 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld In Your Hands: A Large-Scale and Open-source Ecosystem for Learning Human-centric Manipulation in the Wild
Dec 30, 2025Large-scale pre-training is fundamental for generalization in language and vision models, but data for dexterous hand manipulation remains limited in scale and diversity, hindering policy generalization. Limited scenario diversity, misaligned modalities, and insufficient benchmarking constrain current human manipulation datasets. To address these gaps, we introduce World In Your Hands (WiYH), a large-scale open-source ecosystem for human-centric manipulation learning. WiYH includes (1) the Oracle Suite, a wearable data collection kit with an auto-labeling pipeline for accurate motion capture; (2) the WiYH Dataset, featuring over 1,000 hours of multi-modal manipulation data across hundreds of skills in diverse real-world scenarios; and (3) extensive annotations and benchmarks supporting tasks from perception to action. Furthermore, experiments based on the WiYH ecosystem show that integrating WiYH's human-centric data significantly enhances the generalization and robustness of dexterous hand policies in tabletop manipulation tasks. We believe that World In Your Hands will bring new insights into human-centric data collection and policy learning to the community.
GreedyNAS: Towards Fast One-Shot NAS with Greedy Supernet
Mar 25, 2020
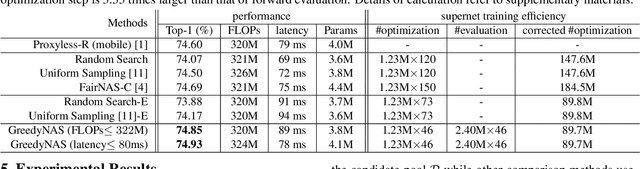
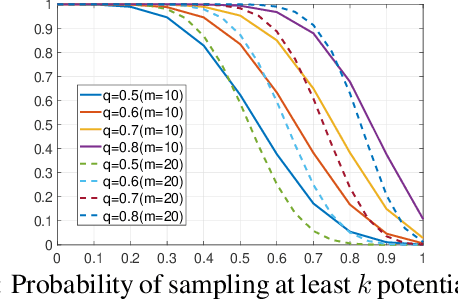

Training a supernet matters for one-shot neural architecture search (NAS) methods since it serves as a basic performance estimator for different architectures (paths). Current methods mainly hold the assumption that a supernet should give a reasonable ranking over all paths. They thus treat all paths equally, and spare much effort to train paths. However, it is harsh for a single supernet to evaluate accurately on such a huge-scale search space (e.g., $7^{21}$). In this paper, instead of covering all paths, we ease the burden of supernet by encouraging it to focus more on evaluation of those potentially-good ones, which are identified using a surrogate portion of validation data. Concretely, during training, we propose a multi-path sampling strategy with rejection, and greedily filter the weak paths. The training efficiency is thus boosted since the training space has been greedily shrunk from all paths to those potentially-good ones. Moreover, we further adopt an exploration and exploitation policy by introducing an empirical candidate path pool. Our proposed method GreedyNAS is easy-to-follow, and experimental results on ImageNet dataset indicate that it can achieve better Top-1 accuracy under same search space and FLOPs or latency level, but with only $\sim$60\% of supernet training cost. By searching on a larger space, our GreedyNAS can also obtain new state-of-the-art architectures.
LRW-1000: A Naturally-Distributed Large-Scale Benchmark for Lip Reading in the Wild
Oct 29, 2018
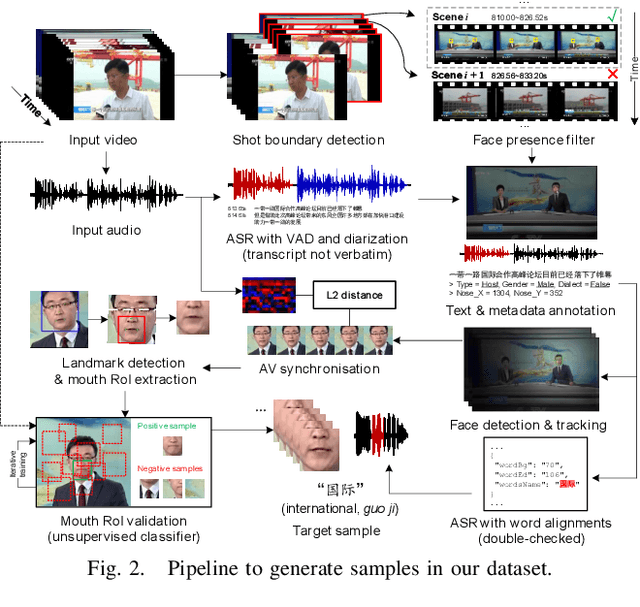
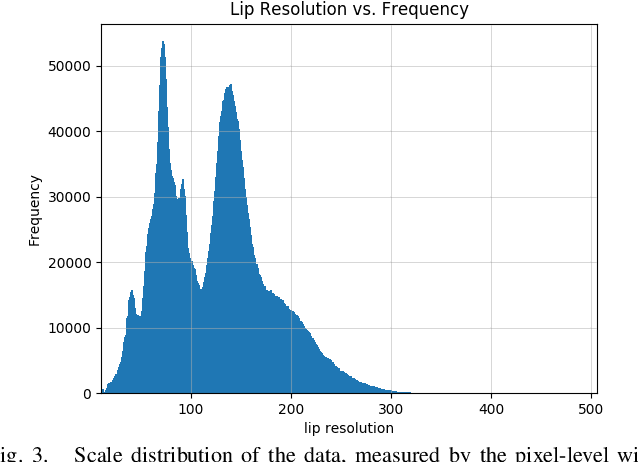
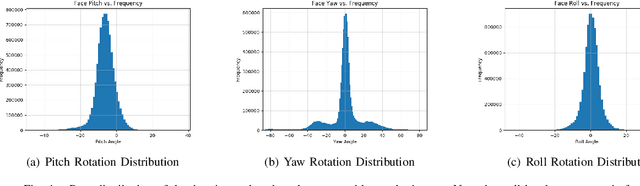
Large-scale datasets have successively proven their fundamental importance in several research fields, especially for early progress in some emerging topics. In this paper, we focus on the problem of visual speech recognition, also known as lipreading, which has received an increasing interest in recent years. We present a naturally-distributed large-scale benchmark for lip reading in the wild, named LRW-1000, which contains 1000 classes with about 745,187 samples from more than 2000 individual speakers. Each class corresponds to the syllables of a Mandarin word which is composed of one or several Chinese characters. To the best of our knowledge, it is the largest word-level lipreading dataset and also the only public large-scale Mandarin lipreading dataset. This dataset aims at covering a "natural" variability over different speech modes and imaging conditions to incorporate challenges encountered in practical applications. This benchmark shows a large variation over several aspects, including the number of samples in each class, resolution of videos, lighting conditions, and speakers' attributes such as pose, age, gender, and make-up. Besides a detailed description of the dataset and its collection pipeline, we evaluate the popular lipreading methods and perform a thorough analysis of the results from several aspects. The results demonstrate the consistency and challenges of our dataset, which may open up some new promising directions for future work. The dataset and corresponding codes will be public for academic research use.