 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Explorer: Interactive Exploration of Diffusion Models
Jul 01, 2025Diffusion models have been central to the development of recent image, video, and even text generation systems. They posses striking geometric properties that can be faithfully portrayed in low-dimensional settings. However, existing resources for explaining diffusion either require an advanced theoretical foundation or focus on their neural network architectures rather than their rich geometric properties. We introduce Diffusion Explorer, an interactive tool to explain the geometric properties of diffusion models. Users can train 2D diffusion models in the browser and observe the temporal dynamics of their sampling process. Diffusion Explorer leverages interactive animation, which has been shown to be a powerful tool for making engaging visualizations of dynamic systems, making it well suited to explaining diffusion models which represent stochastic processes that evolve over time. Diffusion Explorer is open source and a live demo is available at alechelbling.com/Diffusion-Explorer.
Interpretation Meets Safety: A Survey on Interpretation Methods and Tools for Improving LLM Safety
Jun 05, 2025As large language models (LLMs) see wider real-world use, understanding and mitigating their unsafe behaviors is critical. Interpretation techniques can reveal causes of unsafe outputs and guide safety, but such connections with safety are often overlooked in prior surveys. We present the first survey that bridges this gap, introducing a unified framework that connects safety-focused interpretation methods, the safety enhancements they inform, and the tools that operationalize them. Our novel taxonomy, organized by LLM workflow stages, summarizes nearly 70 works at their intersections. We conclude with open challenges and future directions. This timely survey helps researchers and practitioners navigate key advancements for safer, more interpretable LLMs.
Shape it Up! Restoring LLM Safety during Finetuning
May 22, 2025Finetuning large language models (LLMs) enables user-specific customization but introduces critical safety risks: even a few harmful examples can compromise safety alignment. A common mitigation strategy is to update the model more strongly on examples deemed safe, while downweighting or excluding those flagged as unsafe. However, because safety context can shift within a single example, updating the model equally on both harmful and harmless parts of a response is suboptimal-a coarse treatment we term static safety shaping. In contrast, we propose dynamic safety shaping (DSS), a framework that uses fine-grained safety signals to reinforce learning from safe segments of a response while suppressing unsafe content. To enable such fine-grained control during finetuning, we introduce a key insight: guardrail models, traditionally used for filtering, can be repurposed to evaluate partial responses, tracking how safety risk evolves throughout the response, segment by segment. This leads to the Safety Trajectory Assessment of Response (STAR), a token-level signal that enables shaping to operate dynamically over the training sequence. Building on this, we present STAR-DSS, guided by STAR scores, that robustly mitigates finetuning risks and delivers substantial safety improvements across diverse threats, datasets, and model families-all without compromising capability on intended tasks. We encourage future safety research to build on dynamic shaping principles for stronger mitigation against evolving finetuning risks.
ConceptAttention: Diffusion Transformers Learn Highly Interpretable Features
Feb 06, 2025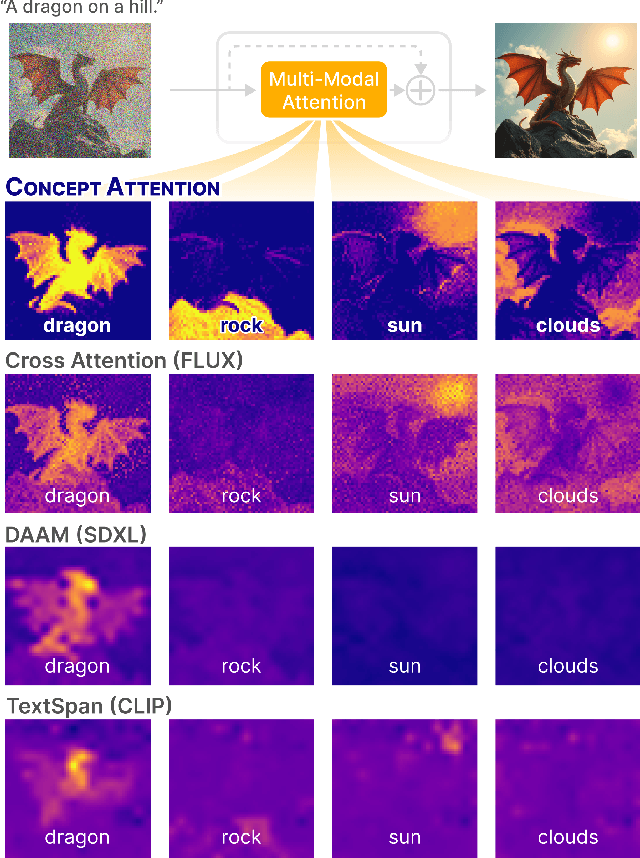
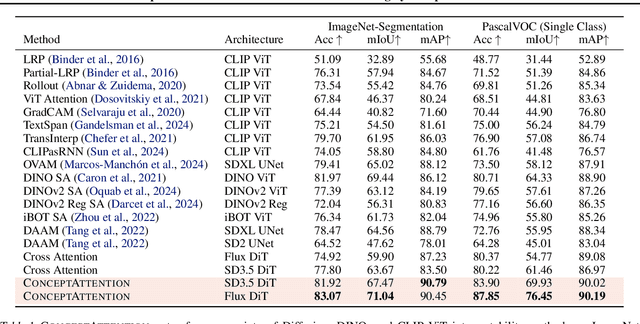
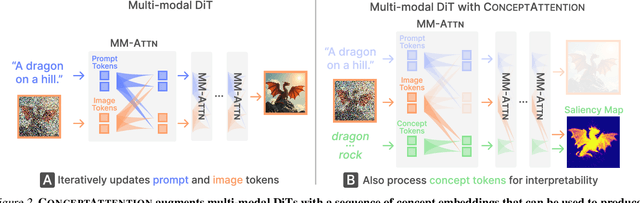
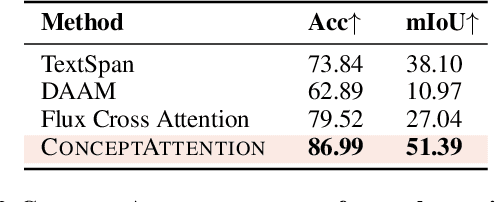
Do the rich representations of multi-modal diffusion transformers (DiTs) exhibit unique properties that enhance their interpretability? We introduce ConceptAttention, a novel method that leverages the expressive power of DiT attention layers to generate high-quality saliency maps that precisely locate textual concepts within images. Without requiring additional training, ConceptAttention repurposes the parameters of DiT attention layers to produce highly contextualized concept embeddings, contributing the major discovery that performing linear projections in the output space of DiT attention layers yields significantly sharper saliency maps compared to commonly used cross-attention mechanisms. Remarkably, ConceptAttention even achieves state-of-the-art performance on zero-shot image segmentation benchmarks, outperforming 11 other zero-shot interpretability methods on the ImageNet-Segmentation dataset and on a single-class subset of PascalVOC. Our work contributes the first evidence that the representations of multi-modal DiT models like Flux are highly transferable to vision tasks like segmentation, even outperforming multi-modal foundation models like CLIP.
Adversarial Attacks Using Differentiable Rendering: A Survey
Nov 14, 2024Differentiable rendering methods have emerged as a promising means for generating photo-realistic and physically plausible adversarial attacks by manipulating 3D objects and scenes that can deceive deep neural networks (DNNs). Recently, differentiable rendering capabilities have evolved significantly into a diverse landscape of libraries, such as Mitsuba, PyTorch3D, and methods like Neural Radiance Fields and 3D Gaussian Splatting for solving inverse rendering problems that share conceptually similar properties commonly used to attack DNNs, such as back-propagation and optimization. However, the adversarial machine learning research community has not yet fully explored or understood such capabilities for generating attacks. Some key reasons are that researchers often have different attack goals, such as misclassification or misdetection, and use different tasks to accomplish these goals by manipulating different representation in a scene, such as the mesh or texture of an object. This survey adopts a task-oriented unifying framework that systematically summarizes common tasks, such as manipulating textures, altering illumination, and modifying 3D meshes to exploit vulnerabilities in DNNs. Our framework enables easy comparison of existing works, reveals research gaps and spotlights exciting future research directions in this rapidly evolving field. Through focusing on how these tasks enable attacks on various DNNs such as image classification, facial recognition, object detection, optical flow and depth estimation, our survey helps researchers and practitioners better understand the vulnerabilities of computer vision systems against photorealistic adversarial attacks that could threaten real-world applications.
Semi-Truths: A Large-Scale Dataset of AI-Augmented Images for Evaluating Robustness of AI-Generated Image detectors
Nov 12, 2024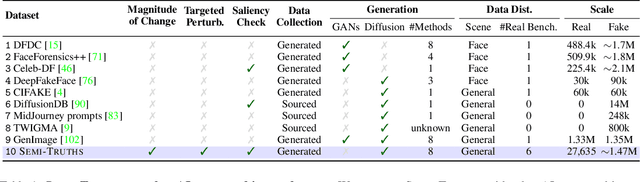
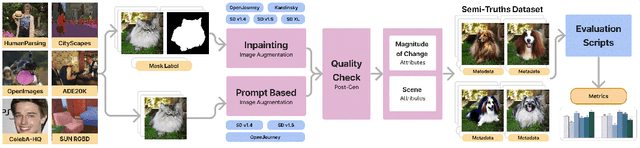

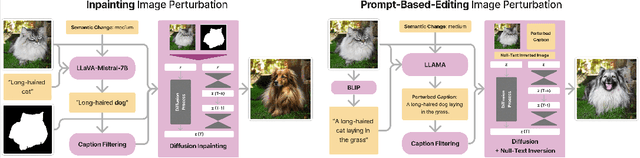
Text-to-image diffusion models have impactful applications in art, design, and entertainment, yet these technologies also pose significant risks by enabling the creation and dissemination of misinformation. Although recent advancements have produced AI-generated image detectors that claim robustness against various augmentations, their true effectiveness remains uncertain. Do these detectors reliably identify images with different levels of augmentation? Are they biased toward specific scenes or data distributions? To investigate, we introduce SEMI-TRUTHS, featuring 27,600 real images, 223,400 masks, and 1,472,700 AI-augmented images that feature targeted and localized perturbations produced using diverse augmentation techniques, diffusion models, and data distributions. Each augmented image is accompanied by metadata for standardized and targeted evaluation of detector robustness. Our findings suggest that state-of-the-art detectors exhibit varying sensitivities to the types and degrees of perturbations, data distributions, and augmentation methods used, offering new insights into their performance and limitations. The code for the augmentation and evaluation pipeline is available at https://github.com/J-Kruk/SemiTruths.
Dense Associative Memory Through the Lens of Random Features
Oct 31, 2024

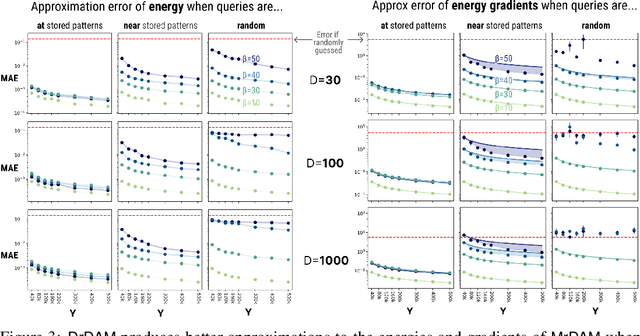
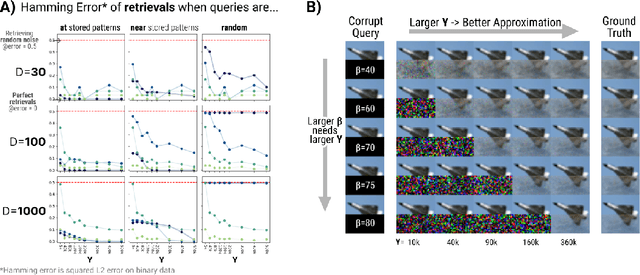
Dense Associative Memories are high storage capacity variants of the Hopfield networks that are capable of storing a large number of memory patterns in the weights of the network of a given size. Their common formulations typically require storing each pattern in a separate set of synaptic weights, which leads to the increase of the number of synaptic weights when new patterns are introduced. In this work we propose an alternative formulation of this class of models using random features, commonly used in kernel methods. In this formulation the number of network's parameters remains fixed. At the same time, new memories can be added to the network by modifying existing weights. We show that this novel network closely approximates the energy function and dynamics of conventional Dense Associative Memories and shares their desirable computational properties.
Transformer Explainer: Interactive Learning of Text-Generative Models
Aug 08, 2024
Transformers have revolutionized machine learning, yet their inner workings remain opaque to many. We present Transformer Explainer, an interactive visualization tool designed for non-experts to learn about Transformers through the GPT-2 model. Our tool helps users understand complex Transformer concepts by integrating a model overview and enabling smooth transitions across abstraction levels of mathematical operations and model structures. It runs a live GPT-2 instance locally in the user's browser, empowering users to experiment with their own input and observe in real-time how the internal components and parameters of the Transformer work together to predict the next tokens. Our tool requires no installation or special hardware, broadening the public's education access to modern generative AI techniques. Our open-sourced tool is available at https://poloclub.github.io/transformer-explainer/. A video demo is available at https://youtu.be/ECR4oAwocjs.
MeMemo: On-device Retrieval Augmentation for Private and Personalized Text Generation
Jul 02, 2024Retrieval-augmented text generation (RAG) addresses the common limitations of large language models (LLMs), such as hallucination, by retrieving information from an updatable external knowledge base. However, existing approaches often require dedicated backend servers for data storage and retrieval, thereby limiting their applicability in use cases that require strict data privacy, such as personal finance, education, and medicine. To address the pressing need for client-side dense retrieval, we introduce MeMemo, the first open-source JavaScript toolkit that adapts the state-of-the-art approximate nearest neighbor search technique HNSW to browser environments. Developed with modern and native Web technologies, such as IndexedDB and Web Workers, our toolkit leverages client-side hardware capabilities to enable researchers and developers to efficiently search through millions of high-dimensional vectors in the browser. MeMemo enables exciting new design and research opportunities, such as private and personalized content creation and interactive prototyping, as demonstrated in our example application RAG Playground. Reflecting on our work, we discuss the opportunities and challenges for on-device dense retrieval. MeMemo is available at https://github.com/poloclub/mememo.
Navigating the Safety Landscape: Measuring Risks in Finetuning Large Language Models
May 28, 2024Safety alignment is the key to guiding the behaviors of large language models (LLMs) that are in line with human preferences and restrict harmful behaviors at inference time, but recent studies show that it can be easily compromised by finetuning with only a few adversarially designed training examples. We aim to measure the risks in finetuning LLMs through navigating the LLM safety landscape. We discover a new phenomenon observed universally in the model parameter space of popular open-source LLMs, termed as "safety basin": randomly perturbing model weights maintains the safety level of the original aligned model in its local neighborhood. Our discovery inspires us to propose the new VISAGE safety metric that measures the safety in LLM finetuning by probing its safety landscape. Visualizing the safety landscape of the aligned model enables us to understand how finetuning compromises safety by dragging the model away from the safety basin. LLM safety landscape also highlights the system prompt's critical role in protecting a model, and that such protection transfers to its perturbed variants within the safety basin. These observations from our safety landscape research provide new insights for future work on LLM safety community.