 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Manifold Rectification for Imbalanced Learning
Feb 13, 2026Imbalanced classification presents a formidable challenge in machine learning, particularly when tabular datasets are plagued by noise and overlapping class boundaries. From a geometric perspective, the core difficulty lies in the topological intrusion of the majority class into the minority manifold, which obscures the true decision boundary. Traditional undersampling techniques, such as Edited Nearest Neighbours (ENN), typically employ symmetric cleaning rules and uniform voting, failing to capture the local manifold structure and often inadvertently removing informative minority samples. In this paper, we propose GMR (Geometric Manifold Rectification), a novel framework designed to robustly handle imbalanced structured data by exploiting local geometric priors. GMR makes two contributions: (1) Geometric confidence estimation that uses inverse-distance weighted kNN voting with an adaptive distance metric to capture local reliability; and (2) asymmetric cleaning that is strict on majority samples while conservatively protecting minority samples via a safe-guarding cap on minority removal. Extensive experiments on multiple benchmark datasets show that GMR is competitive with strong sampling baselines.
Meta-Sel: Efficient Demonstration Selection for In-Context Learning via Supervised Meta-Learning
Feb 12, 2026Demonstration selection is a practical bottleneck in in-context learning (ICL): under a tight prompt budget, accuracy can change substantially depending on which few-shot examples are included, yet selection must remain cheap enough to run per query over large candidate pools. We propose Meta-Sel, a lightweight supervised meta-learning approach for intent classification that learns a fast, interpretable scoring function for (candidate, query) pairs from labeled training data. Meta-Sel constructs a meta-dataset by sampling pairs from the training split and using class agreement as supervision, then trains a calibrated logistic regressor on two inexpensive meta-features: TF--IDF cosine similarity and a length-compatibility ratio. At inference time, the selector performs a single vectorized scoring pass over the full candidate pool and returns the top-k demonstrations, requiring no model fine-tuning, no online exploration, and no additional LLM calls. This yields deterministic rankings and makes the selection mechanism straightforward to audit via interpretable feature weights. Beyond proposing Meta-Sel, we provide a broad empirical study of demonstration selection, benchmarking 12 methods -- spanning prompt engineering baselines, heuristic selection, reinforcement learning, and influence-based approaches -- across four intent datasets and five open-source LLMs. Across this benchmark, Meta-Sel consistently ranks among the top-performing methods, is particularly effective for smaller models where selection quality can partially compensate for limited model capacity, and maintains competitive selection-time overhead.
Empowering Edge Intelligence: A Comprehensive Survey on On-Device AI Models
Mar 08, 2025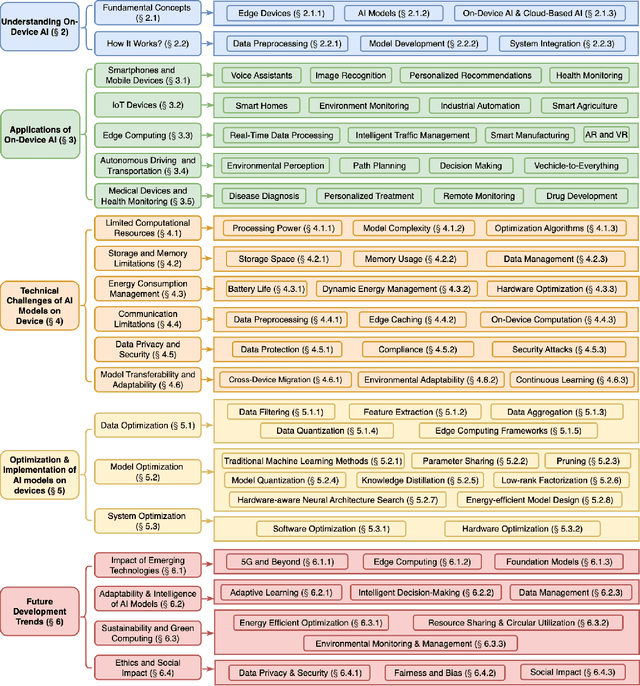



The rapid advancement of artificial intelligence (AI) technologies has led to an increasing deployment of AI models on edge and terminal devices, driven by the proliferation of the Internet of Things (IoT) and the need for real-time data processing. This survey comprehensively explores the current state, technical challenges, and future trends of on-device AI models. We define on-device AI models as those designed to perform local data processing and inference, emphasizing their characteristics such as real-time performance, resource constraints, and enhanced data privacy. The survey is structured around key themes, including the fundamental concepts of AI models, application scenarios across various domains, and the technical challenges faced in edge environments. We also discuss optimization and implementation strategies, such as data preprocessing, model compression, and hardware acceleration, which are essential for effective deployment. Furthermore, we examine the impact of emerging technologies, including edge computing and foundation models, on the evolution of on-device AI models. By providing a structured overview of the challenges, solutions, and future directions, this survey aims to facilitate further research and application of on-device AI, ultimately contributing to the advancement of intelligent systems in everyday life.
Optimizing Edge AI: A Comprehensive Survey on Data, Model, and System Strategies
Jan 04, 2025The emergence of 5G and edge computing hardware has brought about a significant shift in artificial intelligence, with edge AI becoming a crucial technology for enabling intelligent applications. With the growing amount of data generated and stored on edge devices, deploying AI models for local processing and inference has become increasingly necessary. However, deploying state-of-the-art AI models on resource-constrained edge devices faces significant challenges that must be addressed. This paper presents an optimization triad for efficient and reliable edge AI deployment, including data, model, and system optimization. First, we discuss optimizing data through data cleaning, compression, and augmentation to make it more suitable for edge deployment. Second, we explore model design and compression methods at the model level, such as pruning, quantization, and knowledge distillation. Finally, we introduce system optimization techniques like framework support and hardware acceleration to accelerate edge AI workflows. Based on an in-depth analysis of various application scenarios and deployment challenges of edge AI, this paper proposes an optimization paradigm based on the data-model-system triad to enable a whole set of solutions to effectively transfer ML models, which are initially trained in the cloud, to various edge devices for supporting multiple scenarios.
Demonstration Selection for In-Context Learning via Reinforcement Learning
Dec 05, 2024Diversity in demonstration selection is crucial for enhancing model generalization, as it enables a broader coverage of structures and concepts. However, constructing an appropriate set of demonstrations has remained a focal point of research. This paper presents the Relevance-Diversity Enhanced Selection (RDES), an innovative approach that leverages reinforcement learning to optimize the selection of diverse reference demonstrations for text classification tasks using Large Language Models (LLMs), especially in few-shot prompting scenarios. RDES employs a Q-learning framework to dynamically identify demonstrations that maximize both diversity and relevance to the classification objective by calculating a diversity score based on label distribution among selected demonstrations. This method ensures a balanced representation of reference data, leading to improved classification accuracy. Through extensive experiments on four benchmark datasets and involving 12 closed-source and open-source LLMs, we demonstrate that RDES significantly enhances classification accuracy compared to ten established baselines. Furthermore, we investigate the incorporation of Chain-of-Thought (CoT) reasoning in the reasoning process, which further enhances the model's predictive performance. The results underscore the potential of reinforcement learning to facilitate adaptive demonstration selection and deepen the understanding of classification challenges.
Enhancing Text Annotation through Rationale-Driven Collaborative Few-Shot Prompting
Sep 15, 2024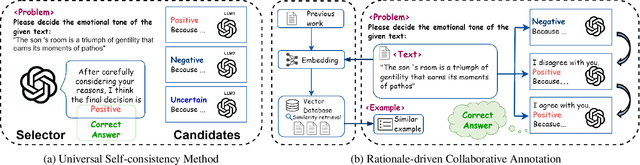

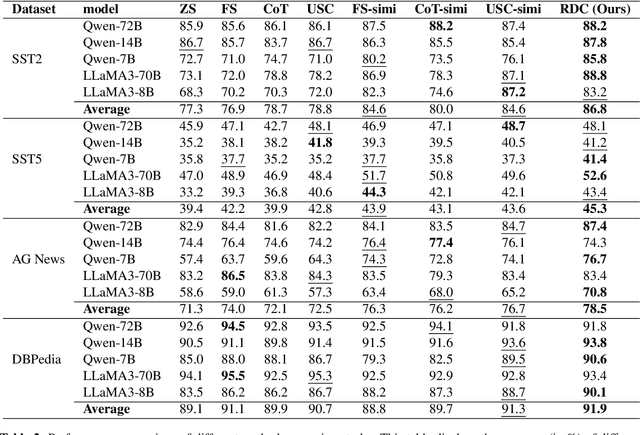
The traditional data annotation process is often labor-intensive, time-consuming, and susceptible to human bias, which complicates the management of increasingly complex datasets. This study explores the potential of large language models (LLMs) as automated data annotators to improve efficiency and consistency in annotation tasks. By employing rationale-driven collaborative few-shot prompting techniques, we aim to improve the performance of LLMs in text annotation. We conduct a rigorous evaluation of six LLMs across four benchmark datasets, comparing seven distinct methodologies. Our results demonstrate that collaborative methods consistently outperform traditional few-shot techniques and other baseline approaches, particularly in complex annotation tasks. Our work provides valuable insights and a robust framework for leveraging collaborative learning methods to tackle challenging text annotation tasks.
Exhaustive Exploitation of Nature-inspired Computation for Cancer Screening in an Ensemble Manner
Apr 06, 2024



Accurate screening of cancer types is crucial for effective cancer detection and precise treatment selection. However, the association between gene expression profiles and tumors is often limited to a small number of biomarker genes. While computational methods using nature-inspired algorithms have shown promise in selecting predictive genes, existing techniques are limited by inefficient search and poor generalization across diverse datasets. This study presents a framework termed Evolutionary Optimized Diverse Ensemble Learning (EODE) to improve ensemble learning for cancer classification from gene expression data. The EODE methodology combines an intelligent grey wolf optimization algorithm for selective feature space reduction, guided random injection modeling for ensemble diversity enhancement, and subset model optimization for synergistic classifier combinations. Extensive experiments were conducted across 35 gene expression benchmark datasets encompassing varied cancer types. Results demonstrated that EODE obtained significantly improved screening accuracy over individual and conventionally aggregated models. The integrated optimization of advanced feature selection, directed specialized modeling, and cooperative classifier ensembles helps address key challenges in current nature-inspired approaches. This provides an effective framework for robust and generalized ensemble learning with gene expression biomarkers. Specifically, we have opened EODE source code on Github at https://github.com/wangxb96/EODE.
MEL: Efficient Multi-Task Evolutionary Learning for High-Dimensional Feature Selection
Feb 14, 2024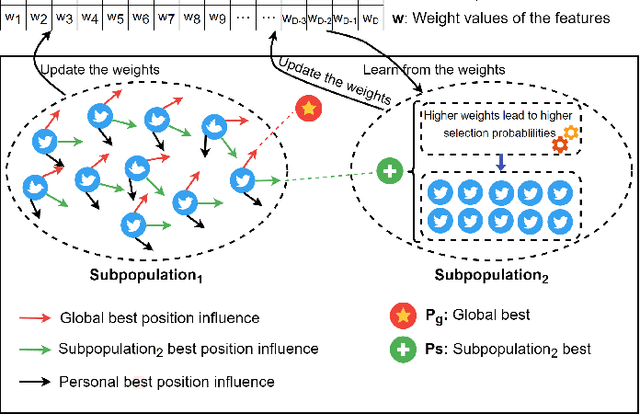
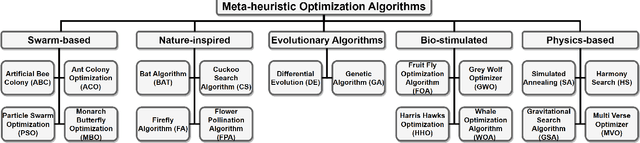
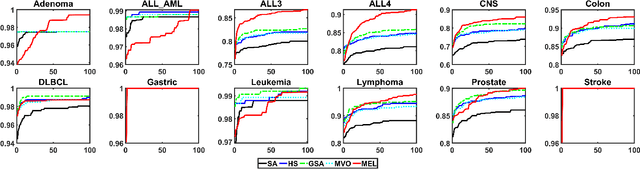
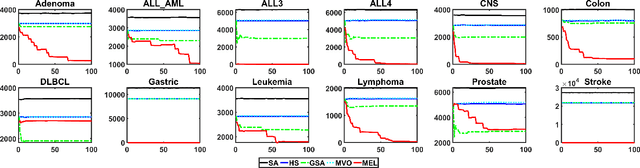
Feature selection is a crucial step in data mining to enhance model performance by reducing data dimensionality. However, the increasing dimensionality of collected data exacerbates the challenge known as the "curse of dimensionality", where computation grows exponentially with the number of dimensions. To tackle this issue, evolutionary computational (EC) approaches have gained popularity due to their simplicity and applicability. Unfortunately, the diverse designs of EC methods result in varying abilities to handle different data, often underutilizing and not sharing information effectively. In this paper, we propose a novel approach called PSO-based Multi-task Evolutionary Learning (MEL) that leverages multi-task learning to address these challenges. By incorporating information sharing between different feature selection tasks, MEL achieves enhanced learning ability and efficiency. We evaluate the effectiveness of MEL through extensive experiments on 22 high-dimensional datasets. Comparing against 24 EC approaches, our method exhibits strong competitiveness. Additionally, we have open-sourced our code on GitHub at https://github.com/wangxb96/MEL.
A Self-adaptive Weighted Differential Evolution Approach for Large-scale Feature Selection
Oct 27, 2021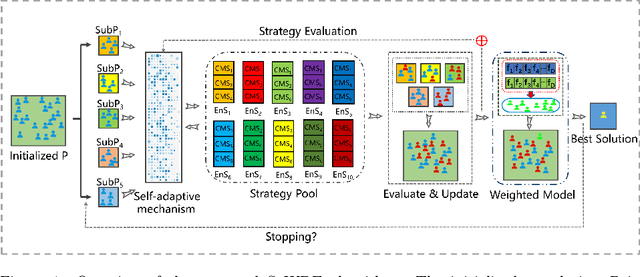

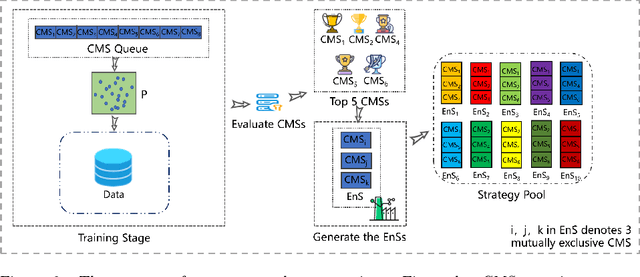

Recently, many evolutionary computation methods have been developed to solve the feature selection problem. However, the studies focused mainly on small-scale issues, resulting in stagnation issues in local optima and numerical instability when dealing with large-scale feature selection dilemmas. To address these challenges, this paper proposes a novel weighted differential evolution algorithm based on self-adaptive mechanism, named SaWDE, to solve large-scale feature selection. First, a multi-population mechanism is adopted to enhance the diversity of the population. Then, we propose a new self-adaptive mechanism that selects several strategies from a strategy pool to capture the diverse characteristics of the datasets from the historical information. Finally, a weighted model is designed to identify the important features, which enables our model to generate the most suitable feature-selection solution. We demonstrate the effectiveness of our algorithm on twelve large-scale datasets. The performance of SaWDE is superior compared to six non-EC algorithms and six other EC algorithms, on both training and test datasets and on subset size, indicating that our algorithm is a favorable tool to solve the large-scale feature selection problem. Moreover, we have experimented SaWDE with six EC algorithms on twelve higher-dimensional data, which demonstrates that SaWDE is more robust and efficient compared to those state-of-the-art methods. SaWDE source code is available on Github at https://github.com/wangxb96/SaWDE.
Research on facial expression recognition based on Multimodal data fusion and neural network
Sep 26, 2021
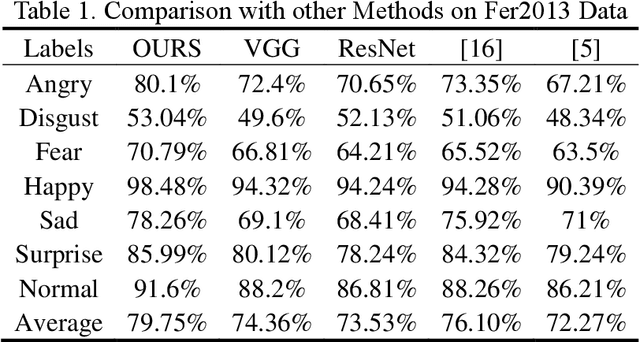
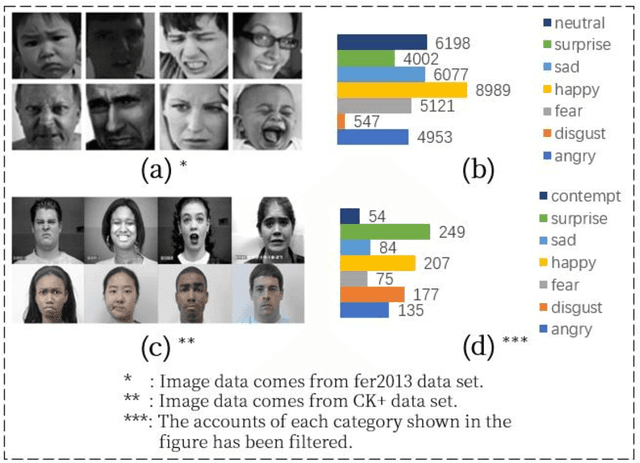
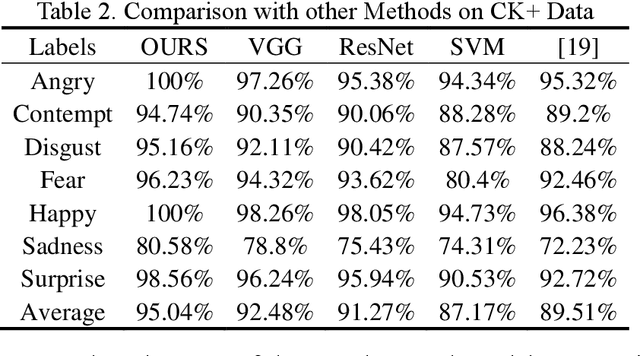
Facial expression recognition is a challenging task when neural network is applied to pattern recognition. Most of the current recognition research is based on single source facial data, which generally has the disadvantages of low accuracy and low robustness. In this paper, a neural network algorithm of facial expression recognition based on multimodal data fusion is proposed. The algorithm is based on the multimodal data, and it takes the facial image, the histogram of oriented gradient of the image and the facial landmarks as the input, and establishes CNN, LNN and HNN three sub neural networks to extract data features, using multimodal data feature fusion mechanism to improve the accuracy of facial expression recognition. Experimental results show that, benefiting by the complementarity of multimodal data, the algorithm has a great improvement in accuracy, robustness and detection speed compared with the traditional facial expression recognition algorithm. Especially in the case of partial occlusion, illumination and head posture transformation, the algorithm also shows a high confidence.