 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeqLoRA: Bilevel Orthogonal Adaptation for Continual Multi-Concept Generation
May 21, 2026Parameter-efficient fine-tuning enables fast personalization of text-to-image diffusion models, but composing multiple custom concepts remains challenging due to representation interference. Existing modular methods either rely on expensive post-hoc fusion or freeze adaptation subspaces, which limit expressiveness and concept fidelity. To address this trade-off, we propose Sequential regularized LoRA (SeqLoRA), a constrained continual learning framework that jointly optimizes both LoRA factors via bilevel optimization. Theoretically, we establish strong convergence guarantees for our algorithm and model the residual layer activations as a matrix sub-Gaussian process to derive high-probability bounds on catastrophic forgetting. We further prove that learning the LoRA basis from data minimizes residual interference energy more effectively than frozen-basis methods. Experiments on multi-concept image generation demonstrate that SeqLoRA improves identity preservation and scalability across up to 101 concepts, while avoiding costly fusion and reducing attribute interference in composed generations.
FullFlow: Upgrading Text-to-Image Flow Matching Models for Bidirectional Vision--Language Generation
May 19, 2026Modern text-to-image diffusion models encode rich visual priors, but expose them only through one-way text-conditioned generation. Existing unified vision--language models derived from them recover bidirectional capability through large-scale joint pretraining or substantial retraining of the text pathway, discarding the strong image prior the text-to-image backbone already encodes. We introduce \emph{FullFlow}, a parameter-efficient recipe that upgrades a pretrained rectified-flow text-to-image model into a bidirectional vision--language generator by training only LoRA adapters and lightweight text heads. FullFlow keeps images in their native continuous flow and adds a discrete insertion process for text. Separate image and text timesteps turn inference into trajectory selection in a two-dimensional generative space, enabling text$\rightarrow$image, image$\rightarrow$text, joint sampling, and partial-text prediction with a single backbone. On Stable Diffusion 3 (SD3) under an identical trainable-parameter count and matched LoRA rank, FullFlow improves text$\rightarrow$image FID from $62.7$ to $31.6$ and image$\rightarrow$text CIDEr from $2.0$ to $99.4$ over a LoRA equivalent following the previous SOTA formulation (Dual Diffusion) at matched wall-clock training time, while reducing peak VRAM from ${\sim}84$\,GB to ${\sim}38$\,GB and raising throughput by ${\sim}8\times$ on two RTX A5000 GPUs in under 24 hours, training only ${\sim}5\%$ of the backbone parameters. The same recipe transfers to FLUX.1-dev and supports downstream VQA through partial-text generation. These results show that strong bidirectional vision--language capability can be unlocked from pretrained text-to-image flow models without full multimodal pretraining.
Shifting the Breaking Point of Flow Matching for Multi-Instance Editing
Feb 09, 2026Flow matching models have recently emerged as an efficient alternative to diffusion, especially for text-guided image generation and editing, offering faster inference through continuous-time dynamics. However, existing flow-based editors predominantly support global or single-instruction edits and struggle with multi-instance scenarios, where multiple parts of a reference input must be edited independently without semantic interference. We identify this limitation as a consequence of globally conditioned velocity fields and joint attention mechanisms, which entangle concurrent edits. To address this issue, we introduce Instance-Disentangled Attention, a mechanism that partitions joint attention operations, enforcing binding between instance-specific textual instructions and spatial regions during velocity field estimation. We evaluate our approach on both natural image editing and a newly introduced benchmark of text-dense infographics with region-level editing instructions. Experimental results demonstrate that our approach promotes edit disentanglement and locality while preserving global output coherence, enabling single-pass, instance-level editing.
Optimal Control Meets Flow Matching: A Principled Route to Multi-Subject Fidelity
Oct 02, 2025Text-to-image (T2I) models excel on single-entity prompts but struggle with multi-subject descriptions, often showing attribute leakage, identity entanglement, and subject omissions. We introduce the first theoretical framework with a principled, optimizable objective for steering sampling dynamics toward multi-subject fidelity. Viewing flow matching (FM) through stochastic optimal control (SOC), we formulate subject disentanglement as control over a trained FM sampler. This yields two architecture-agnostic algorithms: (i) a training-free test-time controller that perturbs the base velocity with a single-pass update, and (ii) Adjoint Matching, a lightweight fine-tuning rule that regresses a control network to a backward adjoint signal while preserving base-model capabilities. The same formulation unifies prior attention heuristics, extends to diffusion models via a flow-diffusion correspondence, and provides the first fine-tuning route explicitly designed for multi-subject fidelity. Empirically, on Stable Diffusion 3.5, FLUX, and Stable Diffusion XL, both algorithms consistently improve multi-subject alignment while maintaining base-model style. Test-time control runs efficiently on commodity GPUs, and fine-tuned controllers trained on limited prompts generalize to unseen ones. We further highlight FOCUS (Flow Optimal Control for Unentangled Subjects), which achieves state-of-the-art multi-subject fidelity across models.
RefAM: Attention Magnets for Zero-Shot Referral Segmentation
Sep 26, 2025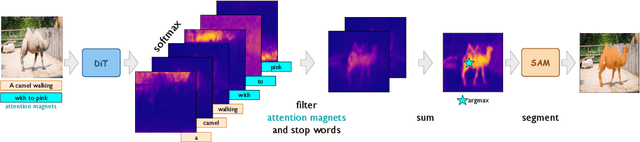
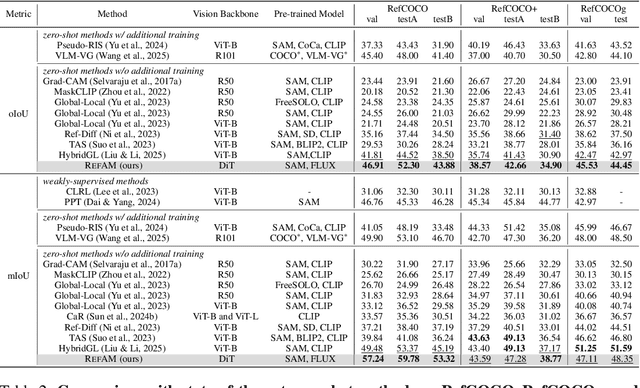

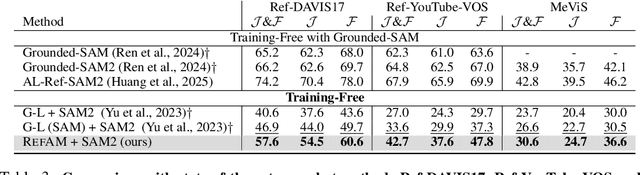
Most existing approaches to referring segmentation achieve strong performance only through fine-tuning or by composing multiple pre-trained models, often at the cost of additional training and architectural modifications. Meanwhile, large-scale generative diffusion models encode rich semantic information, making them attractive as general-purpose feature extractors. In this work, we introduce a new method that directly exploits features, attention scores, from diffusion transformers for downstream tasks, requiring neither architectural modifications nor additional training. To systematically evaluate these features, we extend benchmarks with vision-language grounding tasks spanning both images and videos. Our key insight is that stop words act as attention magnets: they accumulate surplus attention and can be filtered to reduce noise. Moreover, we identify global attention sinks (GAS) emerging in deeper layers and show that they can be safely suppressed or redirected onto auxiliary tokens, leading to sharper and more accurate grounding maps. We further propose an attention redistribution strategy, where appended stop words partition background activations into smaller clusters, yielding sharper and more localized heatmaps. Building on these findings, we develop RefAM, a simple training-free grounding framework that combines cross-attention maps, GAS handling, and redistribution. Across zero-shot referring image and video segmentation benchmarks, our approach consistently outperforms prior methods, establishing a new state of the art without fine-tuning or additional components.
JEDI: The Force of Jensen-Shannon Divergence in Disentangling Diffusion Models
May 25, 2025We introduce JEDI, a test-time adaptation method that enhances subject separation and compositional alignment in diffusion models without requiring retraining or external supervision. JEDI operates by minimizing semantic entanglement in attention maps using a novel Jensen-Shannon divergence based objective. To improve efficiency, we leverage adversarial optimization, reducing the number of updating steps required. JEDI is model-agnostic and applicable to architectures such as Stable Diffusion 1.5 and 3.5, consistently improving prompt alignment and disentanglement in complex scenes. Additionally, JEDI provides a lightweight, CLIP-free disentanglement score derived from internal attention distributions, offering a principled benchmark for compositional alignment under test-time conditions. We will publicly release the implementation of our method.
IC-Portrait: In-Context Matching for View-Consistent Personalized Portrait
Jan 31, 2025Existing diffusion models show great potential for identity-preserving generation. However, personalized portrait generation remains challenging due to the diversity in user profiles, including variations in appearance and lighting conditions. To address these challenges, we propose IC-Portrait, a novel framework designed to accurately encode individual identities for personalized portrait generation. Our key insight is that pre-trained diffusion models are fast learners (e.g.,100 ~ 200 steps) for in-context dense correspondence matching, which motivates the two major designs of our IC-Portrait framework. Specifically, we reformulate portrait generation into two sub-tasks: 1) Lighting-Aware Stitching: we find that masking a high proportion of the input image, e.g., 80%, yields a highly effective self-supervisory representation learning of reference image lighting. 2) View-Consistent Adaptation: we leverage a synthetic view-consistent profile dataset to learn the in-context correspondence. The reference profile can then be warped into arbitrary poses for strong spatial-aligned view conditioning. Coupling these two designs by simply concatenating latents to form ControlNet-like supervision and modeling, enables us to significantly enhance the identity preservation fidelity and stability. Extensive evaluations demonstrate that IC-Portrait consistently outperforms existing state-of-the-art methods both quantitatively and qualitatively, with particularly notable improvements in visual qualities. Furthermore, IC-Portrait even demonstrates 3D-aware relighting capabilities.
SHYI: Action Support for Contrastive Learning in High-Fidelity Text-to-Image Generation
Jan 15, 2025

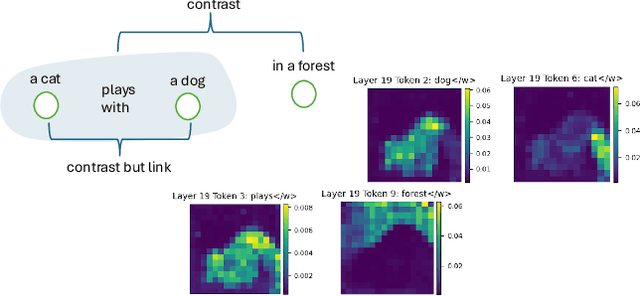

In this project, we address the issue of infidelity in text-to-image generation, particularly for actions involving multiple objects. For this we build on top of the CONFORM framework which uses Contrastive Learning to improve the accuracy of the generated image for multiple objects. However the depiction of actions which involves multiple different object has still large room for improvement. To improve, we employ semantically hypergraphic contrastive adjacency learning, a comprehension of enhanced contrastive structure and "contrast but link" technique. We further amend Stable Diffusion's understanding of actions by InteractDiffusion. As evaluation metrics we use image-text similarity CLIP and TIFA. In addition, we conducted a user study. Our method shows promising results even with verbs that Stable Diffusion understands mediocrely. We then provide future directions by analyzing the results. Our codebase can be found on polybox under the link: https://polybox.ethz.ch/index.php/s/dJm3SWyRohUrFxn
UIP2P: Unsupervised Instruction-based Image Editing via Cycle Edit Consistency
Dec 19, 2024



We propose an unsupervised model for instruction-based image editing that eliminates the need for ground-truth edited images during training. Existing supervised methods depend on datasets containing triplets of input image, edited image, and edit instruction. These are generated by either existing editing methods or human-annotations, which introduce biases and limit their generalization ability. Our method addresses these challenges by introducing a novel editing mechanism called Cycle Edit Consistency (CEC), which applies forward and backward edits in one training step and enforces consistency in image and attention spaces. This allows us to bypass the need for ground-truth edited images and unlock training for the first time on datasets comprising either real image-caption pairs or image-caption-edit triplets. We empirically show that our unsupervised technique performs better across a broader range of edits with high fidelity and precision. By eliminating the need for pre-existing datasets of triplets, reducing biases associated with supervised methods, and proposing CEC, our work represents a significant advancement in unblocking scaling of instruction-based image editing.
LoRACLR: Contrastive Adaptation for Customization of Diffusion Models
Dec 12, 2024Recent advances in text-to-image customization have enabled high-fidelity, context-rich generation of personalized images, allowing specific concepts to appear in a variety of scenarios. However, current methods struggle with combining multiple personalized models, often leading to attribute entanglement or requiring separate training to preserve concept distinctiveness. We present LoRACLR, a novel approach for multi-concept image generation that merges multiple LoRA models, each fine-tuned for a distinct concept, into a single, unified model without additional individual fine-tuning. LoRACLR uses a contrastive objective to align and merge the weight spaces of these models, ensuring compatibility while minimizing interference. By enforcing distinct yet cohesive representations for each concept, LoRACLR enables efficient, scalable model composition for high-quality, multi-concept image synthesis. Our results highlight the effectiveness of LoRACLR in accurately merging multiple concepts, advancing the capabilities of personalized image generation.