 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo2Sim2Real: Full-Stack Autonomous Dexterous Skill Acquisition from a Single Human Video
Jun 07, 2026Human manipulation videos are a convenient and intuitive source for robot learning. However, directly transferring human dexterity to robots remains challenging due to perception errors and embodiment gap. To address this, we introduce Video2Sim2Real, a full-stack framework for autonomous skill acquisition from a single human manipulation video. Our framework first uses off-the-shelf foundation models to reconstruct a simulator-ready digital twin and extract robot and object motion priors. Rather than treating the extracted robot motion as a reliable reference throughout execution, our key idea is to recover and leverage the most fundamental sources of supervision from the demonstrated skill: We identify object-centric keyframes to optimize the corresponding robot configurations using object information from the simulator, and use these configurations as anchors that refine the robot motion such that it ultimately has the desired impact on the environment. To bridge the remaining sim-to-real gap, we introduce a sim-to-real strategy that decouples robustness to noisy and incomplete perception from variations in hand-object interaction dynamics. Specifically, we learn to recalibrate robot configurations from noisy real-world point clouds via IL, and leverage residual RL to perform local finger-level adaptations to ensure for robust and effective interactions. Finally, a collision-aware motion planning module enables spatial generalization to novel object configurations. Across several everyday manipulation tasks, Video2Sim2Real improves simulated task success, safety, and trajectory coherence over numerous baselines, and achieves better sim-to-real transfer than existing techniques. These results demonstrate a promising path toward autonomous dexterous skill acquisition from human videos.
SeeTraceAct: Visibility-Aware Latent Planning from Cross-Embodiment Demonstration Videos
Jun 01, 2026Vision-language-action models (VLAs) are promising general-purpose robot policies, but adapting them to new tasks typically requires costly task-specific teleoperation data. As an alternative, we study one-shot demo-conditioned VLAs, where a robot policy is conditioned on a single demonstration video of an unseen task. We find that existing end-to-end approaches often struggle when successful execution requires precisely localizing small target regions. To address this limitation, we propose SeeTraceAct, a demo-conditioned VLA framework that encourages precise spatial grounding through visibility-aware prediction of future end-effector traces. To enable reproducible evaluation with cross-embodiment demonstrations, we introduce and release RoboCasa-DC, a demo-conditioned extension of RoboCasa with episode-paired humanoid videos. Experiments on RoboCasa-DC and a real-world benchmark, where a Franka Panda arm is conditioned on human demonstrations, show that SeeTraceAct outperforms baselines, achieving the best success rate across all four RoboCasa-DC settings and improving real-world average success by 12.5 percentage points.
Hide-and-Seek in Trajectories: Discovering Failure Signals for VLA Runtime Monitoring
May 29, 2026Vision-Language-Action (VLA) models enable robots to follow natural language instructions and generalize across diverse tasks, but they remain vulnerable to execution failures that compromise reliability in real-world deployment. Detecting such failures during execution is therefore critical for the robust deployment of embodied systems. Existing failure detection methods either rely on expensive action resampling or external models, while alternatives propagate trajectory-level labels uniformly across every timestep, obscuring localized failure signals. In this paper, we propose \textbf{Hide-and-Seek}, a framework that formulates VLA failure detection as a coarsely supervised learning problem. By combining inter-trajectory and intra-trajectory contrastive objectives, Hide-and-Seek localizes failure-indicative actions and induces temporally structured failure signals from trajectory-level supervision alone, without any step-level annotation. We evaluate Hide-and-Seek on LIBERO, VLABench, and a real-world robotic platform across three representative VLA policies: OpenVLA, $π_0$, and $π_{0.5}$.Our method achieves state-of-the-art multi-task failure detection performance with a practical accuracy--timeliness trade-off under conformal prediction, and generalizes well to both seen and unseen tasks.
SafeManip: A Property-Driven Benchmark for Temporal Safety Evaluation in Robotic Manipulation
May 12, 2026Robotic manipulation is typically evaluated by task success, but successful completion does not guarantee safe execution. Many safety failures are temporal: a robot may touch a clean surface after contamination or release an object before it is fully inside an enclosure. We introduce SafeManip, a property-driven benchmark to explicitly evaluate temporal safety properties in robotic manipulation, moving beyond prior evaluations that largely focus on task completion or per-state constraint violations. SafeManip defines reusable safety templates over finite executions using Linear Temporal Logic over finite traces (LTLf). It maps observed rollouts to symbolic predicate traces and evaluates them with LTLf-based monitors. Its property suite covers eight manipulation safety categories: collision and contact safety, grasp stability, release stability, cross-contamination, action onset, mechanism recovery, object containment, and enclosure access. Templates can be instantiated with task-specific objects, fixtures, regions, or skills, allowing the same safety specifications to generalize across tasks and environments. We evaluate SafeManip on six vision-language-action policies, including $π_0$, $π_{0.5}$, GR00T, and their training variants, across 50 RoboCasa365 household tasks. Results show that even strong models often behave unsafely. Task-success gains do not reliably translate into safer execution: many successful rollouts remain unsafe, while longer-horizon or more complex tasks expose more violations. SafeManip provides a reusable evaluation layer for diagnosing temporal safety failures and measuring safe success beyond task completion.
SAGE: Sink-Aware Grounded Decoding for Multimodal Hallucination Mitigation
Mar 29, 2026Large vision-language models (VLMs) frequently suffer from hallucinations, generating content that is inconsistent with visual inputs. Existing methods typically address this problem through post-hoc filtering, additional training objectives, or external verification, but they do not intervene during the decoding process when hallucinations arise. In this work, we introduce SAGE, a Sink-Aware Grounded Decoding framework that mitigates hallucinations by dynamically modulating self-attention during generation. Hallucinations are strongly correlated with attention sink tokens - punctuation or function tokens that accumulate disproportionate attention despite carrying limited semantic content. SAGE leverages these tokens as anchors to monitor grounding reliability in real time. At each sink trigger, the method extracts semantic concepts from the generated sequence, estimates their visual grounding using both self-attention maps and gradient-based attribution, and measures their spatial agreement. Based on this signal, self-attention distributions are adaptively sharpened or broadened to reinforce grounded regions or suppress unreliable ones. Extensive experiments across diverse hallucination benchmarks demonstrate that SAGE consistently outperforms existing decoding strategies, achieving substantial reductions in hallucination while preserving descriptive coverage, without requiring model retraining or architectural modifications. Our method achieves an average relative improvement of 10.65% on MSCOCO and 7.19% on AMBER across diverse VLM architectures, demonstrating consistent gains in hallucination mitigation.
The Geometry of Robustness: Optimizing Loss Landscape Curvature and Feature Manifold Alignment for Robust Finetuning of Vision-Language Models
Mar 28, 2026Fine-tuning approaches for Vision-Language Models (VLMs) face a critical three-way trade-off between In-Distribution (ID) accuracy, Out-of-Distribution (OOD) generalization, and adversarial robustness. Existing robust fine-tuning strategies resolve at most two axes of this trade-off. Generalization-preserving methods retain ID/OOD performance but leave models vulnerable to adversarial attacks, while adversarial training improves robustness to targeted attacks but degrades ID/OOD accuracy. Our key insight is that the robustness trade-off stems from two geometric failures: sharp, anisotropic minima in parameter space and unstable feature representations that deform under perturbation. To address this, we propose GRACE (Gram-aligned Robustness via Adaptive Curvature Estimation), a unified fine-tuning framework that jointly regularizes the parameter-space curvature and feature-space invariance for VLMs. Grounded in Robust PAC-Bayes theory, GRACE employs adaptive weight perturbations scaled by local curvature to promote flatter minima, combined with a feature alignment loss that maintains representation consistency across clean, adversarial, and OOD inputs. On ImageNet fine-tuning of CLIP models, GRACE simultaneously improves ID accuracy by 10.8%, and adversarial accuracy by 13.5% while maintaining 57.0% OOD accuracy (vs. 57.4% zero-shot baseline). Geometric analysis confirms that GRACE converges to flatter minima without feature distortion across distribution shifts, providing a principled step toward generalized robustness in foundation VLMs.
Sim2real Image Translation Enables Viewpoint-Robust Policies from Fixed-Camera Datasets
Jan 14, 2026Vision-based policies for robot manipulation have achieved significant recent success, but are still brittle to distribution shifts such as camera viewpoint variations. Robot demonstration data is scarce and often lacks appropriate variation in camera viewpoints. Simulation offers a way to collect robot demonstrations at scale with comprehensive coverage of different viewpoints, but presents a visual sim2real challenge. To bridge this gap, we propose MANGO -- an unpaired image translation method with a novel segmentation-conditioned InfoNCE loss, a highly-regularized discriminator design, and a modified PatchNCE loss. We find that these elements are crucial for maintaining viewpoint consistency during sim2real translation. When training MANGO, we only require a small amount of fixed-camera data from the real world, but show that our method can generate diverse unseen viewpoints by translating simulated observations. In this domain, MANGO outperforms all other image translation methods we tested. Imitation-learning policies trained on data augmented by MANGO are able to achieve success rates as high as 60\% on views that the non-augmented policy fails completely on.
EVE: A Generator-Verifier System for Generative Policies
Dec 24, 2025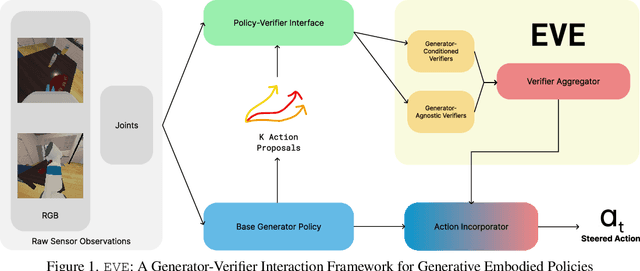
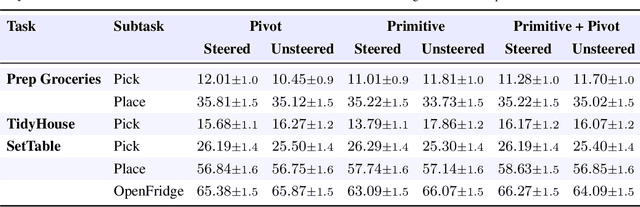
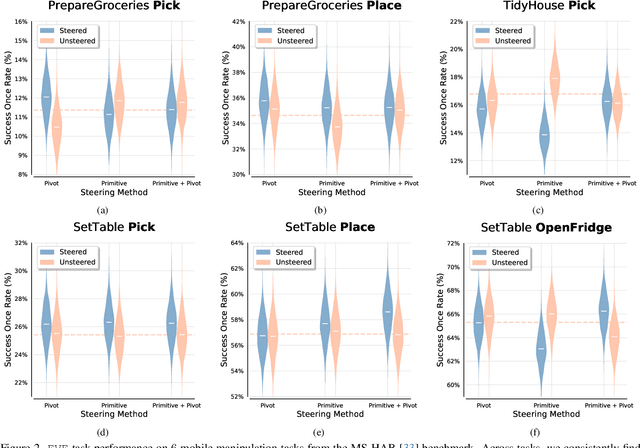

Visuomotor policies based on generative architectures such as diffusion and flow-based matching have shown strong performance but degrade under distribution shifts, demonstrating limited recovery capabilities without costly finetuning. In the language modeling domain, test-time compute scaling has revolutionized reasoning capabilities of modern LLMs by leveraging additional inference-time compute for candidate solution refinement. These methods typically leverage foundation models as verification modules in a zero-shot manner to synthesize improved candidate solutions. In this work, we hypothesize that generative policies can similarly benefit from additional inference-time compute that employs zero-shot VLM-based verifiers. A systematic analysis of improving policy performance through the generation-verification framework remains relatively underexplored in the current literature. To this end, we introduce EVE - a modular, generator-verifier interaction framework - that boosts the performance of pretrained generative policies at test time, with no additional training. EVE wraps a frozen base policy with multiple zero-shot, VLM-based verifier agents. Each verifier proposes action refinements to the base policy candidate actions, while an action incorporator fuses the aggregated verifier output into the base policy action prediction to produce the final executed action. We study design choices for generator-verifier information interfacing across a system of verifiers with distinct capabilities. Across a diverse suite of manipulation tasks, EVE consistently improves task success rates without any additional policy training. Through extensive ablations, we isolate the contribution of verifier capabilities and action incorporator strategies, offering practical guidelines to build scalable, modular generator-verifier systems for embodied control.
Let's Think in Two Steps: Mitigating Agreement Bias in MLLMs with Self-Grounded Verification
Jul 15, 2025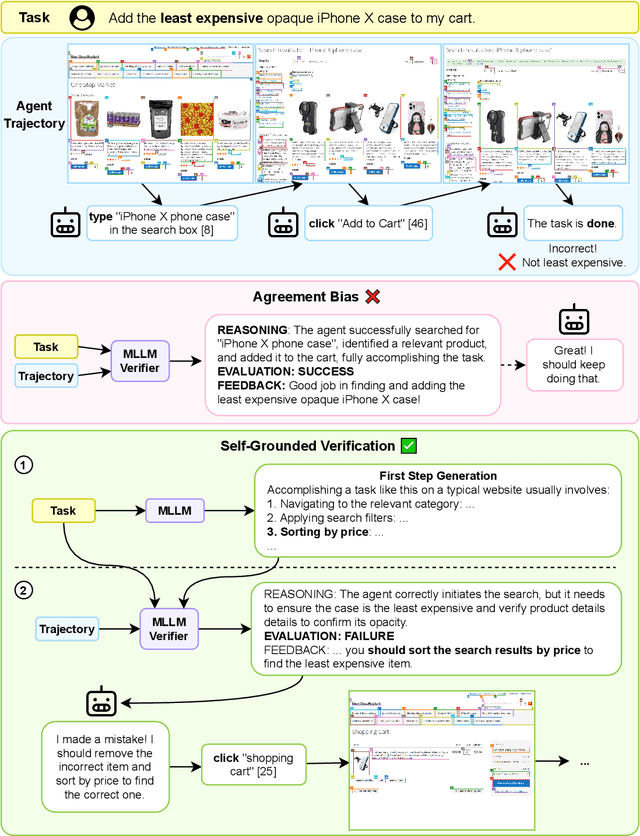
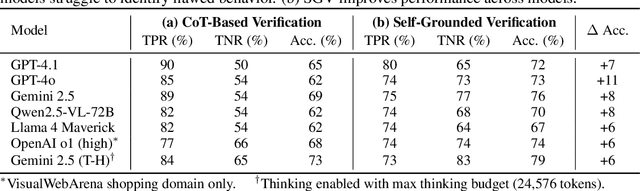
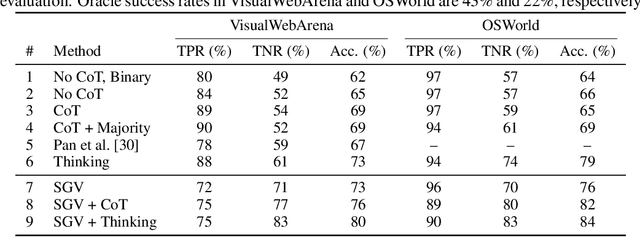
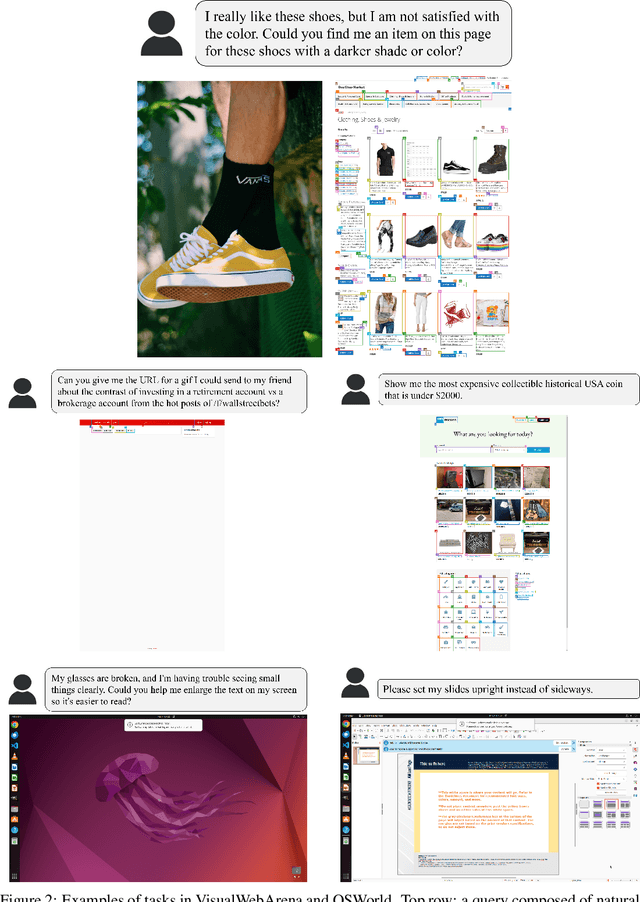
Verifiers -- functions assigning rewards to agent behavior -- have been key for AI progress in domains like math and board games. However, extending these gains to domains without clear-cut success criteria (e.g.,computer use) remains a challenge: while humans can recognize suitable outcomes, translating this intuition into scalable rules is non-trivial. Multimodal Large Language Models(MLLMs) emerge as a promising solution, given their world knowledge, human-preference alignment, and reasoning skills. We evaluate MLLMs as verifiers of agent trajectories across web navigation, computer use, and robotic manipulation, and identify a critical limitation: agreement bias, a strong tendency for MLLMs to favor information in their context window, often generating chains of thought to rationalize flawed behavior. This bias is pervasive across models, resilient to test-time scaling, and can impact several methods using MLLMs as evaluators (e.g.,data filtering). Notably, it occurs despite MLLMs showing strong, human-aligned priors on desired behavior. To address this, we propose Self-Grounded Verification (SGV), a lightweight method that enables more effective use of MLLMs' knowledge and reasoning by harnessing their own sampling mechanisms via unconditional and conditional generation. SGV operates in two steps: first, the MLLM is elicited to retrieve broad priors about task completion, independent of the data under evaluation. Then, conditioned on self-generated priors, it reasons over and evaluates a candidate trajectory. Enhanced with SGV, MLLM verifiers show gains of up to 20 points in accuracy and failure detection rates, and can perform real-time supervision of heterogeneous agents, boosting task completion of a GUI specialist in OSWorld, a diffusion policy in robomimic, and a ReAct agent in VisualWebArena -- setting a new state of the art on the benchmark, surpassing the previous best by 48%.
EscherNet++: Simultaneous Amodal Completion and Scalable View Synthesis through Masked Fine-Tuning and Enhanced Feed-Forward 3D Reconstruction
Jul 10, 2025We propose EscherNet++, a masked fine-tuned diffusion model that can synthesize novel views of objects in a zero-shot manner with amodal completion ability. Existing approaches utilize multiple stages and complex pipelines to first hallucinate missing parts of the image and then perform novel view synthesis, which fail to consider cross-view dependencies and require redundant storage and computing for separate stages. Instead, we apply masked fine-tuning including input-level and feature-level masking to enable an end-to-end model with the improved ability to synthesize novel views and conduct amodal completion. In addition, we empirically integrate our model with other feed-forward image-to-mesh models without extra training and achieve competitive results with reconstruction time decreased by 95%, thanks to its ability to synthesize arbitrary query views. Our method's scalable nature further enhances fast 3D reconstruction. Despite fine-tuning on a smaller dataset and batch size, our method achieves state-of-the-art results, improving PSNR by 3.9 and Volume IoU by 0.28 on occluded tasks in 10-input settings, while also generalizing to real-world occluded reconstruction.