 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Model-Agnostic Continual Learning for Next POI Recommendation
Nov 12, 2025Next point-of-interest (POI) recommendation improves personalized location-based services by predicting users' next destinations based on their historical check-ins. However, most existing methods rely on static datasets and fixed models, limiting their ability to adapt to changes in user behavior over time. To address this limitation, we explore a novel task termed continual next POI recommendation, where models dynamically adapt to evolving user interests through continual updates. This task is particularly challenging, as it requires capturing shifting user behaviors while retaining previously learned knowledge. Moreover, it is essential to ensure efficiency in update time and memory usage for real-world deployment. To this end, we propose GIRAM (Generative Key-based Interest Retrieval and Adaptive Modeling), an efficient, model-agnostic framework that integrates context-aware sustained interests with recent interests. GIRAM comprises four components: (1) an interest memory to preserve historical preferences; (2) a context-aware key encoding module for unified interest key representation; (3) a generative key-based retrieval module to identify diverse and relevant sustained interests; and (4) an adaptive interest update and fusion module to update the interest memory and balance sustained and recent interests. In particular, GIRAM can be seamlessly integrated with existing next POI recommendation models. Experiments on three real-world datasets demonstrate that GIRAM consistently outperforms state-of-the-art methods while maintaining high efficiency in both update time and memory consumption.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Empowering Edge Intelligence: A Comprehensive Survey on On-Device AI Models
Mar 08, 2025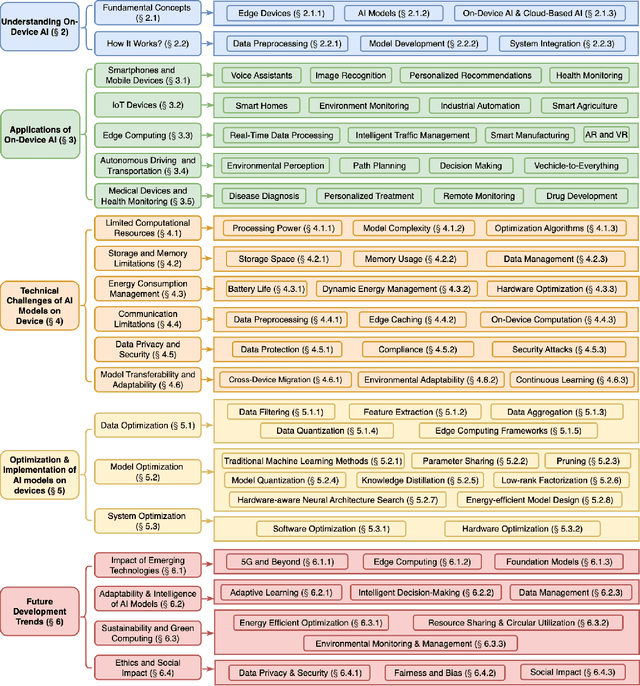



The rapid advancement of artificial intelligence (AI) technologies has led to an increasing deployment of AI models on edge and terminal devices, driven by the proliferation of the Internet of Things (IoT) and the need for real-time data processing. This survey comprehensively explores the current state, technical challenges, and future trends of on-device AI models. We define on-device AI models as those designed to perform local data processing and inference, emphasizing their characteristics such as real-time performance, resource constraints, and enhanced data privacy. The survey is structured around key themes, including the fundamental concepts of AI models, application scenarios across various domains, and the technical challenges faced in edge environments. We also discuss optimization and implementation strategies, such as data preprocessing, model compression, and hardware acceleration, which are essential for effective deployment. Furthermore, we examine the impact of emerging technologies, including edge computing and foundation models, on the evolution of on-device AI models. By providing a structured overview of the challenges, solutions, and future directions, this survey aims to facilitate further research and application of on-device AI, ultimately contributing to the advancement of intelligent systems in everyday life.
LINKED: Eliciting, Filtering and Integrating Knowledge in Large Language Model for Commonsense Reasoning
Oct 12, 2024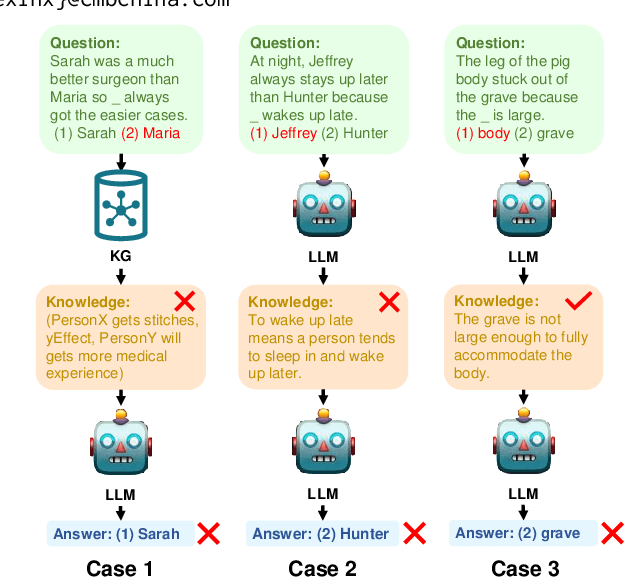

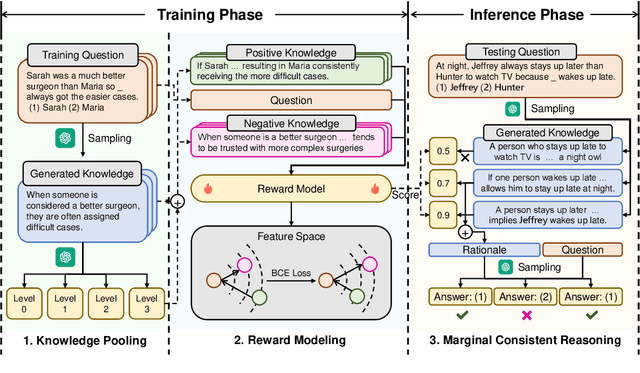

Large language models (LLMs) sometimes demonstrate poor performance on knowledge-intensive tasks, commonsense reasoning is one of them. Researchers typically address these issues by retrieving related knowledge from knowledge graphs or employing self-enhancement methods to elicit knowledge in LLMs. However, noisy knowledge and invalid reasoning issues hamper their ability to answer questions accurately. To this end, we propose a novel method named eliciting, filtering and integrating knowledge in large language model (LINKED). In it, we design a reward model to filter out the noisy knowledge and take the marginal consistent reasoning module to reduce invalid reasoning. With our comprehensive experiments on two complex commonsense reasoning benchmarks, our method outperforms SOTA baselines (up to 9.0% improvement of accuracy). Besides, to measure the positive and negative impact of the injected knowledge, we propose a new metric called effectiveness-preservation score for the knowledge enhancement works. Finally, through extensive experiments, we conduct an in-depth analysis and find many meaningful conclusions about LLMs in commonsense reasoning tasks.
Extracting polygonal footprints in off-nadir images with Segment Anything Model
Aug 16, 2024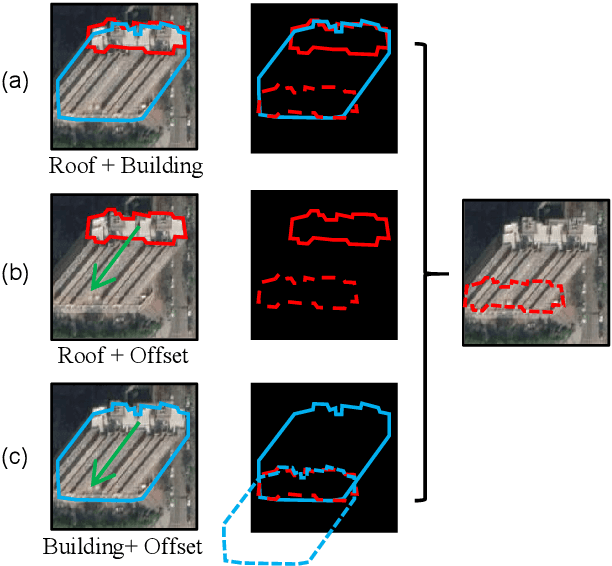
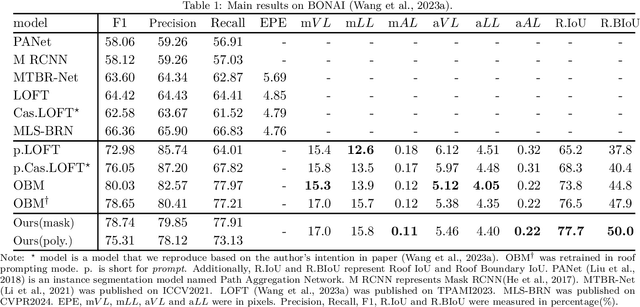
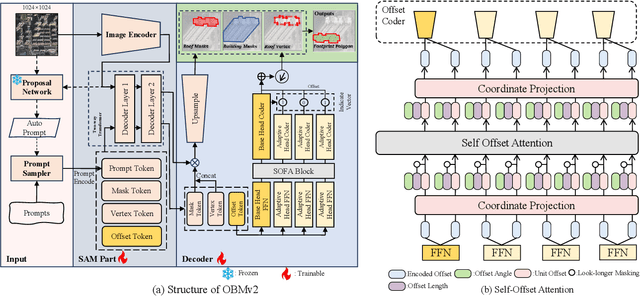
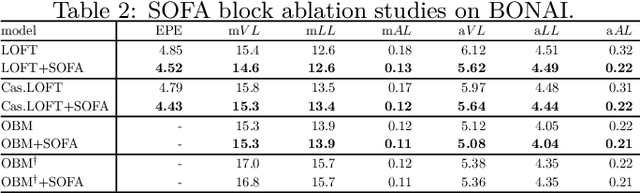
Building Footprint Extraction (BFE) in off-nadir aerial images often relies on roof segmentation and roof-to-footprint offset prediction, then drugging roof-to-footprint via the offset. However, the results from this multi-stage inference are not applicable in data production, because of the low quality of masks given by prediction. To solve this problem, we proposed OBMv2 in this paper, which supports both end-to-end and promptable polygonal footprint prediction. Different from OBM, OBMv2 using a newly proposed Self Offset Attention (SOFA) to bridge the performance gap on bungalow and skyscraper, which realized a real end-to-end footprint polygon prediction without postprocessing. %, such as Non-Maximum Suppression (NMS) and Distance NMS (DNMS). % To fully use information contained in roof masks, building masks and offsets, we proposed a Multi-level Information SyStem (MISS) for footprint prediction, with which OBMv2 can predict footprints even with insufficient predictions. Additionally, to squeeze information from the same model, we were inspired by Retrieval-Augmented Generation (RAG) in Nature Language Processing and proposed "RAG in BFE" problem. To verify the effectiveness of the proposed method, experiments were conducted on open datasets BONAI and OmniCity-view3. A generalization test was also conducted on Huizhou test set. The code will be available at \url{https://github.com/likaiucas/OBM}.
Multi-modal Crowd Counting via Modal Emulation
Jul 28, 2024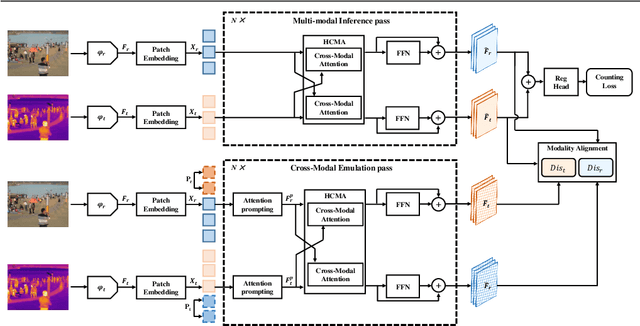
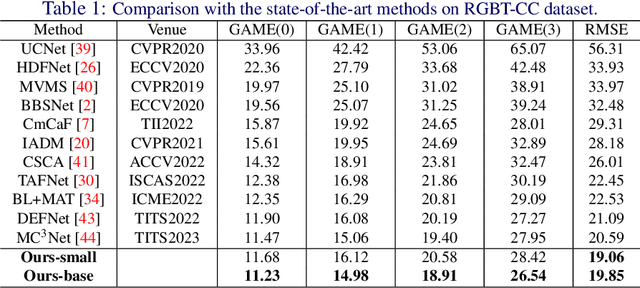
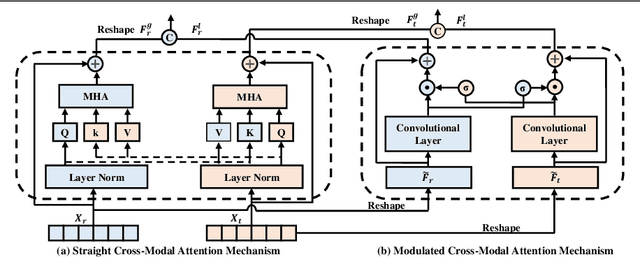
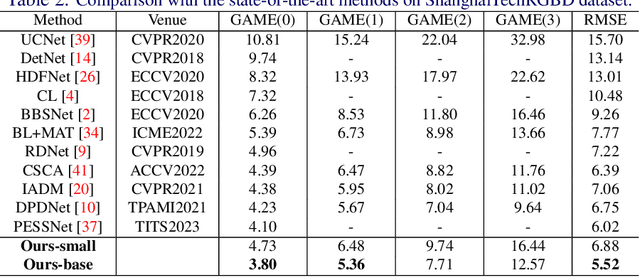
Multi-modal crowd counting is a crucial task that uses multi-modal cues to estimate the number of people in crowded scenes. To overcome the gap between different modalities, we propose a modal emulation-based two-pass multi-modal crowd-counting framework that enables efficient modal emulation, alignment, and fusion. The framework consists of two key components: a \emph{multi-modal inference} pass and a \emph{cross-modal emulation} pass. The former utilizes a hybrid cross-modal attention module to extract global and local information and achieve efficient multi-modal fusion. The latter uses attention prompting to coordinate different modalities and enhance multi-modal alignment. We also introduce a modality alignment module that uses an efficient modal consistency loss to align the outputs of the two passes and bridge the semantic gap between modalities. Extensive experiments on both RGB-Thermal and RGB-Depth counting datasets demonstrate its superior performance compared to previous methods. Code available at https://github.com/Mr-Monday/Multi-modal-Crowd-Counting-via-Modal-Emulation.
Multi-modal Crowd Counting via a Broker Modality
Jul 10, 2024Multi-modal crowd counting involves estimating crowd density from both visual and thermal/depth images. This task is challenging due to the significant gap between these distinct modalities. In this paper, we propose a novel approach by introducing an auxiliary broker modality and on this basis frame the task as a triple-modal learning problem. We devise a fusion-based method to generate this broker modality, leveraging a non-diffusion, lightweight counterpart of modern denoising diffusion-based fusion models. Additionally, we identify and address the ghosting effect caused by direct cross-modal image fusion in multi-modal crowd counting. Through extensive experimental evaluations on popular multi-modal crowd-counting datasets, we demonstrate the effectiveness of our method, which introduces only 4 million additional parameters, yet achieves promising results. The code is available at https://github.com/HenryCilence/Broker-Modality-Crowd-Counting.
RWKU: Benchmarking Real-World Knowledge Unlearning for Large Language Models
Jun 16, 2024Large language models (LLMs) inevitably memorize sensitive, copyrighted, and harmful knowledge from the training corpus; therefore, it is crucial to erase this knowledge from the models. Machine unlearning is a promising solution for efficiently removing specific knowledge by post hoc modifying models. In this paper, we propose a Real-World Knowledge Unlearning benchmark (RWKU) for LLM unlearning. RWKU is designed based on the following three key factors: (1) For the task setting, we consider a more practical and challenging unlearning setting, where neither the forget corpus nor the retain corpus is accessible. (2) For the knowledge source, we choose 200 real-world famous people as the unlearning targets and show that such popular knowledge is widely present in various LLMs. (3) For the evaluation framework, we design the forget set and the retain set to evaluate the model's capabilities across various real-world applications. Regarding the forget set, we provide four four membership inference attack (MIA) methods and nine kinds of adversarial attack probes to rigorously test unlearning efficacy. Regarding the retain set, we assess locality and utility in terms of neighbor perturbation, general ability, reasoning ability, truthfulness, factuality, and fluency. We conduct extensive experiments across two unlearning scenarios, two models and six baseline methods and obtain some meaningful findings. We release our benchmark and code publicly at http://rwku-bench.github.io for future work.
Brainstorming Brings Power to Large Language Models of Knowledge Reasoning
Jun 02, 2024



Large Language Models (LLMs) have demonstrated amazing capabilities in language generation, text comprehension, and knowledge reasoning. While a single powerful model can already handle multiple tasks, relying on a single perspective can lead to biased and unstable results. Recent studies have further improved the model's reasoning ability on a wide range of tasks by introducing multi-model collaboration. However, models with different capabilities may produce conflicting answers on the same problem, and how to reasonably obtain the correct answer from multiple candidate models has become a challenging problem. In this paper, we propose the multi-model brainstorming based on prompt. It incorporates different models into a group for brainstorming, and after multiple rounds of reasoning elaboration and re-inference, a consensus answer is reached within the group. We conducted experiments on three different types of datasets, and demonstrate that the brainstorming can significantly improve the effectiveness in logical reasoning and fact extraction. Furthermore, we find that two small-parameter models can achieve accuracy approximating that of larger-parameter models through brainstorming, which provides a new solution for distributed deployment of LLMs.
Adaptive Federated Learning Over the Air
Mar 11, 2024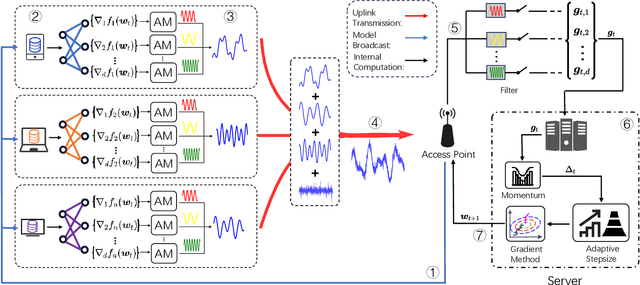
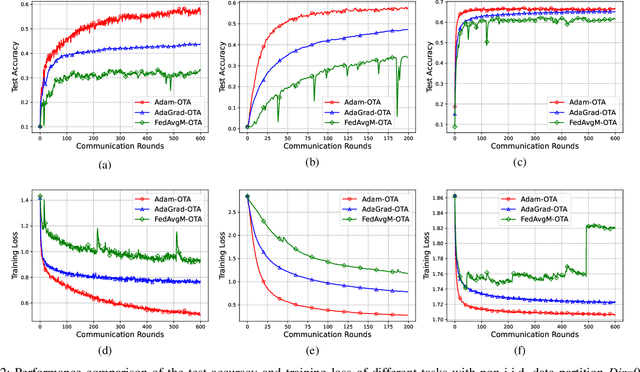
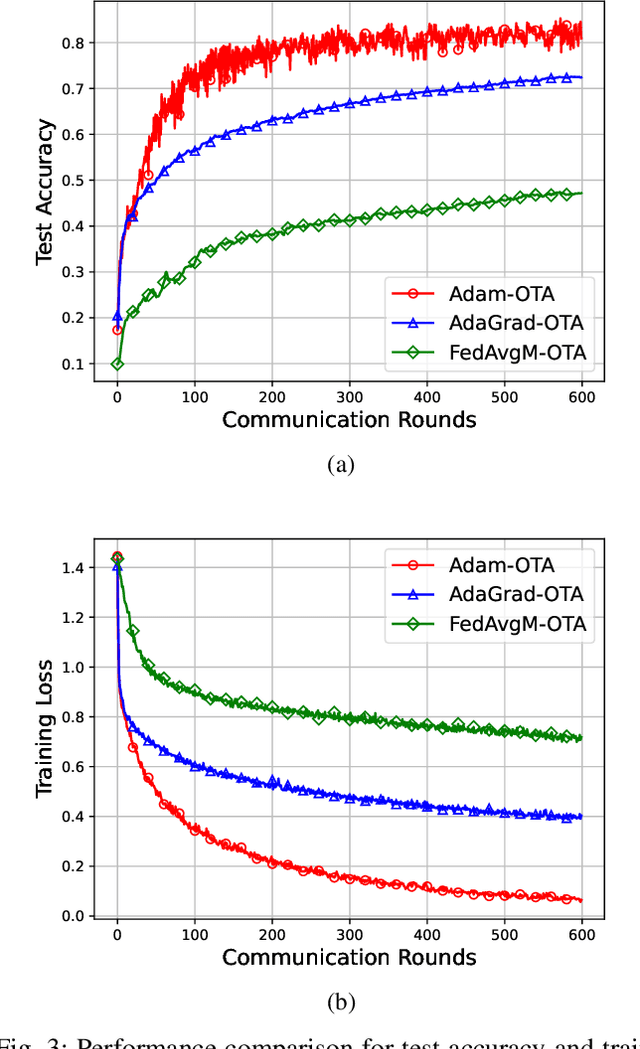
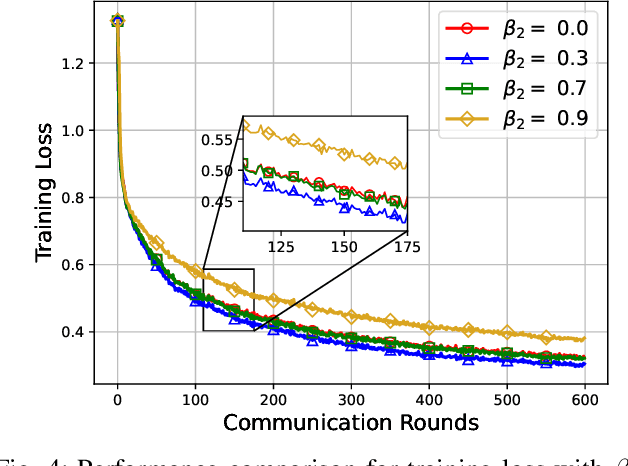
We propose a federated version of adaptive gradient methods, particularly AdaGrad and Adam, within the framework of over-the-air model training. This approach capitalizes on the inherent superposition property of wireless channels, facilitating fast and scalable parameter aggregation. Meanwhile, it enhances the robustness of the model training process by dynamically adjusting the stepsize in accordance with the global gradient update. We derive the convergence rate of the training algorithms, encompassing the effects of channel fading and interference, for a broad spectrum of nonconvex loss functions. Our analysis shows that the AdaGrad-based algorithm converges to a stationary point at the rate of $\mathcal{O}( \ln{(T)} /{ T^{ 1 - \frac{1}{\alpha} } } )$, where $\alpha$ represents the tail index of the electromagnetic interference. This result indicates that the level of heavy-tailedness in interference distribution plays a crucial role in the training efficiency: the heavier the tail, the slower the algorithm converges. In contrast, an Adam-like algorithm converges at the $\mathcal{O}( 1/T )$ rate, demonstrating its advantage in expediting the model training process. We conduct extensive experiments that corroborate our theoretical findings and affirm the practical efficacy of our proposed federated adaptive gradient methods.