 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMimicking or Reasoning: Rethinking Multi-Modal In-Context Learning in Vision-Language Models
Jun 09, 2025

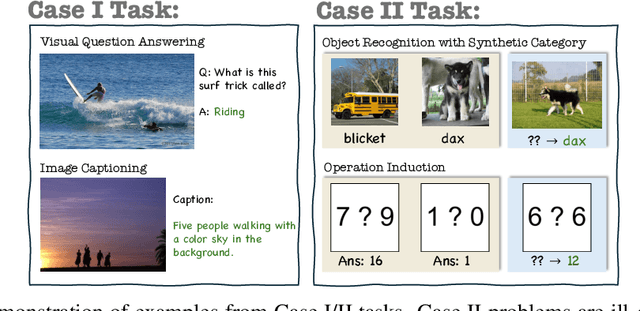
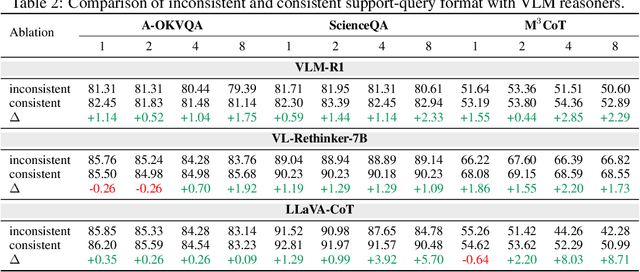
Vision-language models (VLMs) are widely assumed to exhibit in-context learning (ICL), a property similar to that of their language-only counterparts. While recent work suggests VLMs can perform multimodal ICL (MM-ICL), studies show they often rely on shallow heuristics -- such as copying or majority voting -- rather than true task understanding. We revisit this assumption by evaluating VLMs under distribution shifts, where support examples come from a dataset different from the query. Surprisingly, performance often degrades with more demonstrations, and models tend to copy answers rather than learn from them. To investigate further, we propose a new MM-ICL with Reasoning pipeline that augments each demonstration with a generated rationale alongside the answer. We conduct extensive and comprehensive experiments on both perception- and reasoning-required datasets with open-source VLMs ranging from 3B to 72B and proprietary models such as Gemini 2.0. We conduct controlled studies varying shot count, retrieval method, rationale quality, and distribution. Our results show limited performance sensitivity across these factors, suggesting that current VLMs do not effectively utilize demonstration-level information as intended in MM-ICL.
Your contrastive learning problem is secretly a distribution alignment problem
Feb 27, 2025Despite the success of contrastive learning (CL) in vision and language, its theoretical foundations and mechanisms for building representations remain poorly understood. In this work, we build connections between noise contrastive estimation losses widely used in CL and distribution alignment with entropic optimal transport (OT). This connection allows us to develop a family of different losses and multistep iterative variants for existing CL methods. Intuitively, by using more information from the distribution of latents, our approach allows a more distribution-aware manipulation of the relationships within augmented sample sets. We provide theoretical insights and experimental evidence demonstrating the benefits of our approach for {\em generalized contrastive alignment}. Through this framework, it is possible to leverage tools in OT to build unbalanced losses to handle noisy views and customize the representation space by changing the constraints on alignment. By reframing contrastive learning as an alignment problem and leveraging existing optimization tools for OT, our work provides new insights and connections between different self-supervised learning models in addition to new tools that can be more easily adapted to incorporate domain knowledge into learning.
* 10 pages, 5 figures, NeurIPS 2024 submission, includes supplementary material
Generalizable autoregressive modeling of time series through functional narratives
Oct 10, 2024



Time series data are inherently functions of time, yet current transformers often learn time series by modeling them as mere concatenations of time periods, overlooking their functional properties. In this work, we propose a novel objective for transformers that learn time series by re-interpreting them as temporal functions. We build an alternative sequence of time series by constructing degradation operators of different intensity in the functional space, creating augmented variants of the original sample that are abstracted or simplified to different degrees. Based on the new set of generated sequence, we train an autoregressive transformer that progressively recovers the original sample from the most simplified variant. Analogous to the next word prediction task in languages that learns narratives by connecting different words, our autoregressive transformer aims to learn the Narratives of Time Series (NoTS) by connecting different functions in time. Theoretically, we justify the construction of the alternative sequence through its advantages in approximating functions. When learning time series data with transformers, constructing sequences of temporal functions allows for a broader class of approximable functions (e.g., differentiation) compared to sequences of time periods, leading to a 26\% performance improvement in synthetic feature regression experiments. Experimentally, we validate NoTS in 3 different tasks across 22 real-world datasets, where we show that NoTS significantly outperforms other pre-training methods by up to 6\%. Additionally, combining NoTS on top of existing transformer architectures can consistently boost the performance. Our results demonstrate the potential of NoTS as a general-purpose dynamic learner, offering a viable alternative for developing foundation models for time series analysis.
LatentDR: Improving Model Generalization Through Sample-Aware Latent Degradation and Restoration
Aug 28, 2023Despite significant advances in deep learning, models often struggle to generalize well to new, unseen domains, especially when training data is limited. To address this challenge, we propose a novel approach for distribution-aware latent augmentation that leverages the relationships across samples to guide the augmentation procedure. Our approach first degrades the samples stochastically in the latent space, mapping them to augmented labels, and then restores the samples from their corrupted versions during training. This process confuses the classifier in the degradation step and restores the overall class distribution of the original samples, promoting diverse intra-class/cross-domain variability. We extensively evaluate our approach on a diverse set of datasets and tasks, including domain generalization benchmarks and medical imaging datasets with strong domain shift, where we show our approach achieves significant improvements over existing methods for latent space augmentation. We further show that our method can be flexibly adapted to long-tail recognition tasks, demonstrating its versatility in building more generalizable models. Code is available at https://github.com/nerdslab/LatentDR.
MTNeuro: A Benchmark for Evaluating Representations of Brain Structure Across Multiple Levels of Abstraction
Jan 01, 2023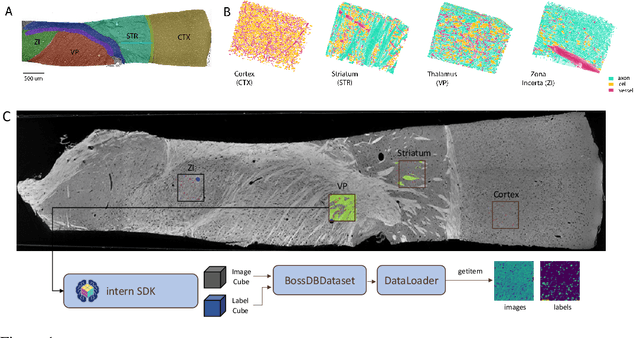
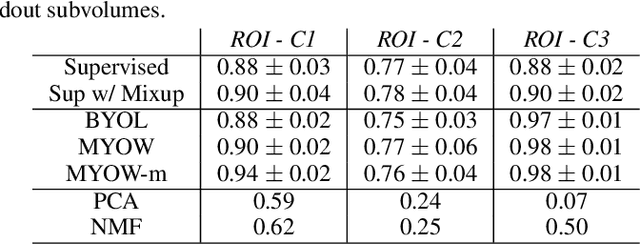

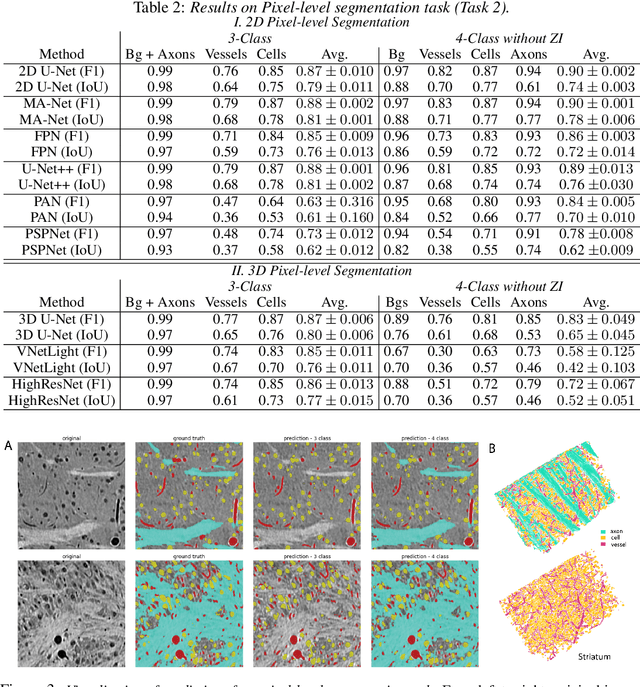
There are multiple scales of abstraction from which we can describe the same image, depending on whether we are focusing on fine-grained details or a more global attribute of the image. In brain mapping, learning to automatically parse images to build representations of both small-scale features (e.g., the presence of cells or blood vessels) and global properties of an image (e.g., which brain region the image comes from) is a crucial and open challenge. However, most existing datasets and benchmarks for neuroanatomy consider only a single downstream task at a time. To bridge this gap, we introduce a new dataset, annotations, and multiple downstream tasks that provide diverse ways to readout information about brain structure and architecture from the same image. Our multi-task neuroimaging benchmark (MTNeuro) is built on volumetric, micrometer-resolution X-ray microtomography images spanning a large thalamocortical section of mouse brain, encompassing multiple cortical and subcortical regions. We generated a number of different prediction challenges and evaluated several supervised and self-supervised models for brain-region prediction and pixel-level semantic segmentation of microstructures. Our experiments not only highlight the rich heterogeneity of this dataset, but also provide insights into how self-supervised approaches can be used to learn representations that capture multiple attributes of a single image and perform well on a variety of downstream tasks. Datasets, code, and pre-trained baseline models are provided at: https://mtneuro.github.io/ .
Seeing the forest and the tree: Building representations of both individual and collective dynamics with transformers
Jun 10, 2022Complex time-varying systems are often studied by abstracting away from the dynamics of individual components to build a model of the population-level dynamics from the start. However, when building a population-level description, it can be easy to lose sight of each individual and how each contributes to the larger picture. In this paper, we present a novel transformer architecture for learning from time-varying data that builds descriptions of both the individual as well as the collective population dynamics. Rather than combining all of our data into our model at the onset, we develop a separable architecture that operates on individual time-series first before passing them forward; this induces a permutation-invariance property and can be used to transfer across systems of different size and order. After demonstrating that our model can be applied to successfully recover complex interactions and dynamics in many-body systems, we apply our approach to populations of neurons in the nervous system. On neural activity datasets, we show that our multi-scale transformer not only yields robust decoding performance, but also provides impressive performance in transfer. Our results show that it is possible to learn from neurons in one animal's brain and transfer the model on neurons in a different animal's brain, with interpretable neuron correspondence across sets and animals. This finding opens up a new path to decode from and represent large collections of neurons.
Deformation Flow Based Two-Stream Network for Lip Reading
Mar 13, 2020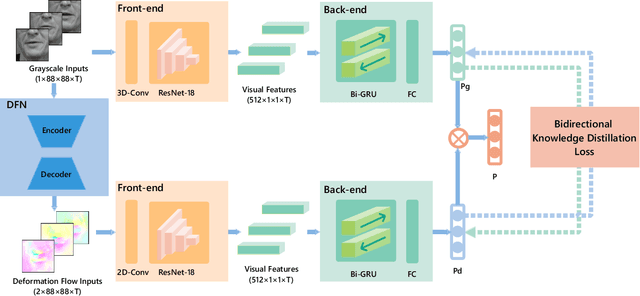
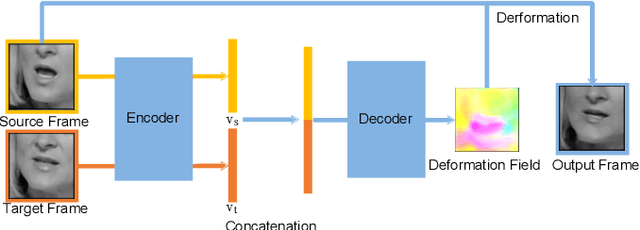

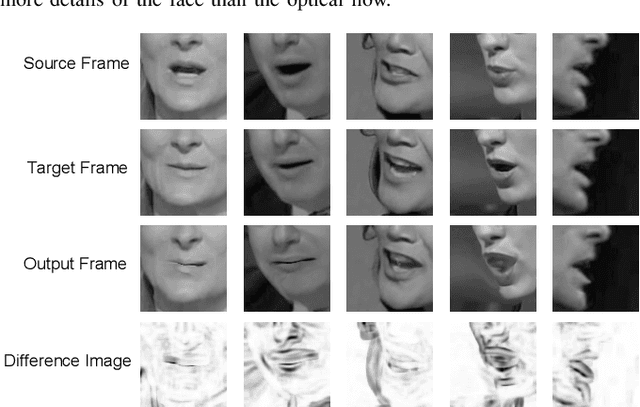
Lip reading is the task of recognizing the speech content by analyzing movements in the lip region when people are speaking. Observing on the continuity in adjacent frames in the speaking process, and the consistency of the motion patterns among different speakers when they pronounce the same phoneme, we model the lip movements in the speaking process as a sequence of apparent deformations in the lip region. Specifically, we introduce a Deformation Flow Network (DFN) to learn the deformation flow between adjacent frames, which directly captures the motion information within the lip region. The learned deformation flow is then combined with the original grayscale frames with a two-stream network to perform lip reading. Different from previous two-stream networks, we make the two streams learn from each other in the learning process by introducing a bidirectional knowledge distillation loss to train the two branches jointly. Owing to the complementary cues provided by different branches, the two-stream network shows a substantial improvement over using either single branch. A thorough experimental evaluation on two large-scale lip reading benchmarks is presented with detailed analysis. The results accord with our motivation, and show that our method achieves state-of-the-art or comparable performance on these two challenging datasets.
Can We Read Speech Beyond the Lips? Rethinking RoI Selection for Deep Visual Speech Recognition
Mar 09, 2020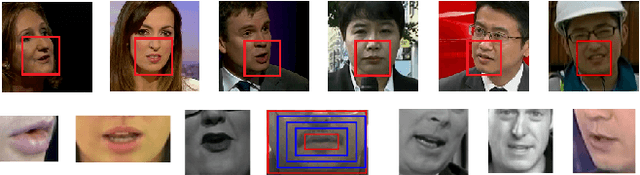

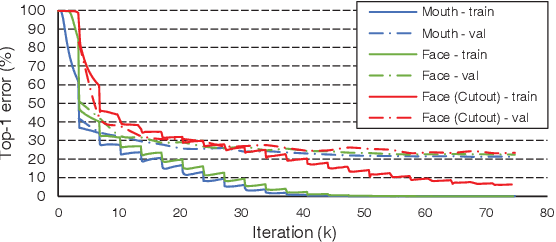
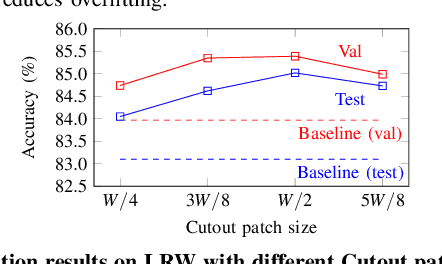
Recent advances in deep learning have heightened interest among researchers in the field of visual speech recognition (VSR). Currently, most existing methods equate VSR with automatic lip reading, which attempts to recognise speech by analysing lip motion. However, human experience and psychological studies suggest that we do not always fix our gaze at each other's lips during a face-to-face conversation, but rather scan the whole face repetitively. This inspires us to revisit a fundamental yet somehow overlooked problem: can VSR models benefit from reading extraoral facial regions, i.e. beyond the lips? In this paper, we perform a comprehensive study to evaluate the effects of different facial regions with state-of-the-art VSR models, including the mouth, the whole face, the upper face, and even the cheeks. Experiments are conducted on both word-level and sentence-level benchmarks with different characteristics. We find that despite the complex variations of the data, incorporating information from extraoral facial regions, even the upper face, consistently benefits VSR performance. Furthermore, we introduce a simple yet effective method based on Cutout to learn more discriminative features for face-based VSR, hoping to maximise the utility of information encoded in different facial regions. Our experiments show obvious improvements over existing state-of-the-art methods that use only the lip region as inputs, a result we believe would probably provide the VSR community with some new and exciting insights.
LRW-1000: A Naturally-Distributed Large-Scale Benchmark for Lip Reading in the Wild
Oct 29, 2018
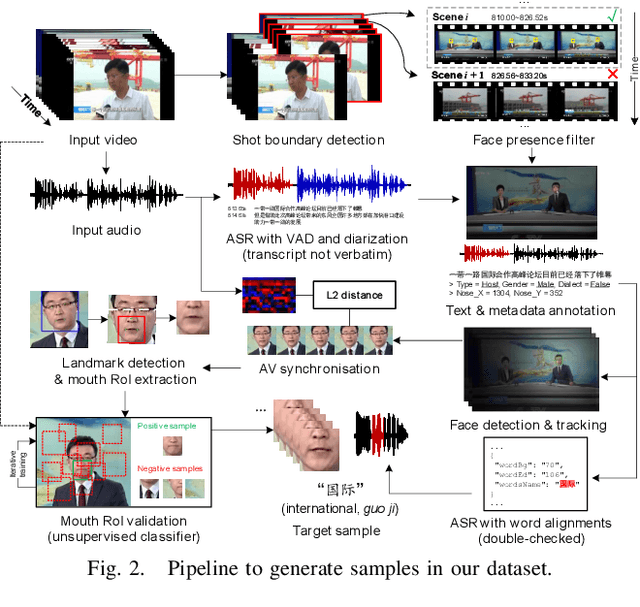
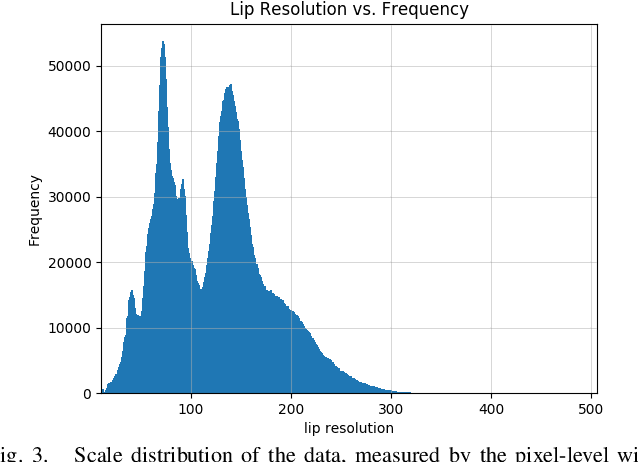
Large-scale datasets have successively proven their fundamental importance in several research fields, especially for early progress in some emerging topics. In this paper, we focus on the problem of visual speech recognition, also known as lipreading, which has received an increasing interest in recent years. We present a naturally-distributed large-scale benchmark for lip reading in the wild, named LRW-1000, which contains 1000 classes with about 745,187 samples from more than 2000 individual speakers. Each class corresponds to the syllables of a Mandarin word which is composed of one or several Chinese characters. To the best of our knowledge, it is the largest word-level lipreading dataset and also the only public large-scale Mandarin lipreading dataset. This dataset aims at covering a "natural" variability over different speech modes and imaging conditions to incorporate challenges encountered in practical applications. This benchmark shows a large variation over several aspects, including the number of samples in each class, resolution of videos, lighting conditions, and speakers' attributes such as pose, age, gender, and make-up. Besides a detailed description of the dataset and its collection pipeline, we evaluate the popular lipreading methods and perform a thorough analysis of the results from several aspects. The results demonstrate the consistency and challenges of our dataset, which may open up some new promising directions for future work. The dataset and corresponding codes will be public for academic research use.
3D Feature Pyramid Attention Module for Robust Visual Speech Recognition
Oct 17, 2018
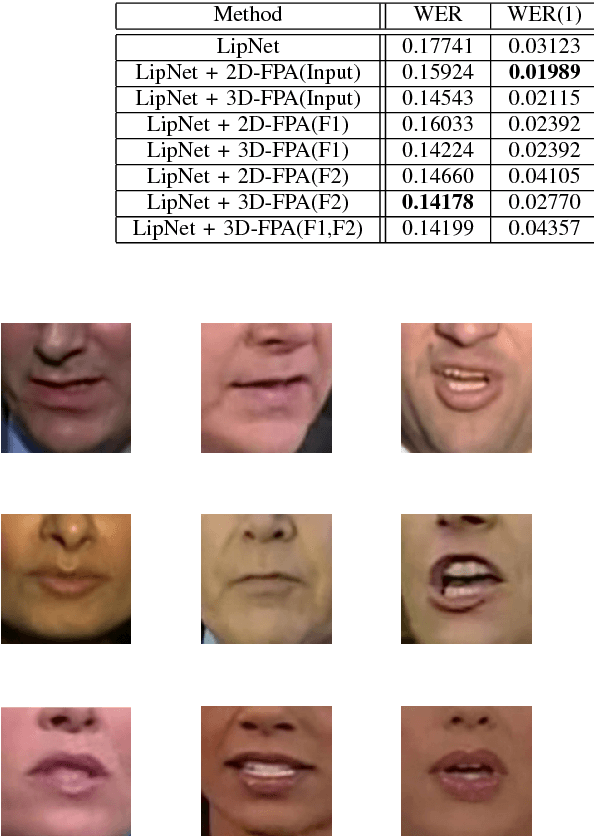


Visual speech recognition is the task to decode the speech content from a video based on visual information, especially the movements of lips. It is also referenced as lipreading. Motivated by two problems existing in lipreading, words with similar pronunciation and the variation of word duration, we propose a novel 3D Feature Pyramid Attention (3D-FPA) module to jointly improve the representation power of features in both the spatial and temporal domains. Specifically, the input features are downsampled for 3 times in both the spatial and temporal dimensions to construct spatiotemporal feature pyramids. Then high-level features are upsampled and combined with low-level features, finally generating a pixel-level soft attention mask to be multiplied with the input features.It enhances the discriminative power of features and exploits the temporal multi-scale information while decoding the visual speeches. Also, this module provides a new method to construct and utilize temporal pyramid structures in video analysis tasks. The field of temporal featrue pyramids are still under exploring compared to the plentiful works on spatial feature pyramids for image analysis tasks. To validate the effectiveness and adaptability of our proposed module, we embed the module in a sentence-level lipreading model, LipNet, with the result of 3.6% absolute decrease in word error rate, and a word-level model, with the result of 1.4% absolute improvement in accuracy.