 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDENTEX: An Abnormal Tooth Detection with Dental Enumeration and Diagnosis Benchmark for Panoramic X-rays
May 30, 2023

Panoramic X-rays are frequently used in dentistry for treatment planning, but their interpretation can be both time-consuming and prone to error. Artificial intelligence (AI) has the potential to aid in the analysis of these X-rays, thereby improving the accuracy of dental diagnoses and treatment plans. Nevertheless, designing automated algorithms for this purpose poses significant challenges, mainly due to the scarcity of annotated data and variations in anatomical structure. To address these issues, the Dental Enumeration and Diagnosis on Panoramic X-rays Challenge (DENTEX) has been organized in association with the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI) in 2023. This challenge aims to promote the development of algorithms for multi-label detection of abnormal teeth, using three types of hierarchically annotated data: partially annotated quadrant data, partially annotated quadrant-enumeration data, and fully annotated quadrant-enumeration-diagnosis data, inclusive of four different diagnoses. In this paper, we present the results of evaluating participant algorithms on the fully annotated data, additionally investigating performance variation for quadrant, enumeration, and diagnosis labels in the detection of abnormal teeth. The provision of this annotated dataset, alongside the results of this challenge, may lay the groundwork for the creation of AI-powered tools that can offer more precise and efficient diagnosis and treatment planning in the field of dentistry. The evaluation code and datasets can be accessed at https://github.com/ibrahimethemhamamci/DENTEX
Graph2Pix: A Graph-Based Image to Image Translation Framework
Aug 22, 2021
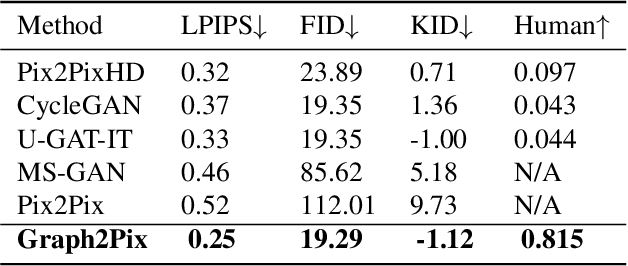
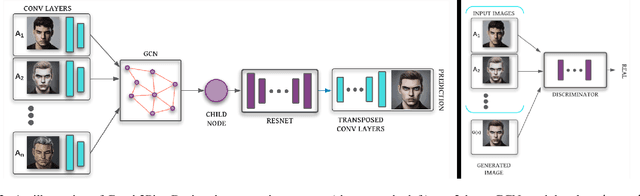
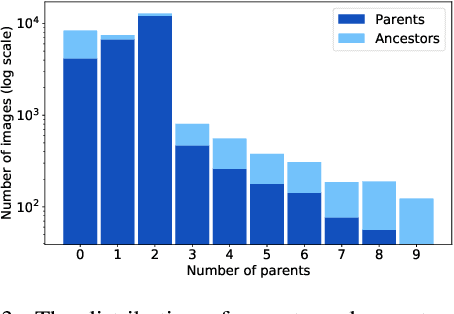
In this paper, we propose a graph-based image-to-image translation framework for generating images. We use rich data collected from the popular creativity platform Artbreeder (http://artbreeder.com), where users interpolate multiple GAN-generated images to create artworks. This unique approach of creating new images leads to a tree-like structure where one can track historical data about the creation of a particular image. Inspired by this structure, we propose a novel graph-to-image translation model called Graph2Pix, which takes a graph and corresponding images as input and generates a single image as output. Our experiments show that Graph2Pix is able to outperform several image-to-image translation frameworks on benchmark metrics, including LPIPS (with a 25% improvement) and human perception studies (n=60), where users preferred the images generated by our method 81.5% of the time. Our source code and dataset are publicly available at https://github.com/catlab-team/graph2pix.