 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Quality and Adaptability of Medical Foundation Models: A Comparative Evaluation for Radiographic Classification and Segmentation
Nov 12, 2025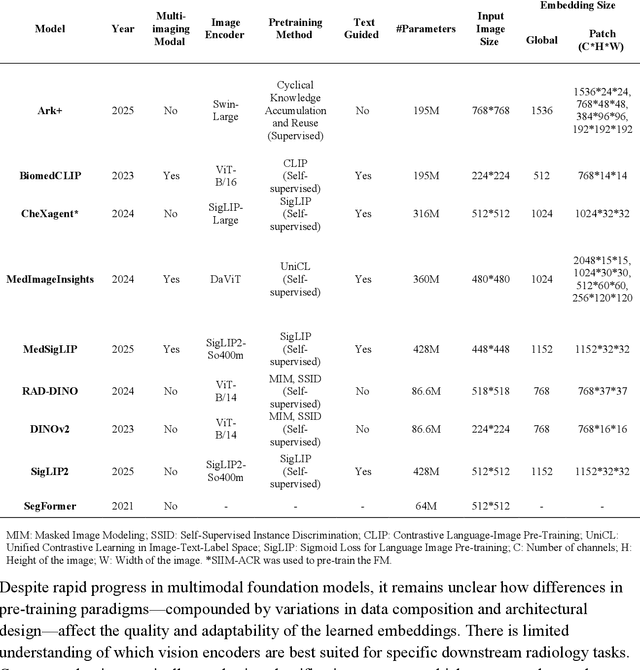
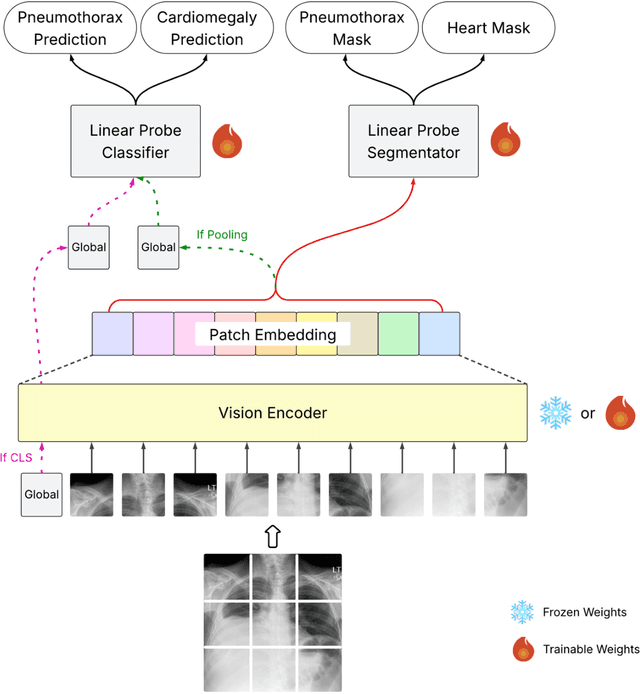
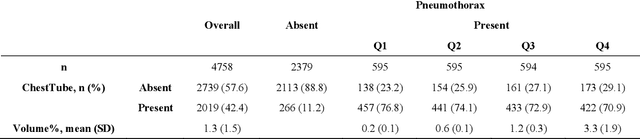
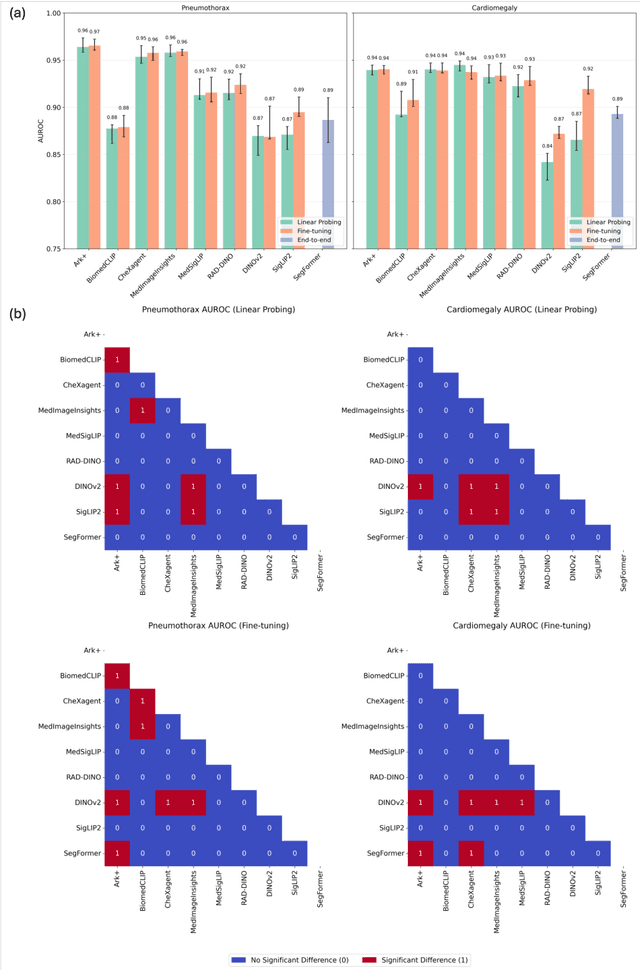
Foundation models (FMs) promise to generalize medical imaging, but their effectiveness varies. It remains unclear how pre-training domain (medical vs. general), paradigm (e.g., text-guided), and architecture influence embedding quality, hindering the selection of optimal encoders for specific radiology tasks. To address this, we evaluate vision encoders from eight medical and general-domain FMs for chest X-ray analysis. We benchmark classification (pneumothorax, cardiomegaly) and segmentation (pneumothorax, cardiac boundary) using linear probing and fine-tuning. Our results show that domain-specific pre-training provides a significant advantage; medical FMs consistently outperformed general-domain models in linear probing, establishing superior initial feature quality. However, feature utility is highly task-dependent. Pre-trained embeddings were strong for global classification and segmenting salient anatomy (e.g., heart). In contrast, for segmenting complex, subtle pathologies (e.g., pneumothorax), all FMs performed poorly without significant fine-tuning, revealing a critical gap in localizing subtle disease. Subgroup analysis showed FMs use confounding shortcuts (e.g., chest tubes for pneumothorax) for classification, a strategy that fails for precise segmentation. We also found that expensive text-image alignment is not a prerequisite; image-only (RAD-DINO) and label-supervised (Ark+) FMs were among top performers. Notably, a supervised, end-to-end baseline remained highly competitive, matching or exceeding the best FMs on segmentation tasks. These findings show that while medical pre-training is beneficial, architectural choices (e.g., multi-scale) are critical, and pre-trained features are not universally effective, especially for complex localization tasks where supervised models remain a strong alternative.
Evaluating Vision Language Models (VLMs) for Radiology: A Comprehensive Analysis
Apr 22, 2025



Foundation models, trained on vast amounts of data using self-supervised techniques, have emerged as a promising frontier for advancing artificial intelligence (AI) applications in medicine. This study evaluates three different vision-language foundation models (RAD-DINO, CheXagent, and BiomedCLIP) on their ability to capture fine-grained imaging features for radiology tasks. The models were assessed across classification, segmentation, and regression tasks for pneumothorax and cardiomegaly on chest radiographs. Self-supervised RAD-DINO consistently excelled in segmentation tasks, while text-supervised CheXagent demonstrated superior classification performance. BiomedCLIP showed inconsistent performance across tasks. A custom segmentation model that integrates global and local features substantially improved performance for all foundation models, particularly for challenging pneumothorax segmentation. The findings highlight that pre-training methodology significantly influences model performance on specific downstream tasks. For fine-grained segmentation tasks, models trained without text supervision performed better, while text-supervised models offered advantages in classification and interpretability. These insights provide guidance for selecting foundation models based on specific clinical applications in radiology.