 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInclusive, Differentially Private Federated Learning for Clinical Data
May 28, 2025Federated Learning (FL) offers a promising approach for training clinical AI models without centralizing sensitive patient data. However, its real-world adoption is hindered by challenges related to privacy, resource constraints, and compliance. Existing Differential Privacy (DP) approaches often apply uniform noise, which disproportionately degrades model performance, even among well-compliant institutions. In this work, we propose a novel compliance-aware FL framework that enhances DP by adaptively adjusting noise based on quantifiable client compliance scores. Additionally, we introduce a compliance scoring tool based on key healthcare and security standards to promote secure, inclusive, and equitable participation across diverse clinical settings. Extensive experiments on public datasets demonstrate that integrating under-resourced, less compliant clinics with highly regulated institutions yields accuracy improvements of up to 15% over traditional FL. This work advances FL by balancing privacy, compliance, and performance, making it a viable solution for real-world clinical workflows in global healthcare.
Analysis of the MICCAI Brain Tumor Segmentation -- Metastases (BraTS-METS) 2025 Lighthouse Challenge: Brain Metastasis Segmentation on Pre- and Post-treatment MRI
Apr 16, 2025Despite continuous advancements in cancer treatment, brain metastatic disease remains a significant complication of primary cancer and is associated with an unfavorable prognosis. One approach for improving diagnosis, management, and outcomes is to implement algorithms based on artificial intelligence for the automated segmentation of both pre- and post-treatment MRI brain images. Such algorithms rely on volumetric criteria for lesion identification and treatment response assessment, which are still not available in clinical practice. Therefore, it is critical to establish tools for rapid volumetric segmentations methods that can be translated to clinical practice and that are trained on high quality annotated data. The BraTS-METS 2025 Lighthouse Challenge aims to address this critical need by establishing inter-rater and intra-rater variability in dataset annotation by generating high quality annotated datasets from four individual instances of segmentation by neuroradiologists while being recorded on video (two instances doing "from scratch" and two instances after AI pre-segmentation). This high-quality annotated dataset will be used for testing phase in 2025 Lighthouse challenge and will be publicly released at the completion of the challenge. The 2025 Lighthouse challenge will also release the 2023 and 2024 segmented datasets that were annotated using an established pipeline of pre-segmentation, student annotation, two neuroradiologists checking, and one neuroradiologist finalizing the process. It builds upon its previous edition by including post-treatment cases in the dataset. Using these high-quality annotated datasets, the 2025 Lighthouse challenge plans to test benchmark algorithms for automated segmentation of pre-and post-treatment brain metastases (BM), trained on diverse and multi-institutional datasets of MRI images obtained from patients with brain metastases.
BraTS-PEDs: Results of the Multi-Consortium International Pediatric Brain Tumor Segmentation Challenge 2023
Jul 11, 2024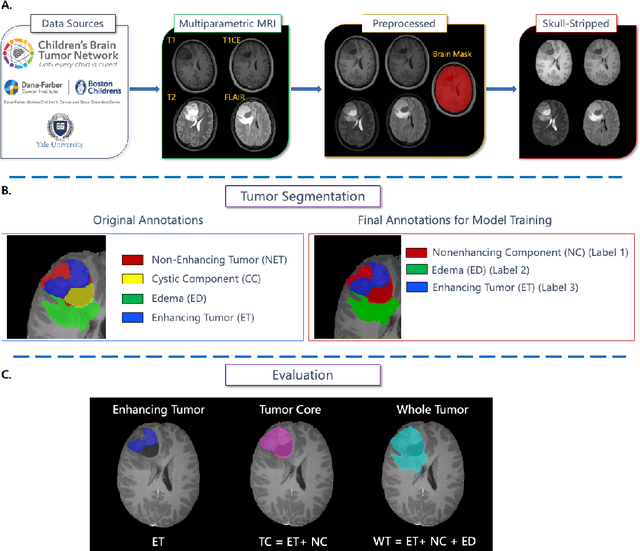

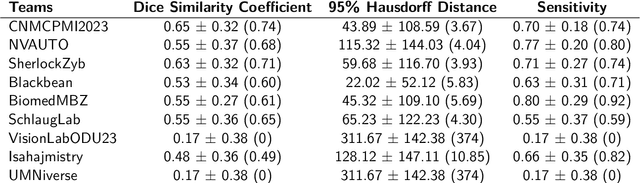
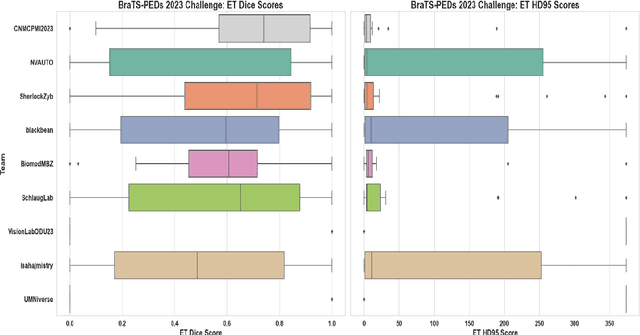
Pediatric central nervous system tumors are the leading cause of cancer-related deaths in children. The five-year survival rate for high-grade glioma in children is less than 20%. The development of new treatments is dependent upon multi-institutional collaborative clinical trials requiring reproducible and accurate centralized response assessment. We present the results of the BraTS-PEDs 2023 challenge, the first Brain Tumor Segmentation (BraTS) challenge focused on pediatric brain tumors. This challenge utilized data acquired from multiple international consortia dedicated to pediatric neuro-oncology and clinical trials. BraTS-PEDs 2023 aimed to evaluate volumetric segmentation algorithms for pediatric brain gliomas from magnetic resonance imaging using standardized quantitative performance evaluation metrics employed across the BraTS 2023 challenges. The top-performing AI approaches for pediatric tumor analysis included ensembles of nnU-Net and Swin UNETR, Auto3DSeg, or nnU-Net with a self-supervised framework. The BraTSPEDs 2023 challenge fostered collaboration between clinicians (neuro-oncologists, neuroradiologists) and AI/imaging scientists, promoting faster data sharing and the development of automated volumetric analysis techniques. These advancements could significantly benefit clinical trials and improve the care of children with brain tumors.
Brain Tumor Segmentation (BraTS) Challenge 2024: Meningioma Radiotherapy Planning Automated Segmentation
May 28, 2024The 2024 Brain Tumor Segmentation Meningioma Radiotherapy (BraTS-MEN-RT) challenge aims to advance automated segmentation algorithms using the largest known multi-institutional dataset of radiotherapy planning brain MRIs with expert-annotated target labels for patients with intact or post-operative meningioma that underwent either conventional external beam radiotherapy or stereotactic radiosurgery. Each case includes a defaced 3D post-contrast T1-weighted radiotherapy planning MRI in its native acquisition space, accompanied by a single-label "target volume" representing the gross tumor volume (GTV) and any at-risk post-operative site. Target volume annotations adhere to established radiotherapy planning protocols, ensuring consistency across cases and institutions. For pre-operative meningiomas, the target volume encompasses the entire GTV and associated nodular dural tail, while for post-operative cases, it includes at-risk resection cavity margins as determined by the treating institution. Case annotations were reviewed and approved by expert neuroradiologists and radiation oncologists. Participating teams will develop, containerize, and evaluate automated segmentation models using this comprehensive dataset. Model performance will be assessed using the lesion-wise Dice Similarity Coefficient and the 95% Hausdorff distance. The top-performing teams will be recognized at the Medical Image Computing and Computer Assisted Intervention Conference in October 2024. BraTS-MEN-RT is expected to significantly advance automated radiotherapy planning by enabling precise tumor segmentation and facilitating tailored treatment, ultimately improving patient outcomes.
BraTS-Path Challenge: Assessing Heterogeneous Histopathologic Brain Tumor Sub-regions
May 17, 2024Glioblastoma is the most common primary adult brain tumor, with a grim prognosis - median survival of 12-18 months following treatment, and 4 months otherwise. Glioblastoma is widely infiltrative in the cerebral hemispheres and well-defined by heterogeneous molecular and micro-environmental histopathologic profiles, which pose a major obstacle in treatment. Correctly diagnosing these tumors and assessing their heterogeneity is crucial for choosing the precise treatment and potentially enhancing patient survival rates. In the gold-standard histopathology-based approach to tumor diagnosis, detecting various morpho-pathological features of distinct histology throughout digitized tissue sections is crucial. Such "features" include the presence of cellular tumor, geographic necrosis, pseudopalisading necrosis, areas abundant in microvascular proliferation, infiltration into the cortex, wide extension in subcortical white matter, leptomeningeal infiltration, regions dense with macrophages, and the presence of perivascular or scattered lymphocytes. With these features in mind and building upon the main aim of the BraTS Cluster of Challenges https://www.synapse.org/brats2024, the goal of the BraTS-Path challenge is to provide a systematically prepared comprehensive dataset and a benchmarking environment to develop and fairly compare deep-learning models capable of identifying tumor sub-regions of distinct histologic profile. These models aim to further our understanding of the disease and assist in the diagnosis and grading of conditions in a consistent manner.
Analysis of the BraTS 2023 Intracranial Meningioma Segmentation Challenge
May 16, 2024



We describe the design and results from the BraTS 2023 Intracranial Meningioma Segmentation Challenge. The BraTS Meningioma Challenge differed from prior BraTS Glioma challenges in that it focused on meningiomas, which are typically benign extra-axial tumors with diverse radiologic and anatomical presentation and a propensity for multiplicity. Nine participating teams each developed deep-learning automated segmentation models using image data from the largest multi-institutional systematically expert annotated multilabel multi-sequence meningioma MRI dataset to date, which included 1000 training set cases, 141 validation set cases, and 283 hidden test set cases. Each case included T2, T2/FLAIR, T1, and T1Gd brain MRI sequences with associated tumor compartment labels delineating enhancing tumor, non-enhancing tumor, and surrounding non-enhancing T2/FLAIR hyperintensity. Participant automated segmentation models were evaluated and ranked based on a scoring system evaluating lesion-wise metrics including dice similarity coefficient (DSC) and 95% Hausdorff Distance. The top ranked team had a lesion-wise median dice similarity coefficient (DSC) of 0.976, 0.976, and 0.964 for enhancing tumor, tumor core, and whole tumor, respectively and a corresponding average DSC of 0.899, 0.904, and 0.871, respectively. These results serve as state-of-the-art benchmarks for future pre-operative meningioma automated segmentation algorithms. Additionally, we found that 1286 of 1424 cases (90.3%) had at least 1 compartment voxel abutting the edge of the skull-stripped image edge, which requires further investigation into optimal pre-processing face anonymization steps.
Panoptica -- instance-wise evaluation of 3D semantic and instance segmentation maps
Dec 05, 2023



This paper introduces panoptica, a versatile and performance-optimized package designed for computing instance-wise segmentation quality metrics from 2D and 3D segmentation maps. panoptica addresses the limitations of existing metrics and provides a modular framework that complements the original intersection over union-based panoptic quality with other metrics, such as the distance metric Average Symmetric Surface Distance. The package is open-source, implemented in Python, and accompanied by comprehensive documentation and tutorials. panoptica employs a three-step metrics computation process to cover diverse use cases. The efficacy of panoptica is demonstrated on various real-world biomedical datasets, where an instance-wise evaluation is instrumental for an accurate representation of the underlying clinical task. Overall, we envision panoptica as a valuable tool facilitating in-depth evaluation of segmentation methods.
DENTEX: An Abnormal Tooth Detection with Dental Enumeration and Diagnosis Benchmark for Panoramic X-rays
May 30, 2023

Panoramic X-rays are frequently used in dentistry for treatment planning, but their interpretation can be both time-consuming and prone to error. Artificial intelligence (AI) has the potential to aid in the analysis of these X-rays, thereby improving the accuracy of dental diagnoses and treatment plans. Nevertheless, designing automated algorithms for this purpose poses significant challenges, mainly due to the scarcity of annotated data and variations in anatomical structure. To address these issues, the Dental Enumeration and Diagnosis on Panoramic X-rays Challenge (DENTEX) has been organized in association with the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI) in 2023. This challenge aims to promote the development of algorithms for multi-label detection of abnormal teeth, using three types of hierarchically annotated data: partially annotated quadrant data, partially annotated quadrant-enumeration data, and fully annotated quadrant-enumeration-diagnosis data, inclusive of four different diagnoses. In this paper, we present the results of evaluating participant algorithms on the fully annotated data, additionally investigating performance variation for quadrant, enumeration, and diagnosis labels in the detection of abnormal teeth. The provision of this annotated dataset, alongside the results of this challenge, may lay the groundwork for the creation of AI-powered tools that can offer more precise and efficient diagnosis and treatment planning in the field of dentistry. The evaluation code and datasets can be accessed at https://github.com/ibrahimethemhamamci/DENTEX
GenerateCT: Text-Guided 3D Chest CT Generation
May 26, 2023Generative modeling has experienced substantial progress in recent years, particularly in text-to-image and text-to-video synthesis. However, the medical field has not yet fully exploited the potential of large-scale foundational models for synthetic data generation. In this paper, we introduce GenerateCT, the first method for text-conditional computed tomography (CT) generation, addressing the limitations in 3D medical imaging research and making our entire framework open-source. GenerateCT consists of a pre-trained large language model, a transformer-based text-conditional 3D chest CT generation architecture, and a text-conditional spatial super-resolution diffusion model. We also propose CT-ViT, which efficiently compresses CT volumes while preserving auto-regressiveness in-depth, enabling the generation of 3D CT volumes with variable numbers of axial slices. Our experiments demonstrate that GenerateCT can produce realistic, high-resolution, and high-fidelity 3D chest CT volumes consistent with medical language text prompts. We further investigate the potential of GenerateCT by training a model using generated CT volumes for multi-abnormality classification of chest CT volumes. Our contributions provide a valuable foundation for future research in text-conditional 3D medical image generation and have the potential to accelerate advancements in medical imaging research. Our code, pre-trained models, and generated data are available at https://github.com/ibrahimethemhamamci/GenerateCT.
Why is the winner the best?
Mar 30, 2023



International benchmarking competitions have become fundamental for the comparative performance assessment of image analysis methods. However, little attention has been given to investigating what can be learnt from these competitions. Do they really generate scientific progress? What are common and successful participation strategies? What makes a solution superior to a competing method? To address this gap in the literature, we performed a multi-center study with all 80 competitions that were conducted in the scope of IEEE ISBI 2021 and MICCAI 2021. Statistical analyses performed based on comprehensive descriptions of the submitted algorithms linked to their rank as well as the underlying participation strategies revealed common characteristics of winning solutions. These typically include the use of multi-task learning (63%) and/or multi-stage pipelines (61%), and a focus on augmentation (100%), image preprocessing (97%), data curation (79%), and postprocessing (66%). The "typical" lead of a winning team is a computer scientist with a doctoral degree, five years of experience in biomedical image analysis, and four years of experience in deep learning. Two core general development strategies stood out for highly-ranked teams: the reflection of the metrics in the method design and the focus on analyzing and handling failure cases. According to the organizers, 43% of the winning algorithms exceeded the state of the art but only 11% completely solved the respective domain problem. The insights of our study could help researchers (1) improve algorithm development strategies when approaching new problems, and (2) focus on open research questions revealed by this work.