 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Gaps of Artificial Intelligence Models Screening Mammography -- Towards Fair and Interpretable Models
May 08, 2023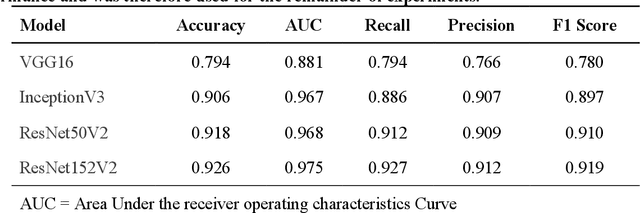
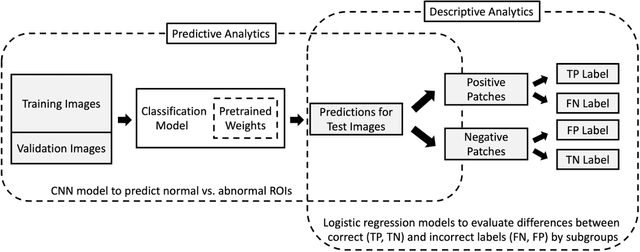
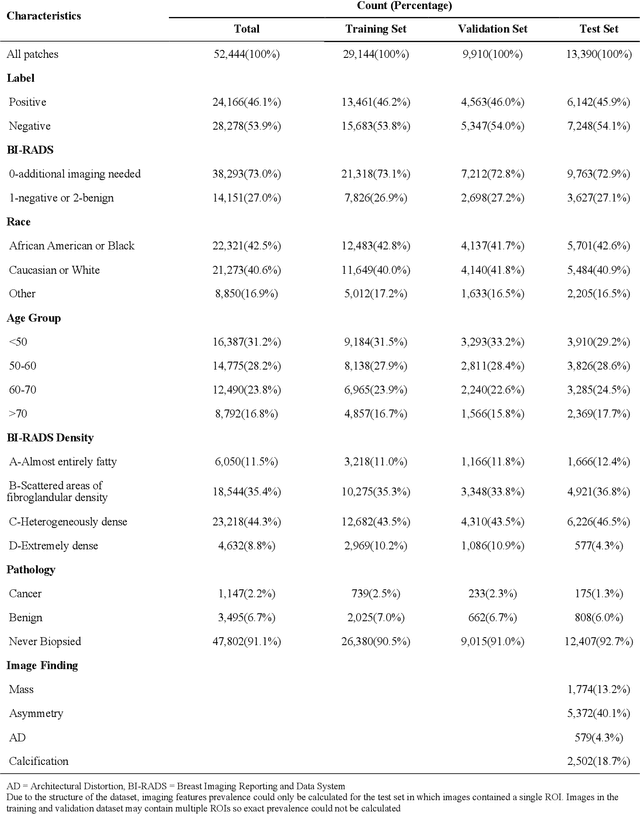
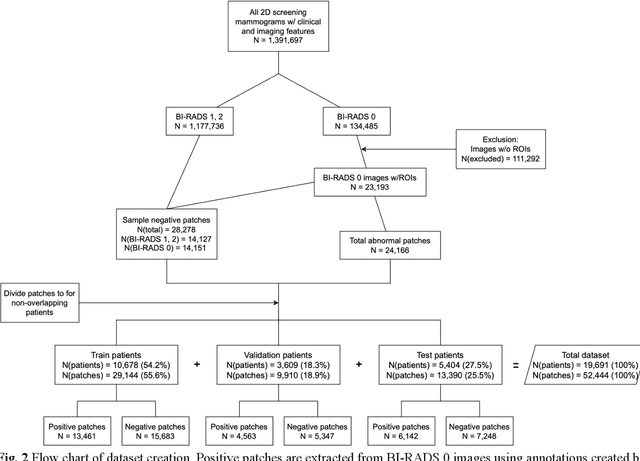
Purpose: To analyze the demographic and imaging characteristics associated with increased risk of failure for abnormality classification in screening mammograms. Materials and Methods: This retrospective study used data from the Emory BrEast Imaging Dataset (EMBED) which includes mammograms from 115,931 patients imaged at Emory University Healthcare between 2013 to 2020. Clinical and imaging data includes Breast Imaging Reporting and Data System (BI-RADS) assessment, region of interest coordinates for abnormalities, imaging features, pathologic outcomes, and patient demographics. Multiple deep learning models were developed to distinguish between patches of abnormal tissue and randomly selected patches of normal tissue from the screening mammograms. We assessed model performance overall and within subgroups defined by age, race, pathologic outcome, and imaging characteristics to evaluate reasons for misclassifications. Results: On a test set size of 5,810 studies (13,390 patches), a ResNet152V2 model trained to classify normal versus abnormal tissue patches achieved an accuracy of 92.6% (95% CI = 92.0-93.2%), and area under the receiver operative characteristics curve 0.975 (95% CI = 0.972-0.978). Imaging characteristics associated with higher misclassifications of images include higher tissue densities (risk ratio [RR]=1.649; p=.010, BI-RADS density C and RR=2.026; p=.003, BI-RADS density D), and presence of architectural distortion (RR=1.026; p<.001). Conclusion: Even though deep learning models for abnormality classification can perform well in screening mammography, we demonstrate certain imaging features that result in worse model performance. This is the first such work to systematically evaluate breast abnormality classification by various subgroups and better-informed developers and end-users of population subgroups which are likely to experience biased model performance.
GaNDLF: A Generally Nuanced Deep Learning Framework for Scalable End-to-End Clinical Workflows in Medical Imaging
Feb 26, 2021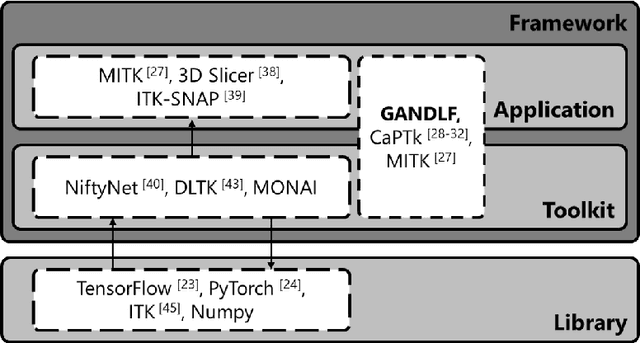

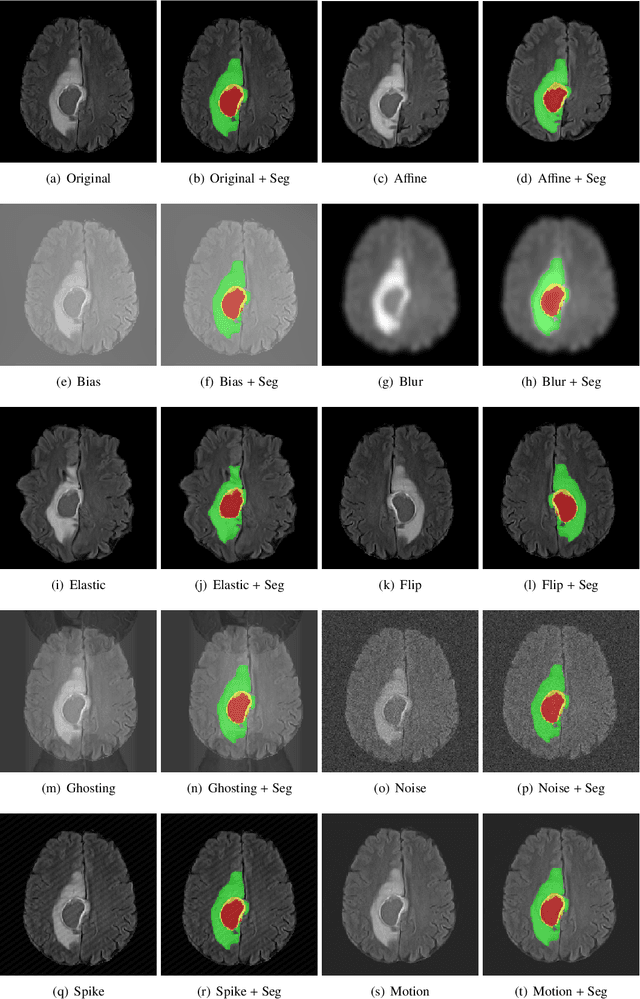
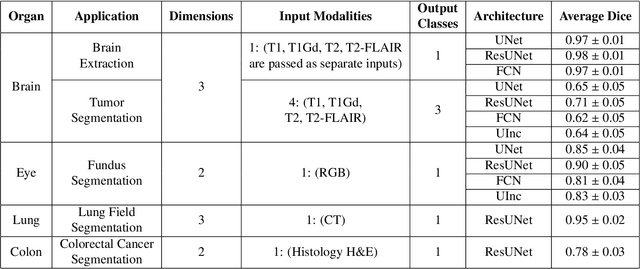
Deep Learning (DL) has greatly highlighted the potential impact of optimized machine learning in both the scientific and clinical communities. The advent of open-source DL libraries from major industrial entities, such as TensorFlow (Google), PyTorch (Facebook), and MXNet (Apache), further contributes to DL promises on the democratization of computational analytics. However, increased technical and specialized background is required to develop DL algorithms, and the variability of implementation details hinders their reproducibility. Towards lowering the barrier and making the mechanism of DL development, training, and inference more stable, reproducible, and scalable, without requiring an extensive technical background, this manuscript proposes the \textbf{G}ener\textbf{a}lly \textbf{N}uanced \textbf{D}eep \textbf{L}earning \textbf{F}ramework (GaNDLF). With built-in support for $k$-fold cross-validation, data augmentation, multiple modalities and output classes, and multi-GPU training, as well as the ability to work with both radiographic and histologic imaging, GaNDLF aims to provide an end-to-end solution for all DL-related tasks, to tackle problems in medical imaging and provide a robust application framework for deployment in clinical workflows.
Deep-LIBRA: Artificial intelligence method for robust quantification of breast density with independent validation in breast cancer risk assessment
Nov 17, 2020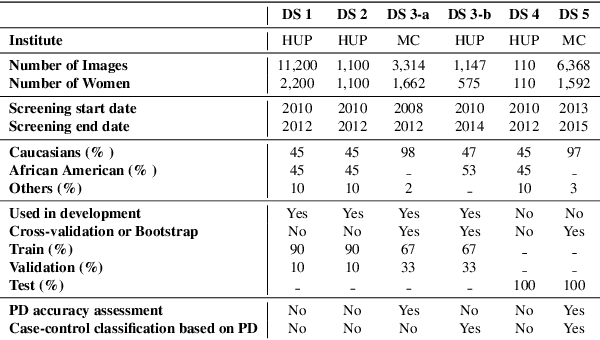
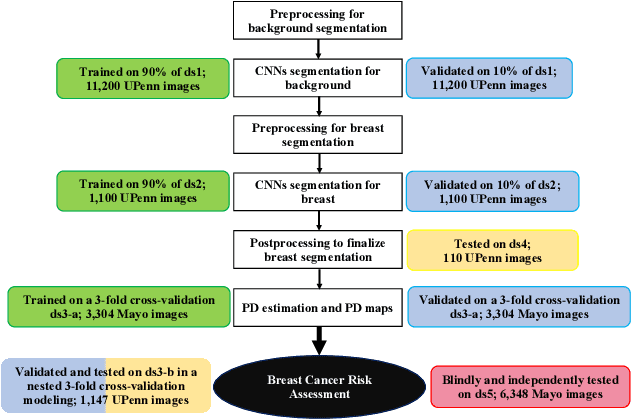
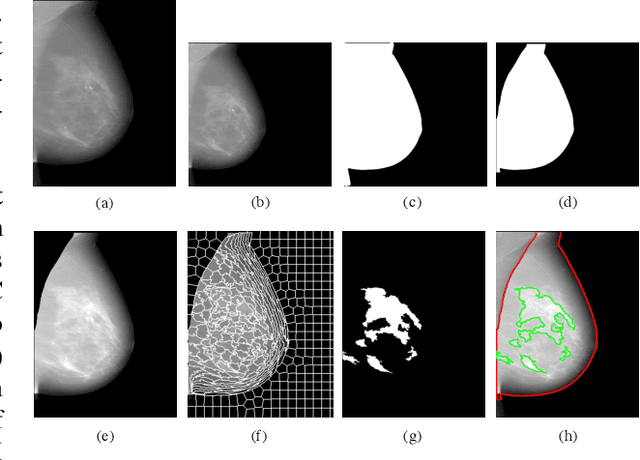
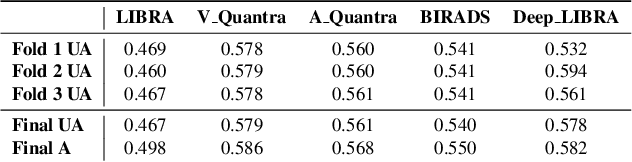
Breast density is an important risk factor for breast cancer that also affects the specificity and sensitivity of screening mammography. Current federal legislation mandates reporting of breast density for all women undergoing breast screening. Clinically, breast density is assessed visually using the American College of Radiology Breast Imaging Reporting And Data System (BI-RADS) scale. Here, we introduce an artificial intelligence (AI) method to estimate breast percentage density (PD) from digital mammograms. Our method leverages deep learning (DL) using two convolutional neural network architectures to accurately segment the breast area. A machine-learning algorithm combining superpixel generation, texture feature analysis, and support vector machine is then applied to differentiate dense from non-dense tissue regions, from which PD is estimated. Our method has been trained and validated on a multi-ethnic, multi-institutional dataset of 15,661 images (4,437 women), and then tested on an independent dataset of 6,368 digital mammograms (1,702 women; cases=414) for both PD estimation and discrimination of breast cancer. On the independent dataset, PD estimates from Deep-LIBRA and an expert reader were strongly correlated (Spearman correlation coefficient = 0.90). Moreover, Deep-LIBRA yielded a higher breast cancer discrimination performance (area under the ROC curve, AUC = 0.611 [95% confidence interval (CI): 0.583, 0.639]) compared to four other widely-used research and commercial PD assessment methods (AUCs = 0.528 to 0.588). Our results suggest a strong agreement of PD estimates between Deep-LIBRA and gold-standard assessment by an expert reader, as well as improved performance in breast cancer risk assessment over state-of-the-art open-source and commercial methods.