 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiMedVision: Multi-Modal Medical Vision Framework
May 09, 2026Multi-modal medical imaging enables comprehensive diagnostics, yet current foundation models process 2D (e.g. X-ray) and 3D (e.g. CT) data with separate, dimensionality-specific architectures. We present MultiMedVision, a unified framework for joint 2D/3D representation learning built on a Sparse Vision Transformer. Our model uses 3D Rotary Positional Embeddings and variable-length sequence packing to process mixed-modality batches natively within a shared latent space, without modality-specific adapters or treating 3D volumes as 2D slice sequences. Trained with a self-supervised objective on chest X-rays (MIMIC-CXR) and CT scans (CT-RATE), and using a single shared encoder with 5x less data, MultiMedVision achieves competitive performance on both 2D benchmarks (Macro AUROC 0.82 on MIMIC, 0.84 on CheXpert) and 3D tasks (0.85 on CT-RATE). Analysis of the learned representations reveals coexisting modality-specific and shared feature subspaces, demonstrating that unified cross-dimensional representation learning is feasible without sacrificing modality-specific performance.
Comp2Comp: Open-Source Software with FDA-Cleared Artificial Intelligence Algorithms for Computed Tomography Image Analysis
Feb 10, 2026Artificial intelligence allows automatic extraction of imaging biomarkers from already-acquired radiologic images. This paradigm of opportunistic imaging adds value to medical imaging without additional imaging costs or patient radiation exposure. However, many open-source image analysis solutions lack rigorous validation while commercial solutions lack transparency, leading to unexpected failures when deployed. Here, we report development and validation for two of the first fully open-sourced, FDA-510(k)-cleared deep learning pipelines to mitigate both challenges: Abdominal Aortic Quantification (AAQ) and Bone Mineral Density (BMD) estimation are both offered within the Comp2Comp package for opportunistic analysis of computed tomography scans. AAQ segments the abdominal aorta to assess aneurysm size; BMD segments vertebral bodies to estimate trabecular bone density and osteoporosis risk. AAQ-derived maximal aortic diameters were compared against radiologist ground-truth measurements on 258 patient scans enriched for abdominal aortic aneurysms from four external institutions. BMD binary classifications (low vs. normal bone density) were compared against concurrent DXA scan ground truths obtained on 371 patient scans from four external institutions. AAQ had an overall mean absolute error of 1.57 mm (95% CI 1.38-1.80 mm). BMD had a sensitivity of 81.0% (95% CI 74.0-86.8%) and specificity of 78.4% (95% CI 72.3-83.7%). Comp2Comp AAQ and BMD demonstrated sufficient accuracy for clinical use. Open-sourcing these algorithms improves transparency of typically opaque FDA clearance processes, allows hospitals to test the algorithms before cumbersome clinical pilots, and provides researchers with best-in-class methods.
RSNA Large Language Model Benchmark Dataset for Chest Radiographs of Cardiothoracic Disease: Radiologist Evaluation and Validation Enhanced by AI Labels (REVEAL-CXR)
Jan 21, 2026Multimodal large language models have demonstrated comparable performance to that of radiology trainees on multiple-choice board-style exams. However, to develop clinically useful multimodal LLM tools, high-quality benchmarks curated by domain experts are essential. To curate released and holdout datasets of 100 chest radiographic studies each and propose an artificial intelligence (AI)-assisted expert labeling procedure to allow radiologists to label studies more efficiently. A total of 13,735 deidentified chest radiographs and their corresponding reports from the MIDRC were used. GPT-4o extracted abnormal findings from the reports, which were then mapped to 12 benchmark labels with a locally hosted LLM (Phi-4-Reasoning). From these studies, 1,000 were sampled on the basis of the AI-suggested benchmark labels for expert review; the sampling algorithm ensured that the selected studies were clinically relevant and captured a range of difficulty levels. Seventeen chest radiologists participated, and they marked "Agree all", "Agree mostly" or "Disagree" to indicate their assessment of the correctness of the LLM suggested labels. Each chest radiograph was evaluated by three experts. Of these, at least two radiologists selected "Agree All" for 381 radiographs. From this set, 200 were selected, prioritizing those with less common or multiple finding labels, and divided into 100 released radiographs and 100 reserved as the holdout dataset. The holdout dataset is used exclusively by RSNA to independently evaluate different models. A benchmark of 200 chest radiographic studies with 12 benchmark labels was created and made publicly available https://imaging.rsna.org, with each chest radiograph verified by three radiologists. In addition, an AI-assisted labeling procedure was developed to help radiologists label at scale, minimize unnecessary omissions, and support a semicollaborative environment.
Feature Quality and Adaptability of Medical Foundation Models: A Comparative Evaluation for Radiographic Classification and Segmentation
Nov 12, 2025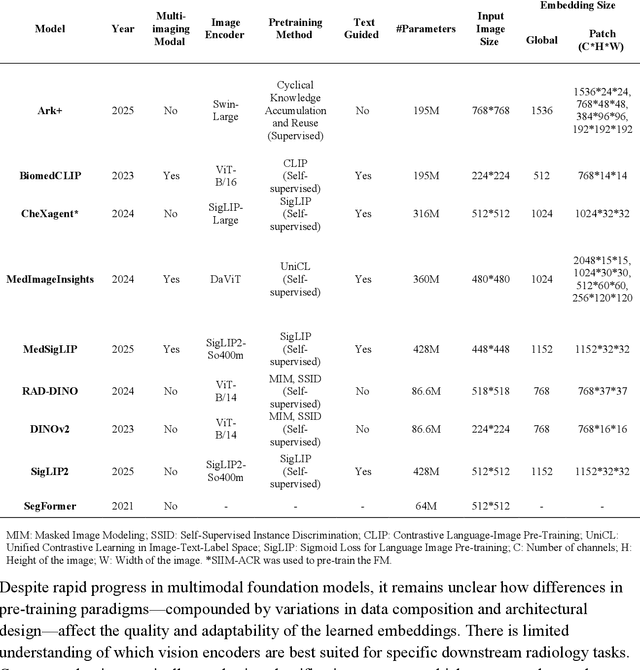
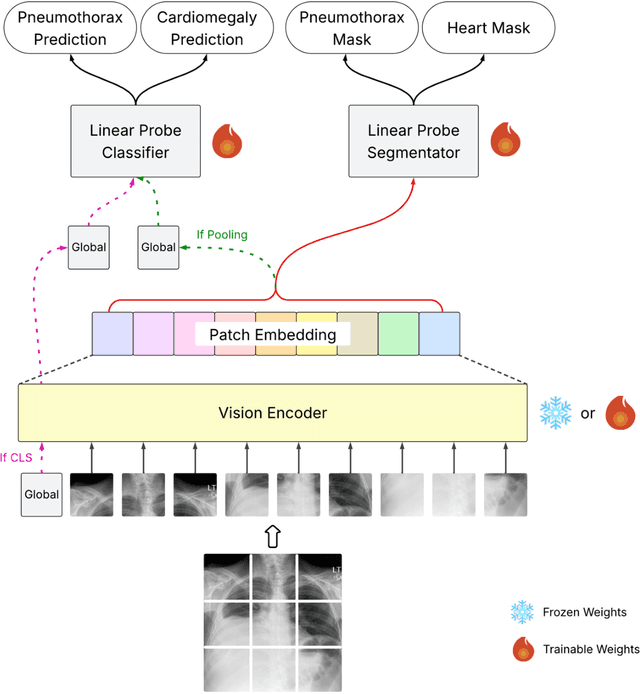
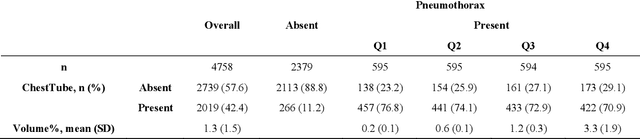
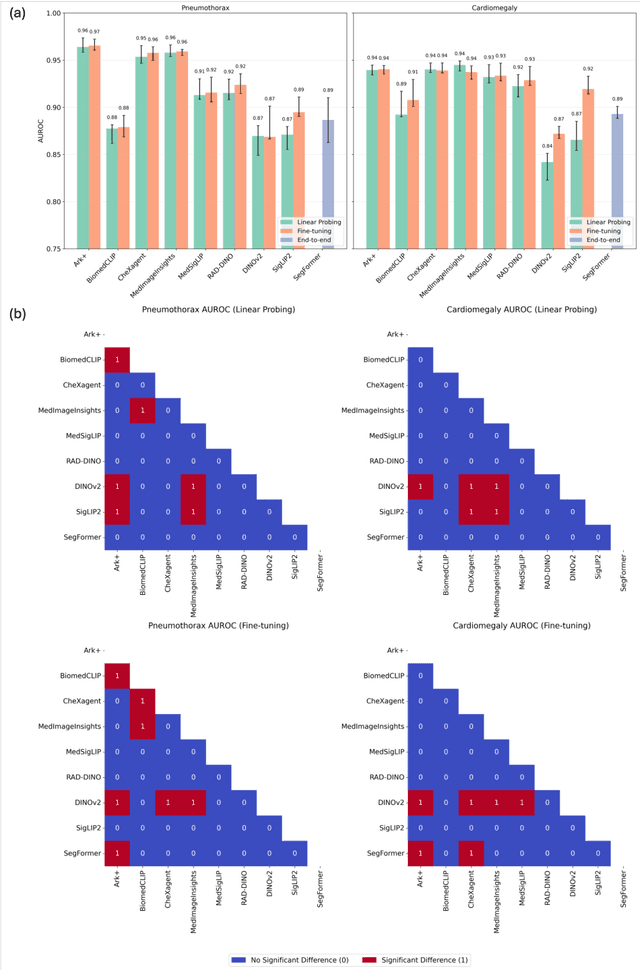
Foundation models (FMs) promise to generalize medical imaging, but their effectiveness varies. It remains unclear how pre-training domain (medical vs. general), paradigm (e.g., text-guided), and architecture influence embedding quality, hindering the selection of optimal encoders for specific radiology tasks. To address this, we evaluate vision encoders from eight medical and general-domain FMs for chest X-ray analysis. We benchmark classification (pneumothorax, cardiomegaly) and segmentation (pneumothorax, cardiac boundary) using linear probing and fine-tuning. Our results show that domain-specific pre-training provides a significant advantage; medical FMs consistently outperformed general-domain models in linear probing, establishing superior initial feature quality. However, feature utility is highly task-dependent. Pre-trained embeddings were strong for global classification and segmenting salient anatomy (e.g., heart). In contrast, for segmenting complex, subtle pathologies (e.g., pneumothorax), all FMs performed poorly without significant fine-tuning, revealing a critical gap in localizing subtle disease. Subgroup analysis showed FMs use confounding shortcuts (e.g., chest tubes for pneumothorax) for classification, a strategy that fails for precise segmentation. We also found that expensive text-image alignment is not a prerequisite; image-only (RAD-DINO) and label-supervised (Ark+) FMs were among top performers. Notably, a supervised, end-to-end baseline remained highly competitive, matching or exceeding the best FMs on segmentation tasks. These findings show that while medical pre-training is beneficial, architectural choices (e.g., multi-scale) are critical, and pre-trained features are not universally effective, especially for complex localization tasks where supervised models remain a strong alternative.
Evaluating Vision Language Models (VLMs) for Radiology: A Comprehensive Analysis
Apr 22, 2025



Foundation models, trained on vast amounts of data using self-supervised techniques, have emerged as a promising frontier for advancing artificial intelligence (AI) applications in medicine. This study evaluates three different vision-language foundation models (RAD-DINO, CheXagent, and BiomedCLIP) on their ability to capture fine-grained imaging features for radiology tasks. The models were assessed across classification, segmentation, and regression tasks for pneumothorax and cardiomegaly on chest radiographs. Self-supervised RAD-DINO consistently excelled in segmentation tasks, while text-supervised CheXagent demonstrated superior classification performance. BiomedCLIP showed inconsistent performance across tasks. A custom segmentation model that integrates global and local features substantially improved performance for all foundation models, particularly for challenging pneumothorax segmentation. The findings highlight that pre-training methodology significantly influences model performance on specific downstream tasks. For fine-grained segmentation tasks, models trained without text supervision performed better, while text-supervised models offered advantages in classification and interpretability. These insights provide guidance for selecting foundation models based on specific clinical applications in radiology.
A Multi-Modal AI System for Screening Mammography: Integrating 2D and 3D Imaging to Improve Breast Cancer Detection in a Prospective Clinical Study
Apr 08, 2025
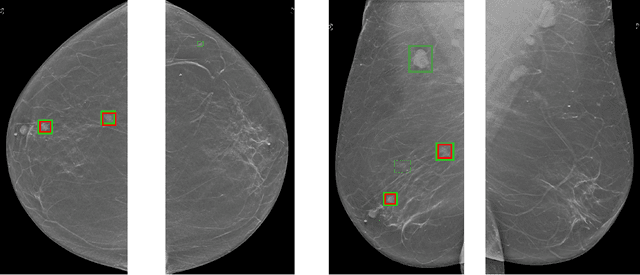
Although digital breast tomosynthesis (DBT) improves diagnostic performance over full-field digital mammography (FFDM), false-positive recalls remain a concern in breast cancer screening. We developed a multi-modal artificial intelligence system integrating FFDM, synthetic mammography, and DBT to provide breast-level predictions and bounding-box localizations of suspicious findings. Our AI system, trained on approximately 500,000 mammography exams, achieved 0.945 AUROC on an internal test set. It demonstrated capacity to reduce recalls by 31.7% and radiologist workload by 43.8% while maintaining 100% sensitivity, underscoring its potential to improve clinical workflows. External validation confirmed strong generalizability, reducing the gap to a perfect AUROC by 35.31%-69.14% relative to strong baselines. In prospective deployment across 18 sites, the system reduced recall rates for low-risk cases. An improved version, trained on over 750,000 exams with additional labels, further reduced the gap by 18.86%-56.62% across large external datasets. Overall, these results underscore the importance of utilizing all available imaging modalities, demonstrate the potential for clinical impact, and indicate feasibility of further reduction of the test error with increased training set when using large-capacity neural networks.
Subgroup Performance of a Commercial Digital Breast Tomosynthesis Model for Breast Cancer Detection
Mar 17, 2025While research has established the potential of AI models for mammography to improve breast cancer screening outcomes, there have not been any detailed subgroup evaluations performed to assess the strengths and weaknesses of commercial models for digital breast tomosynthesis (DBT) imaging. This study presents a granular evaluation of the Lunit INSIGHT DBT model on a large retrospective cohort of 163,449 screening mammography exams from the Emory Breast Imaging Dataset (EMBED). Model performance was evaluated in a binary context with various negative exam types (162,081 exams) compared against screen detected cancers (1,368 exams) as the positive class. The analysis was stratified across demographic, imaging, and pathologic subgroups to identify potential disparities. The model achieved an overall AUC of 0.91 (95% CI: 0.90-0.92) with a precision of 0.08 (95% CI: 0.08-0.08), and a recall of 0.73 (95% CI: 0.71-0.76). Performance was found to be robust across demographics, but cases with non-invasive cancers (AUC: 0.85, 95% CI: 0.83-0.87), calcifications (AUC: 0.80, 95% CI: 0.78-0.82), and dense breast tissue (AUC: 0.90, 95% CI: 0.88-0.91) were associated with significantly lower performance compared to other groups. These results highlight the need for detailed evaluation of model characteristics and vigilance in considering adoption of new tools for clinical deployment.
Novel AI-Based Quantification of Breast Arterial Calcification to Predict Cardiovascular Risk
Mar 17, 2025



Women are underdiagnosed and undertreated for cardiovascular disease. Automatic quantification of breast arterial calcification on screening mammography can identify women at risk for cardiovascular disease and enable earlier treatment and management of disease. In this retrospective study of 116,135 women from two healthcare systems, a transformer-based neural network quantified BAC severity (no BAC, mild, moderate, and severe) on screening mammograms. Outcomes included major adverse cardiovascular events (MACE) and all-cause mortality. BAC severity was independently associated with MACE after adjusting for cardiovascular risk factors, with increasing hazard ratios from mild (HR 1.18-1.22), moderate (HR 1.38-1.47), to severe BAC (HR 2.03-2.22) across datasets (all p<0.001). This association remained significant across all age groups, with even mild BAC indicating increased risk in women under 50. BAC remained an independent predictor when analyzed alongside ASCVD risk scores, showing significant associations with myocardial infarction, stroke, heart failure, and mortality (all p<0.005). Automated BAC quantification enables opportunistic cardiovascular risk assessment during routine mammography without additional radiation or cost. This approach provides value beyond traditional risk factors, particularly in younger women, offering potential for early CVD risk stratification in the millions of women undergoing annual mammography.
Emory Knee Radiograph (MRKR) Dataset
Oct 30, 2024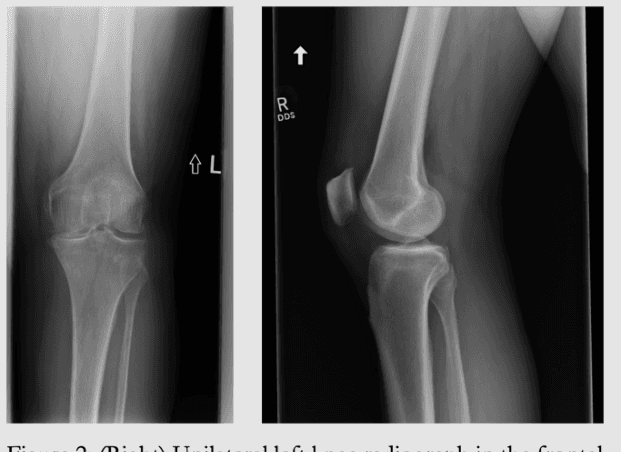
The Emory Knee Radiograph (MRKR) dataset is a large, demographically diverse collection of 503,261 knee radiographs from 83,011 patients, 40% of which are African American. This dataset provides imaging data in DICOM format along with detailed clinical information, including patient-reported pain scores, diagnostic codes, and procedural codes, which are not commonly available in similar datasets. The MRKR dataset also features imaging metadata such as image laterality, view type, and presence of hardware, enhancing its value for research and model development. MRKR addresses significant gaps in existing datasets by offering a more representative sample for studying osteoarthritis and related outcomes, particularly among minority populations, thereby providing a valuable resource for clinicians and researchers.
Benchmarking bias: Expanding clinical AI model card to incorporate bias reporting of social and non-social factors
Nov 21, 2023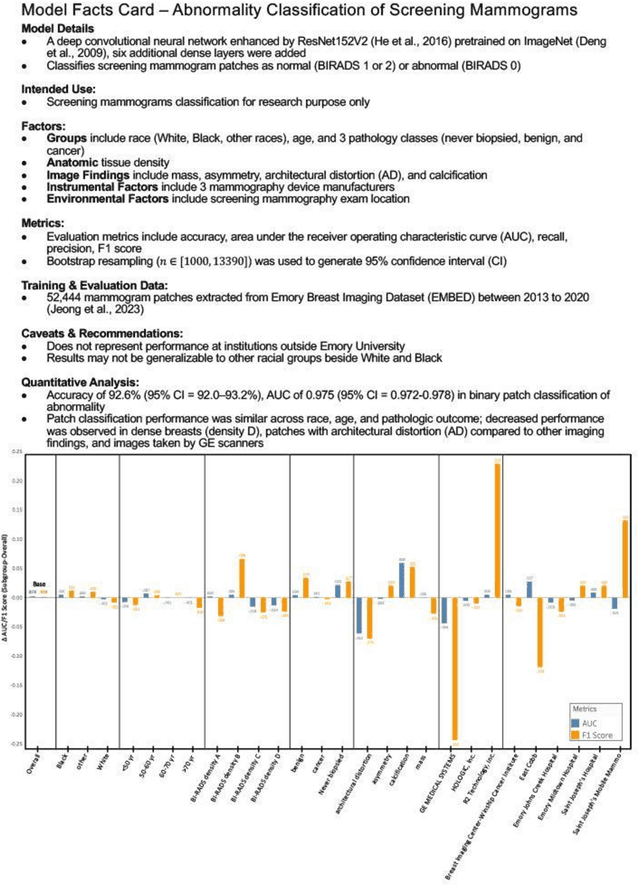
Clinical AI model reporting cards should be expanded to incorporate a broad bias reporting of both social and non-social factors. Non-social factors consider the role of other factors, such as disease dependent, anatomic, or instrument factors on AI model bias, which are essential to ensure safe deployment.