 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAR-S: Improving Safety Alignment through Self-Taught Reasoning on Safety Rules
Jan 07, 2026Defending against jailbreak attacks is crucial for the safe deployment of Large Language Models (LLMs). Recent research has attempted to improve safety by training models to reason over safety rules before responding. However, a key issue lies in determining what form of safety reasoning effectively defends against jailbreak attacks, which is difficult to explicitly design or directly obtain. To address this, we propose \textbf{STAR-S} (\textbf{S}elf-\textbf{TA}ught \textbf{R}easoning based on \textbf{S}afety rules), a framework that integrates the learning of safety rule reasoning into a self-taught loop. The core of STAR-S involves eliciting reasoning and reflection guided by safety rules, then leveraging fine-tuning to enhance safety reasoning. Repeating this process creates a synergistic cycle. Improvements in the model's reasoning and interpretation of safety rules allow it to produce better reasoning data under safety rule prompts, which is then utilized for further training. Experiments show that STAR-S effectively defends against jailbreak attacks, outperforming baselines. Code is available at: https://github.com/pikepokenew/STAR_S.git.
Thinking with Video: Video Generation as a Promising Multimodal Reasoning Paradigm
Nov 06, 2025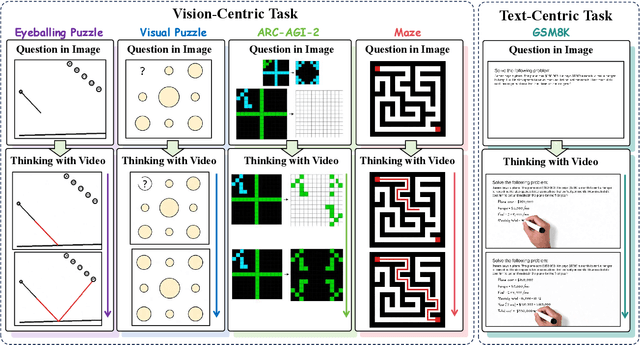
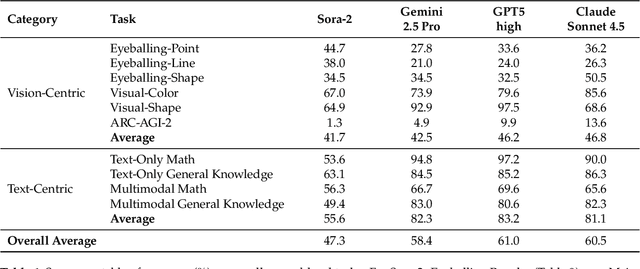
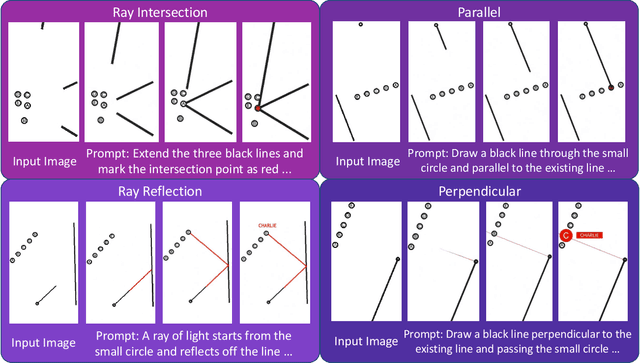
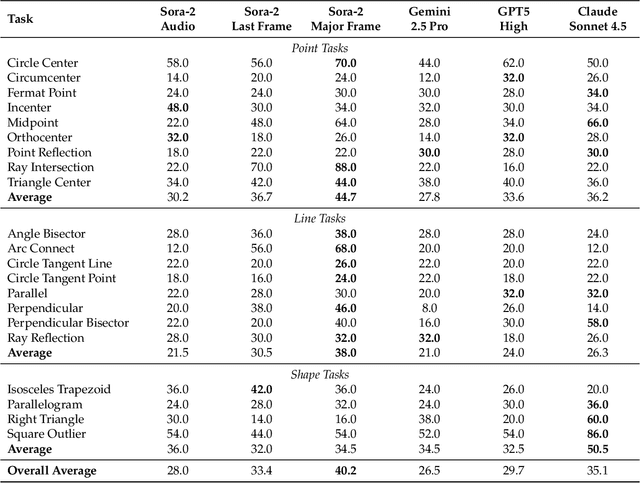
"Thinking with Text" and "Thinking with Images" paradigm significantly improve the reasoning ability of large language models (LLMs) and Vision Language Models (VLMs). However, these paradigms have inherent limitations. (1) Images capture only single moments and fail to represent dynamic processes or continuous changes, and (2) The separation of text and vision as distinct modalities, hindering unified multimodal understanding and generation. To overcome these limitations, we introduce "Thinking with Video", a new paradigm that leverages video generation models, such as Sora-2, to bridge visual and textual reasoning in a unified temporal framework. To support this exploration, we developed the Video Thinking Benchmark (VideoThinkBench). VideoThinkBench encompasses two task categories: (1) vision-centric tasks (e.g., Eyeballing Puzzles), and (2) text-centric tasks (e.g., subsets of GSM8K, MMMU). Our evaluation establishes Sora-2 as a capable reasoner. On vision-centric tasks, Sora-2 is generally comparable to state-of-the-art (SOTA) VLMs, and even surpasses VLMs on several tasks, such as Eyeballing Games. On text-centric tasks, Sora-2 achieves 92% accuracy on MATH, and 75.53% accuracy on MMMU. Furthermore, we systematically analyse the source of these abilities. We also find that self-consistency and in-context learning can improve Sora-2's performance. In summary, our findings demonstrate that the video generation model is the potential unified multimodal understanding and generation model, positions "thinking with video" as a unified multimodal reasoning paradigm.
When Personalization Tricks Detectors: The Feature-Inversion Trap in Machine-Generated Text Detection
Oct 14, 2025

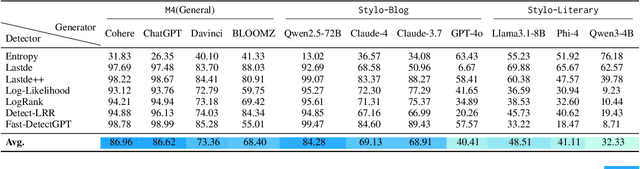
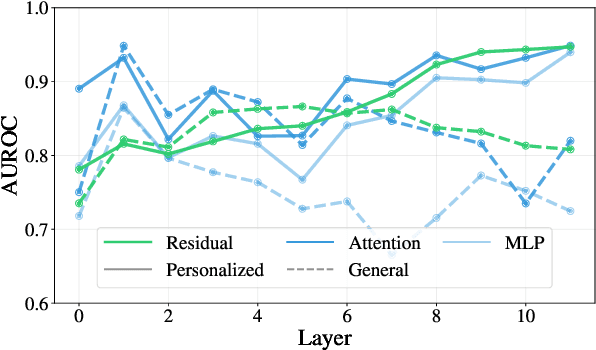
Large language models (LLMs) have grown more powerful in language generation, producing fluent text and even imitating personal style. Yet, this ability also heightens the risk of identity impersonation. To the best of our knowledge, no prior work has examined personalized machine-generated text (MGT) detection. In this paper, we introduce \dataset, the first benchmark for evaluating detector robustness in personalized settings, built from literary and blog texts paired with their LLM-generated imitations. Our experimental results demonstrate large performance gaps across detectors in personalized settings: some state-of-the-art models suffer significant drops. We attribute this limitation to the \textit{feature-inversion trap}, where features that are discriminative in general domains become inverted and misleading when applied to personalized text. Based on this finding, we propose \method, a simple and reliable way to predict detector performance changes in personalized settings. \method identifies latent directions corresponding to inverted features and constructs probe datasets that differ primarily along these features to evaluate detector dependence. Our experiments show that \method can accurately predict both the direction and the magnitude of post-transfer changes, showing 85\% correlation with the actual performance gaps. We hope that this work will encourage further research on personalized text detection.
ManipLVM-R1: Reinforcement Learning for Reasoning in Embodied Manipulation with Large Vision-Language Models
May 22, 2025Large Vision-Language Models (LVLMs) have recently advanced robotic manipulation by leveraging vision for scene perception and language for instruction following. However, existing methods rely heavily on costly human-annotated training datasets, which limits their generalization and causes them to struggle in out-of-domain (OOD) scenarios, reducing real-world adaptability. To address these challenges, we propose ManipLVM-R1, a novel reinforcement learning framework that replaces traditional supervision with Reinforcement Learning using Verifiable Rewards (RLVR). By directly optimizing for task-aligned outcomes, our method enhances generalization and physical reasoning while removing the dependence on costly annotations. Specifically, we design two rule-based reward functions targeting key robotic manipulation subtasks: an Affordance Perception Reward to enhance localization of interaction regions, and a Trajectory Match Reward to ensure the physical plausibility of action paths. These rewards provide immediate feedback and impose spatial-logical constraints, encouraging the model to go beyond shallow pattern matching and instead learn deeper, more systematic reasoning about physical interactions.
Audio Jailbreak: An Open Comprehensive Benchmark for Jailbreaking Large Audio-Language Models
May 21, 2025



The rise of Large Audio Language Models (LAMs) brings both potential and risks, as their audio outputs may contain harmful or unethical content. However, current research lacks a systematic, quantitative evaluation of LAM safety especially against jailbreak attacks, which are challenging due to the temporal and semantic nature of speech. To bridge this gap, we introduce AJailBench, the first benchmark specifically designed to evaluate jailbreak vulnerabilities in LAMs. We begin by constructing AJailBench-Base, a dataset of 1,495 adversarial audio prompts spanning 10 policy-violating categories, converted from textual jailbreak attacks using realistic text to speech synthesis. Using this dataset, we evaluate several state-of-the-art LAMs and reveal that none exhibit consistent robustness across attacks. To further strengthen jailbreak testing and simulate more realistic attack conditions, we propose a method to generate dynamic adversarial variants. Our Audio Perturbation Toolkit (APT) applies targeted distortions across time, frequency, and amplitude domains. To preserve the original jailbreak intent, we enforce a semantic consistency constraint and employ Bayesian optimization to efficiently search for perturbations that are both subtle and highly effective. This results in AJailBench-APT, an extended dataset of optimized adversarial audio samples. Our findings demonstrate that even small, semantically preserved perturbations can significantly reduce the safety performance of leading LAMs, underscoring the need for more robust and semantically aware defense mechanisms.
Pastiche Novel Generation Creating: Fan Fiction You Love in Your Favorite Author's Style
Feb 21, 2025Great novels create immersive worlds with rich character arcs, well-structured plots, and nuanced writing styles. However, current novel generation methods often rely on brief, simplistic story outlines and generate details using plain, generic language. To bridge this gap, we introduce the task of Pastiche Novel Generation, which requires the generated novels to imitate the distinctive features of the original work, including understanding character profiles, predicting plausible plot developments, and writing concrete details using vivid, expressive language. To achieve this, we propose WriterAgent, a novel generation system designed to master the core aspects of literary pastiche. WriterAgent is trained through a curriculum learning paradigm, progressing from low-level stylistic mastery to high-level narrative coherence. Its key tasks include language style learning, character modeling, plot planning, and stylish writing, ensuring comprehensive narrative control. To support this, WriterAgent leverages the WriterLoRA framework, an extension of LoRA with hierarchical and cumulative task-specific modules, each specializing in a different narrative aspect. We evaluate WriterAgent on multilingual classics like Harry Potter and Dream of the Red Chamber, demonstrating its superiority over baselines in capturing the target author's settings, character dynamics, and writing style to produce coherent, faithful narratives.
EmbedGenius: Towards Automated Software Development for Generic Embedded IoT Systems
Dec 12, 2024



Embedded IoT system development is crucial for enabling seamless connectivity and functionality across a wide range of applications. However, such a complex process requires cross-domain knowledge of hardware and software and hence often necessitates direct developer involvement, making it labor-intensive, time-consuming, and error-prone. To address this challenge, this paper introduces EmbedGenius, the first fully automated software development platform for general-purpose embedded IoT systems. The key idea is to leverage the reasoning ability of Large Language Models (LLMs) and embedded system expertise to automate the hardware-in-the-loop development process. The main methods include a component-aware library resolution method for addressing hardware dependencies, a library knowledge generation method that injects utility domain knowledge into LLMs, and an auto-programming method that ensures successful deployment. We evaluate EmbedGenius's performance across 71 modules and four mainstream embedded development platforms with over 350 IoT tasks. Experimental results show that EmbedGenius can generate codes with an accuracy of 95.7% and complete tasks with a success rate of 86.5%, surpassing human-in-the-loop baselines by 15.6%--37.7% and 25.5%--53.4%, respectively. We also show EmbedGenius's potential through case studies in environmental monitoring and remote control systems development.
Blockchain Data Analysis in the Era of Large-Language Models
Dec 09, 2024



Blockchain data analysis is essential for deriving insights, tracking transactions, identifying patterns, and ensuring the integrity and security of decentralized networks. It plays a key role in various areas, such as fraud detection, regulatory compliance, smart contract auditing, and decentralized finance (DeFi) risk management. However, existing blockchain data analysis tools face challenges, including data scarcity, the lack of generalizability, and the lack of reasoning capability. We believe large language models (LLMs) can mitigate these challenges; however, we have not seen papers discussing LLM integration in blockchain data analysis in a comprehensive and systematic way. This paper systematically explores potential techniques and design patterns in LLM-integrated blockchain data analysis. We also outline prospective research opportunities and challenges, emphasizing the need for further exploration in this promising field. This paper aims to benefit a diverse audience spanning academia, industry, and policy-making, offering valuable insights into the integration of LLMs in blockchain data analysis.
Demonstration Selection for In-Context Learning via Reinforcement Learning
Dec 05, 2024Diversity in demonstration selection is crucial for enhancing model generalization, as it enables a broader coverage of structures and concepts. However, constructing an appropriate set of demonstrations has remained a focal point of research. This paper presents the Relevance-Diversity Enhanced Selection (RDES), an innovative approach that leverages reinforcement learning to optimize the selection of diverse reference demonstrations for text classification tasks using Large Language Models (LLMs), especially in few-shot prompting scenarios. RDES employs a Q-learning framework to dynamically identify demonstrations that maximize both diversity and relevance to the classification objective by calculating a diversity score based on label distribution among selected demonstrations. This method ensures a balanced representation of reference data, leading to improved classification accuracy. Through extensive experiments on four benchmark datasets and involving 12 closed-source and open-source LLMs, we demonstrate that RDES significantly enhances classification accuracy compared to ten established baselines. Furthermore, we investigate the incorporation of Chain-of-Thought (CoT) reasoning in the reasoning process, which further enhances the model's predictive performance. The results underscore the potential of reinforcement learning to facilitate adaptive demonstration selection and deepen the understanding of classification challenges.
Write Summary Step-by-Step: A Pilot Study of Stepwise Summarization
Jun 08, 2024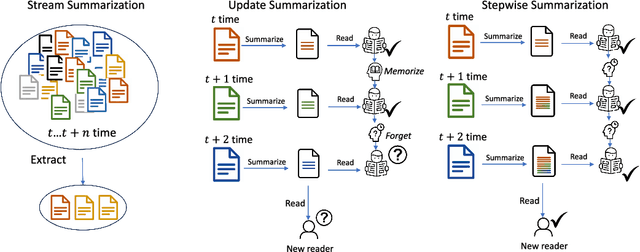

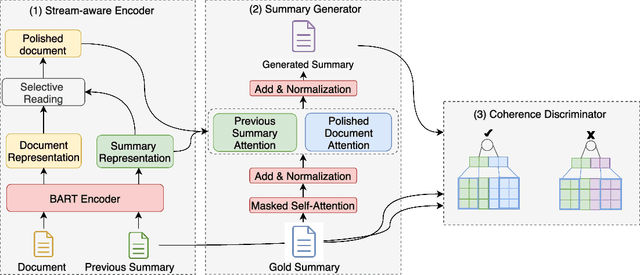
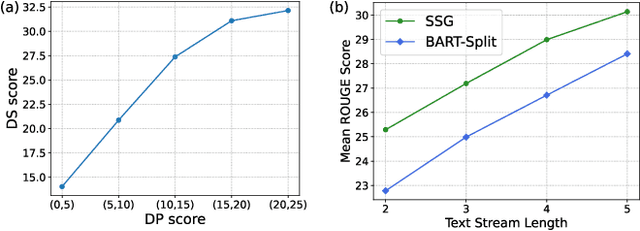
Nowadays, neural text generation has made tremendous progress in abstractive summarization tasks. However, most of the existing summarization models take in the whole document all at once, which sometimes cannot meet the needs in practice. Practically, social text streams such as news events and tweets keep growing from time to time, and can only be fed to the summarization system step by step. Hence, in this paper, we propose the task of Stepwise Summarization, which aims to generate a new appended summary each time a new document is proposed. The appended summary should not only summarize the newly added content but also be coherent with the previous summary, to form an up-to-date complete summary. To tackle this challenge, we design an adversarial learning model, named Stepwise Summary Generator (SSG). First, SSG selectively processes the new document under the guidance of the previous summary, obtaining polished document representation. Next, SSG generates the summary considering both the previous summary and the document. Finally, a convolutional-based discriminator is employed to determine whether the newly generated summary is coherent with the previous summary. For the experiment, we extend the traditional two-step update summarization setting to a multi-step stepwise setting, and re-propose a large-scale stepwise summarization dataset based on a public story generation dataset. Extensive experiments on this dataset show that SSG achieves state-of-the-art performance in terms of both automatic metrics and human evaluations. Ablation studies demonstrate the effectiveness of each module in our framework. We also discuss the benefits and limitations of recent large language models on this task.