 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConceptAttention: Diffusion Transformers Learn Highly Interpretable Features
Feb 06, 2025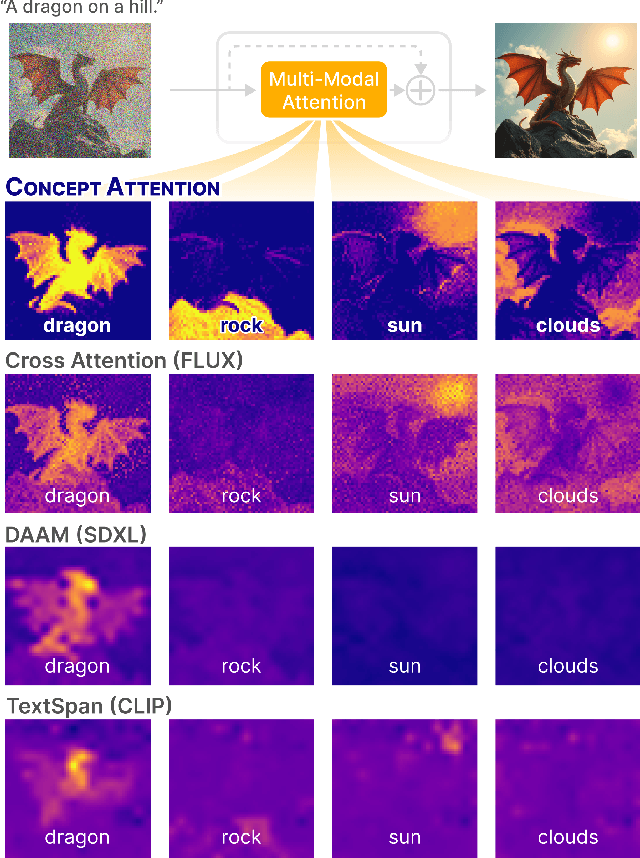
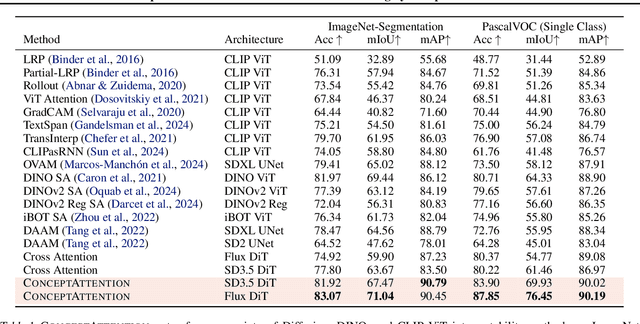
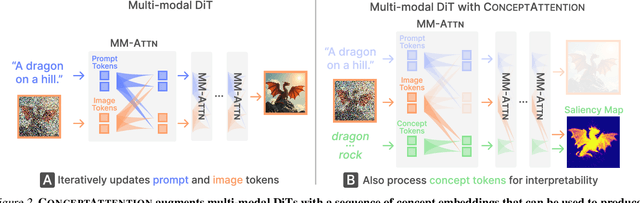
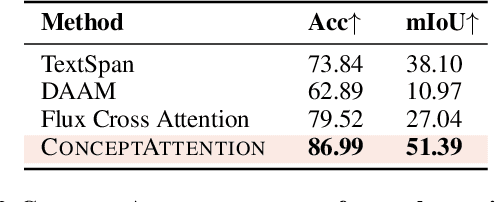
Do the rich representations of multi-modal diffusion transformers (DiTs) exhibit unique properties that enhance their interpretability? We introduce ConceptAttention, a novel method that leverages the expressive power of DiT attention layers to generate high-quality saliency maps that precisely locate textual concepts within images. Without requiring additional training, ConceptAttention repurposes the parameters of DiT attention layers to produce highly contextualized concept embeddings, contributing the major discovery that performing linear projections in the output space of DiT attention layers yields significantly sharper saliency maps compared to commonly used cross-attention mechanisms. Remarkably, ConceptAttention even achieves state-of-the-art performance on zero-shot image segmentation benchmarks, outperforming 11 other zero-shot interpretability methods on the ImageNet-Segmentation dataset and on a single-class subset of PascalVOC. Our work contributes the first evidence that the representations of multi-modal DiT models like Flux are highly transferable to vision tasks like segmentation, even outperforming multi-modal foundation models like CLIP.
MotionFlow: Attention-Driven Motion Transfer in Video Diffusion Models
Dec 06, 2024Text-to-video models have demonstrated impressive capabilities in producing diverse and captivating video content, showcasing a notable advancement in generative AI. However, these models generally lack fine-grained control over motion patterns, limiting their practical applicability. We introduce MotionFlow, a novel framework designed for motion transfer in video diffusion models. Our method utilizes cross-attention maps to accurately capture and manipulate spatial and temporal dynamics, enabling seamless motion transfers across various contexts. Our approach does not require training and works on test-time by leveraging the inherent capabilities of pre-trained video diffusion models. In contrast to traditional approaches, which struggle with comprehensive scene changes while maintaining consistent motion, MotionFlow successfully handles such complex transformations through its attention-based mechanism. Our qualitative and quantitative experiments demonstrate that MotionFlow significantly outperforms existing models in both fidelity and versatility even during drastic scene alterations.
MotionShop: Zero-Shot Motion Transfer in Video Diffusion Models with Mixture of Score Guidance
Dec 06, 2024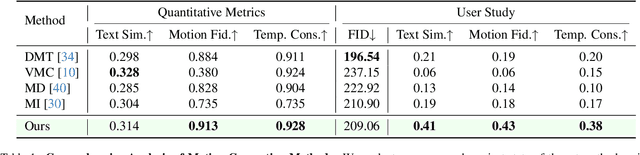


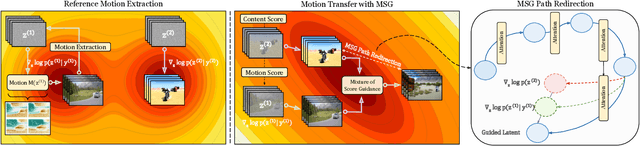
In this work, we propose the first motion transfer approach in diffusion transformer through Mixture of Score Guidance (MSG), a theoretically-grounded framework for motion transfer in diffusion models. Our key theoretical contribution lies in reformulating conditional score to decompose motion score and content score in diffusion models. By formulating motion transfer as a mixture of potential energies, MSG naturally preserves scene composition and enables creative scene transformations while maintaining the integrity of transferred motion patterns. This novel sampling operates directly on pre-trained video diffusion models without additional training or fine-tuning. Through extensive experiments, MSG demonstrates successful handling of diverse scenarios including single object, multiple objects, and cross-object motion transfer as well as complex camera motion transfer. Additionally, we introduce MotionBench, the first motion transfer dataset consisting of 200 source videos and 1000 transferred motions, covering single/multi-object transfers, and complex camera motions.
CLoRA: A Contrastive Approach to Compose Multiple LoRA Models
Mar 28, 2024



Low-Rank Adaptations (LoRAs) have emerged as a powerful and popular technique in the field of image generation, offering a highly effective way to adapt and refine pre-trained deep learning models for specific tasks without the need for comprehensive retraining. By employing pre-trained LoRA models, such as those representing a specific cat and a particular dog, the objective is to generate an image that faithfully embodies both animals as defined by the LoRAs. However, the task of seamlessly blending multiple concept LoRAs to capture a variety of concepts in one image proves to be a significant challenge. Common approaches often fall short, primarily because the attention mechanisms within different LoRA models overlap, leading to scenarios where one concept may be completely ignored (e.g., omitting the dog) or where concepts are incorrectly combined (e.g., producing an image of two cats instead of one cat and one dog). To overcome these issues, CLoRA addresses them by updating the attention maps of multiple LoRA models and leveraging them to create semantic masks that facilitate the fusion of latent representations. Our method enables the creation of composite images that truly reflect the characteristics of each LoRA, successfully merging multiple concepts or styles. Our comprehensive evaluations, both qualitative and quantitative, demonstrate that our approach outperforms existing methodologies, marking a significant advancement in the field of image generation with LoRAs. Furthermore, we share our source code, benchmark dataset, and trained LoRA models to promote further research on this topic.
Conditional Information Gain Trellis
Feb 13, 2024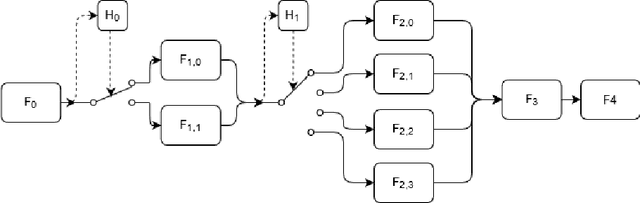
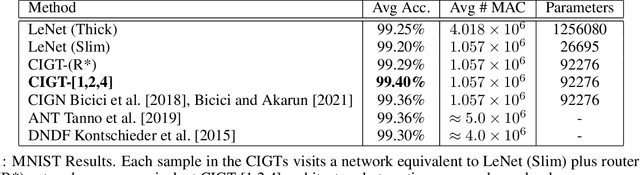
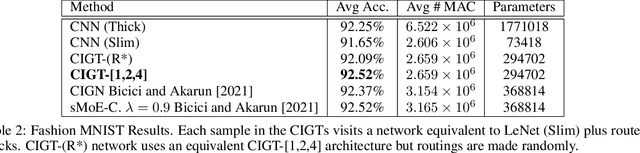

Conditional computing processes an input using only part of the neural network's computational units. Learning to execute parts of a deep convolutional network by routing individual samples has several advantages: Reducing the computational burden is an obvious advantage. Furthermore, if similar classes are routed to the same path, that part of the network learns to discriminate between finer differences and better classification accuracies can be attained with fewer parameters. Recently, several papers have exploited this idea to take a particular child of a node in a tree-shaped network or to skip parts of a network. In this work, we follow a Trellis-based approach for generating specific execution paths in a deep convolutional neural network. We have designed routing mechanisms that use differentiable information gain-based cost functions to determine which subset of features in a convolutional layer will be executed. We call our method Conditional Information Gain Trellis (CIGT). We show that our conditional execution mechanism achieves comparable or better model performance compared to unconditional baselines, using only a fraction of the computational resources.
CONFORM: Contrast is All You Need For High-Fidelity Text-to-Image Diffusion Models
Dec 11, 2023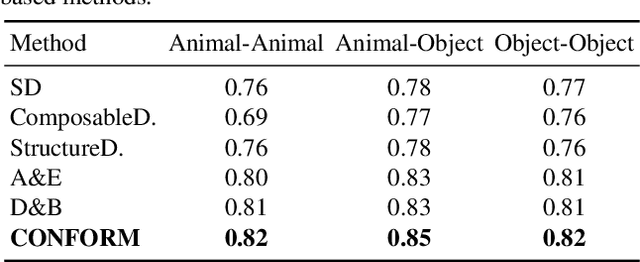

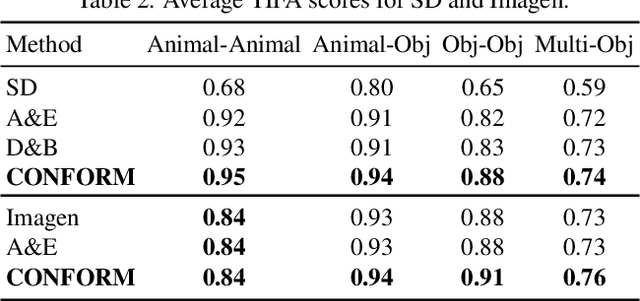
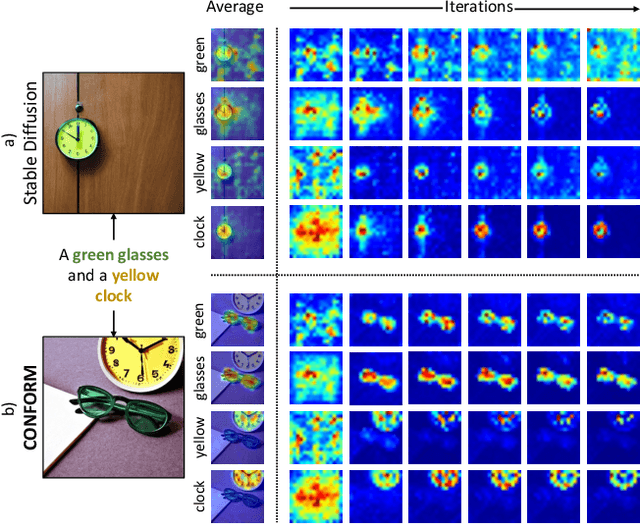
Images produced by text-to-image diffusion models might not always faithfully represent the semantic intent of the provided text prompt, where the model might overlook or entirely fail to produce certain objects. Existing solutions often require customly tailored functions for each of these problems, leading to sub-optimal results, especially for complex prompts. Our work introduces a novel perspective by tackling this challenge in a contrastive context. Our approach intuitively promotes the segregation of objects in attention maps while also maintaining that pairs of related attributes are kept close to each other. We conduct extensive experiments across a wide variety of scenarios, each involving unique combinations of objects, attributes, and scenes. These experiments effectively showcase the versatility, efficiency, and flexibility of our method in working with both latent and pixel-based diffusion models, including Stable Diffusion and Imagen. Moreover, we publicly share our source code to facilitate further research.