenting complex, subtle pathologies (e.g., pneumothorax), all FMs performed poorly without significant fine-tuning, revealing a critical gap in localizing subtle disease. Subgroup analysis showed FMs use confounding shortcuts (e.g., chest tubes for pneumothorax) for classification, a strategy that fails for precise segmentation. We also found that expensive text-image alignment is not a prerequisite; image-only (RAD-DINO) and label-supervised (Ark+) FMs were among top performers. Notably, a supervised, end-to-end baseline remained highly competitive, matching or exceeding the best FMs on segmentation tasks. These findings show that while medical pre-training is beneficial, architectural choices (e.g., multi-scale) are critical, and pre-trained features are not universally effective, especially for complex localization tasks where supervised models remain a strong alternative.
Evaluating Vision Language Models (VLMs) for Radiology: A Comprehensive Analysis
Apr 22, 2025



Foundation models, trained on vast amounts of data using self-supervised techniques, have emerged as a promising frontier for advancing artificial intelligence (AI) applications in medicine. This study evaluates three different vision-language foundation models (RAD-DINO, CheXagent, and BiomedCLIP) on their ability to capture fine-grained imaging features for radiology tasks. The models were assessed across classification, segmentation, and regression tasks for pneumothorax and cardiomegaly on chest radiographs. Self-supervised RAD-DINO consistently excelled in segmentation tasks, while text-supervised CheXagent demonstrated superior classification performance. BiomedCLIP showed inconsistent performance across tasks. A custom segmentation model that integrates global and local features substantially improved performance for all foundation models, particularly for challenging pneumothorax segmentation. The findings highlight that pre-training methodology significantly influences model performance on specific downstream tasks. For fine-grained segmentation tasks, models trained without text supervision performed better, while text-supervised models offered advantages in classification and interpretability. These insights provide guidance for selecting foundation models based on specific clinical applications in radiology.
DengueNet: Dengue Prediction using Spatiotemporal Satellite Imagery for Resource-Limited Countries
Jan 23, 2024



Dengue fever presents a substantial challenge in developing countries where sanitation infrastructure is inadequate. The absence of comprehensive healthcare systems exacerbates the severity of dengue infections, potentially leading to life-threatening circumstances. Rapid response to dengue outbreaks is also challenging due to limited information exchange and integration. While timely dengue outbreak forecasts have the potential to prevent such outbreaks, the majority of dengue prediction studies have predominantly relied on data that impose significant burdens on individual countries for collection. In this study, our aim is to improve health equity in resource-constrained countries by exploring the effectiveness of high-resolution satellite imagery as a nontraditional and readily accessible data source. By leveraging the wealth of publicly available and easily obtainable satellite imagery, we present a scalable satellite extraction framework based on Sentinel Hub, a cloud-based computing platform. Furthermore, we introduce DengueNet, an innovative architecture that combines Vision Transformer, Radiomics, and Long Short-term Memory to extract and integrate spatiotemporal features from satellite images. This enables dengue predictions on an epi-week basis. To evaluate the effectiveness of our proposed method, we conducted experiments on five municipalities in Colombia. We utilized a dataset comprising 780 high-resolution Sentinel-2 satellite images for training and evaluation. The performance of DengueNet was assessed using the mean absolute error (MAE) metric. Across the five municipalities, DengueNet achieved an average MAE of 43.92. Our findings strongly support the efficacy of satellite imagery as a valuable resource for dengue prediction, particularly in informing public health policies within countries where manually collected data is scarce and dengue virus prevalence is severe.
Synthetically Enhanced: Unveiling Synthetic Data's Potential in Medical Imaging Research
Nov 15, 2023



Chest X-rays (CXR) are the most common medical imaging study and are used to diagnose multiple medical conditions. This study examines the impact of synthetic data supplementation, using diffusion models, on the performance of deep learning (DL) classifiers for CXR analysis. We employed three datasets: CheXpert, MIMIC-CXR, and Emory Chest X-ray, training conditional denoising diffusion probabilistic models (DDPMs) to generate synthetic frontal radiographs. Our approach ensured that synthetic images mirrored the demographic and pathological traits of the original data. Evaluating the classifiers' performance on internal and external datasets revealed that synthetic data supplementation enhances model accuracy, particularly in detecting less prevalent pathologies. Furthermore, models trained on synthetic data alone approached the performance of those trained on real data. This suggests that synthetic data can potentially compensate for real data shortages in training robust DL models. However, despite promising outcomes, the superiority of real data persists.
A general-purpose AI assistant embedded in an open-source radiology information system
Mar 18, 2023



Radiology AI models have made significant progress in near-human performance or surpassing it. However, AI model's partnership with human radiologist remains an unexplored challenge due to the lack of health information standards, contextual and workflow differences, and data labeling variations. To overcome these challenges, we integrated an AI model service that uses DICOM standard SR annotations into the OHIF viewer in the open-source LibreHealth Radiology Information Systems (RIS). In this paper, we describe the novel Human-AI partnership capabilities of the platform, including few-shot learning and swarm learning approaches to retrain the AI models continuously. Building on the concept of machine teaching, we developed an active learning strategy within the RIS, so that the human radiologist can enable/disable AI annotations as well as "fix"/relabel the AI annotations. These annotations are then used to retrain the models. This helps establish a partnership between the radiologist user and a user-specific AI model. The weights of these user-specific models are then finally shared between multiple models in a swarm learning approach.
Few-Shot Transfer Learning to improve Chest X-Ray pathology detection using limited triplets
Apr 16, 2022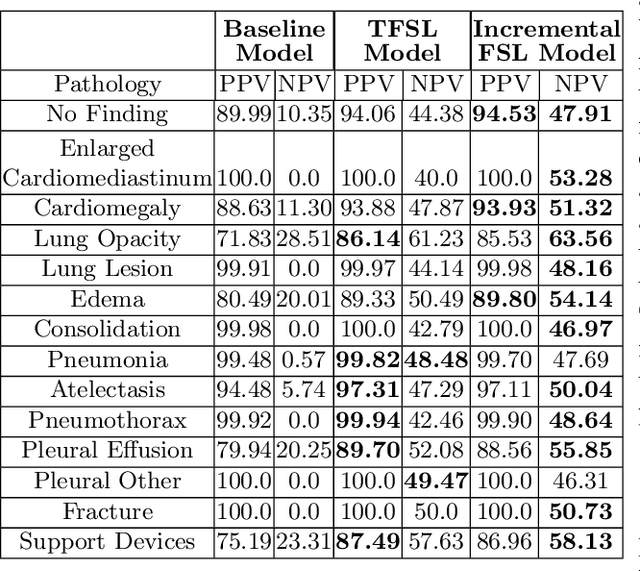
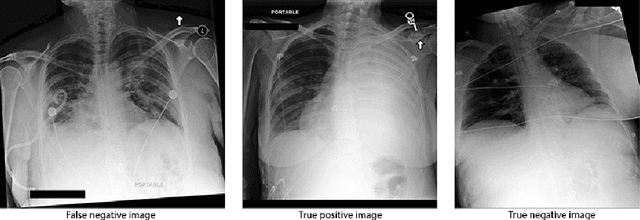
Deep learning approaches applied to medical imaging have reached near-human or better-than-human performance on many diagnostic tasks. For instance, the CheXpert competition on detecting pathologies in chest x-rays has shown excellent multi-class classification performance. However, training and validating deep learning models require extensive collections of images and still produce false inferences, as identified by a human-in-the-loop. In this paper, we introduce a practical approach to improve the predictions of a pre-trained model through Few-Shot Learning (FSL). After training and validating a model, a small number of false inference images are collected to retrain the model using \textbf{\textit{Image Triplets}} - a false positive or false negative, a true positive, and a true negative. The retrained FSL model produces considerable gains in performance with only a few epochs and few images. In addition, FSL opens rapid retraining opportunities for human-in-the-loop systems, where a radiologist can relabel false inferences, and the model can be quickly retrained. We compare our retrained model performance with existing FSL approaches in medical imaging that train and evaluate models at once.
OSCARS: An Outlier-Sensitive Content-Based Radiography Retrieval System
Apr 06, 2022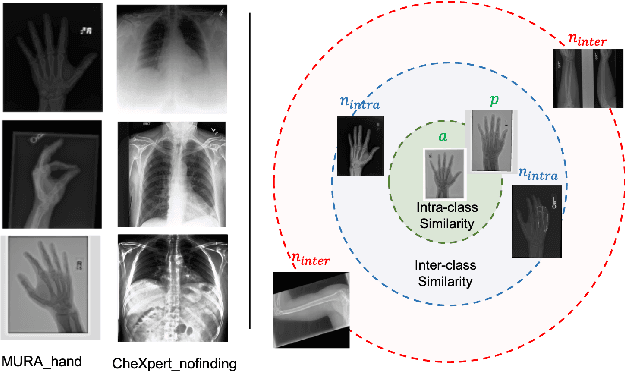

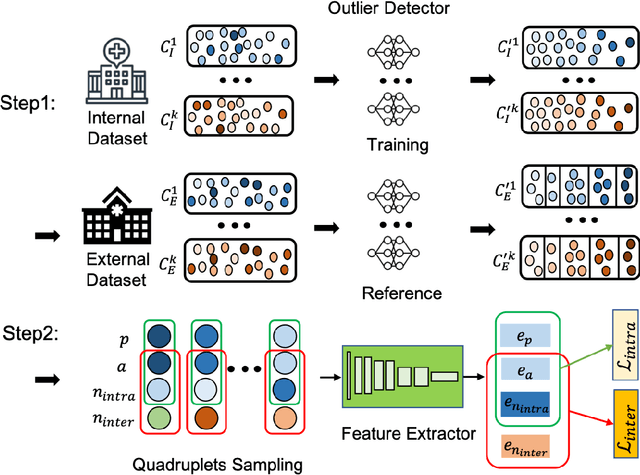

Improving the retrieval relevance on noisy datasets is an emerging need for the curation of a large-scale clean dataset in the medical domain. While existing methods can be applied for class-wise retrieval (aka. inter-class), they cannot distinguish the granularity of likeness within the same class (aka. intra-class). The problem is exacerbated on medical external datasets, where noisy samples of the same class are treated equally during training. Our goal is to identify both intra/inter-class similarities for fine-grained retrieval. To achieve this, we propose an Outlier-Sensitive Content-based rAdiologhy Retrieval System (OSCARS), consisting of two steps. First, we train an outlier detector on a clean internal dataset in an unsupervised manner. Then we use the trained detector to generate the anomaly scores on the external dataset, whose distribution will be used to bin intra-class variations. Second, we propose a quadruplet (a, p, nintra, ninter) sampling strategy, where intra-class negatives nintra are sampled from bins of the same class other than the bin anchor a belongs to, while niner are randomly sampled from inter-classes. We suggest a weighted metric learning objective to balance the intra and inter-class feature learning. We experimented on two representative public radiography datasets. Experiments show the effectiveness of our approach. The training and evaluation code can be found in https://github.com/XiaoyuanGuo/oscars.
MedShift: identifying shift data for medical dataset curation
Dec 27, 2021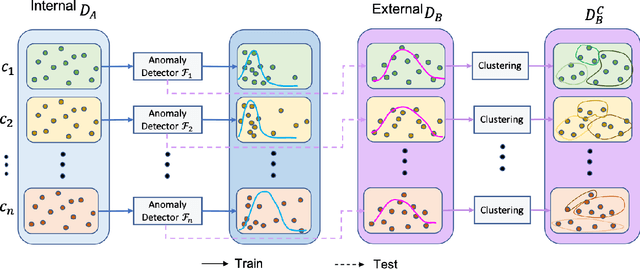
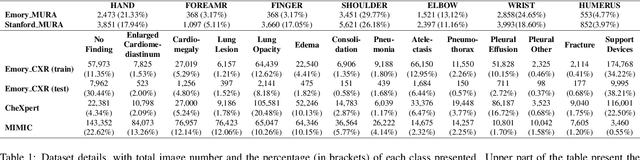
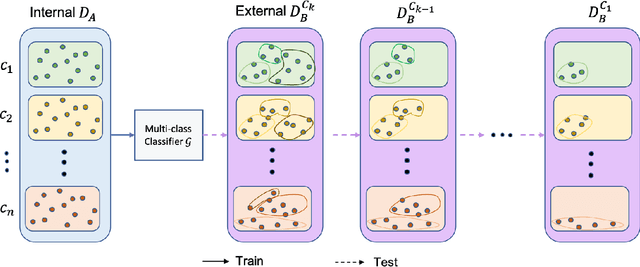
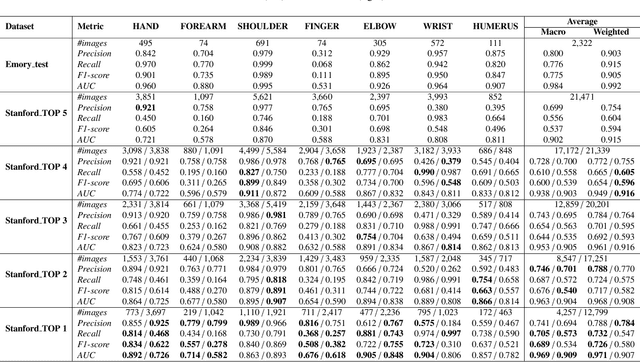
To curate a high-quality dataset, identifying data variance between the internal and external sources is a fundamental and crucial step. However, methods to detect shift or variance in data have not been significantly researched. Challenges to this are the lack of effective approaches to learn dense representation of a dataset and difficulties of sharing private data across medical institutions. To overcome the problems, we propose a unified pipeline called MedShift to detect the top-level shift samples and thus facilitate the medical curation. Given an internal dataset A as the base source, we first train anomaly detectors for each class of dataset A to learn internal distributions in an unsupervised way. Second, without exchanging data across sources, we run the trained anomaly detectors on an external dataset B for each class. The data samples with high anomaly scores are identified as shift data. To quantify the shiftness of the external dataset, we cluster B's data into groups class-wise based on the obtained scores. We then train a multi-class classifier on A and measure the shiftness with the classifier's performance variance on B by gradually dropping the group with the largest anomaly score for each class. Additionally, we adapt a dataset quality metric to help inspect the distribution differences for multiple medical sources. We verify the efficacy of MedShift with musculoskeletal radiographs (MURA) and chest X-rays datasets from more than one external source. Experiments show our proposed shift data detection pipeline can be beneficial for medical centers to curate high-quality datasets more efficiently. An interface introduction video to visualize our results is available at https://youtu.be/V3BF0P1sxQE.