 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Subgraph Matching by Combining Algorithms and Graph Neural Networks
Jul 27, 2025Homomorphism is a key mapping technique between graphs that preserves their structure. Given a graph and a pattern, the subgraph homomorphism problem involves finding a mapping from the pattern to the graph, ensuring that adjacent vertices in the pattern are mapped to adjacent vertices in the graph. Unlike subgraph isomorphism, which requires a one-to-one mapping, homomorphism allows multiple vertices in the pattern to map to the same vertex in the graph, making it more complex. We propose HFrame, the first graph neural network-based framework for subgraph homomorphism, which integrates traditional algorithms with machine learning techniques. We demonstrate that HFrame outperforms standard graph neural networks by being able to distinguish more graph pairs where the pattern is not homomorphic to the graph. Additionally, we provide a generalization error bound for HFrame. Through experiments on both real-world and synthetic graphs, we show that HFrame is up to 101.91 times faster than exact matching algorithms and achieves an average accuracy of 0.962.
Unify Graph Learning with Text: Unleashing LLM Potentials for Session Search
May 20, 2025Session search involves a series of interactive queries and actions to fulfill user's complex information need. Current strategies typically prioritize sequential modeling for deep semantic understanding, overlooking the graph structure in interactions. While some approaches focus on capturing structural information, they use a generalized representation for documents, neglecting the word-level semantic modeling. In this paper, we propose Symbolic Graph Ranker (SGR), which aims to take advantage of both text-based and graph-based approaches by leveraging the power of recent Large Language Models (LLMs). Concretely, we first introduce a set of symbolic grammar rules to convert session graph into text. This allows integrating session history, interaction process, and task instruction seamlessly as inputs for the LLM. Moreover, given the natural discrepancy between LLMs pre-trained on textual corpora, and the symbolic language we produce using our graph-to-text grammar, our objective is to enhance LLMs' ability to capture graph structures within a textual format. To achieve this, we introduce a set of self-supervised symbolic learning tasks including link prediction, node content generation, and generative contrastive learning, to enable LLMs to capture the topological information from coarse-grained to fine-grained. Experiment results and comprehensive analysis on two benchmark datasets, AOL and Tiangong-ST, confirm the superiority of our approach. Our paradigm also offers a novel and effective methodology that bridges the gap between traditional search strategies and modern LLMs.
CPRM: A LLM-based Continual Pre-training Framework for Relevance Modeling in Commercial Search
Dec 03, 2024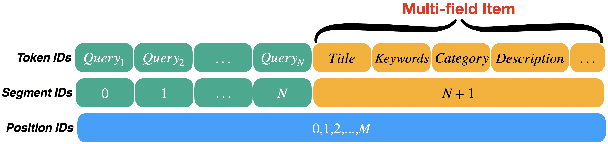
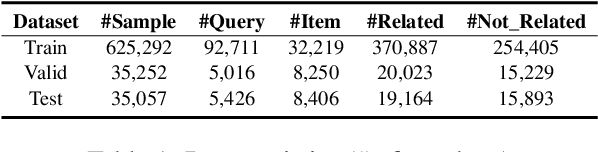
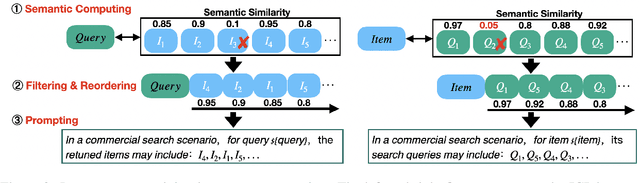
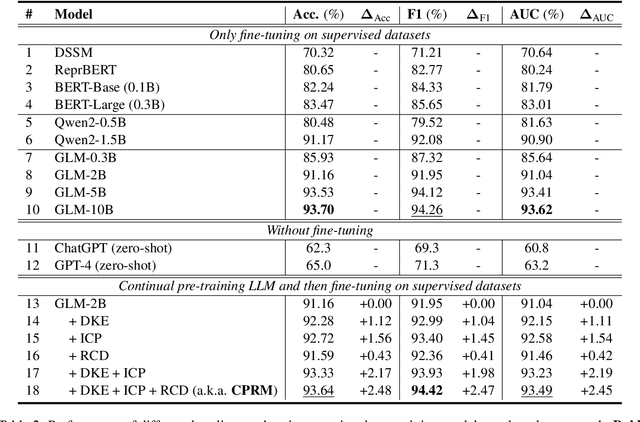
Relevance modeling between queries and items stands as a pivotal component in commercial search engines, directly affecting the user experience. Given the remarkable achievements of large language models (LLMs) in various natural language processing (NLP) tasks, LLM-based relevance modeling is gradually being adopted within industrial search systems. Nevertheless, foundational LLMs lack domain-specific knowledge and do not fully exploit the potential of in-context learning. Furthermore, structured item text remains underutilized, and there is a shortage in the supply of corresponding queries and background knowledge. We thereby propose CPRM (Continual Pre-training for Relevance Modeling), a framework designed for the continual pre-training of LLMs to address these issues. Our CPRM framework includes three modules: 1) employing both queries and multi-field item to jointly pre-train for enhancing domain knowledge, 2) applying in-context pre-training, a novel approach where LLMs are pre-trained on a sequence of related queries or items, and 3) conducting reading comprehension on items to produce associated domain knowledge and background information (e.g., generating summaries and corresponding queries) to further strengthen LLMs. Results on offline experiments and online A/B testing demonstrate that our model achieves convincing performance compared to strong baselines.
Towards Boosting LLMs-driven Relevance Modeling with Progressive Retrieved Behavior-augmented Prompting
Aug 18, 2024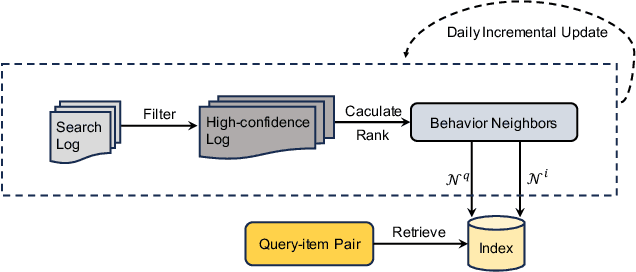

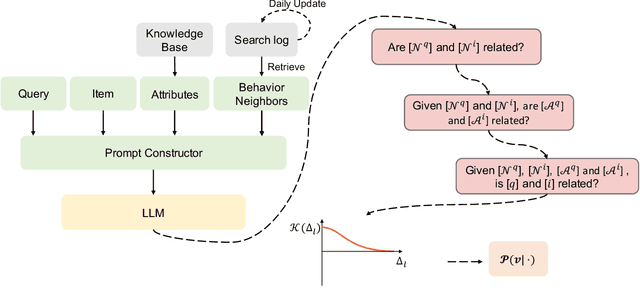
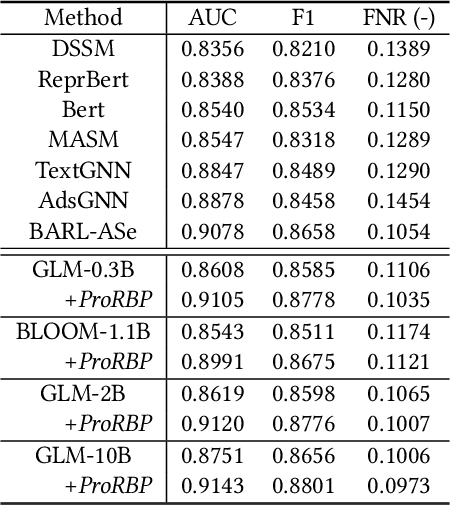
Relevance modeling is a critical component for enhancing user experience in search engines, with the primary objective of identifying items that align with users' queries. Traditional models only rely on the semantic congruence between queries and items to ascertain relevance. However, this approach represents merely one aspect of the relevance judgement, and is insufficient in isolation. Even powerful Large Language Models (LLMs) still cannot accurately judge the relevance of a query and an item from a semantic perspective. To augment LLMs-driven relevance modeling, this study proposes leveraging user interactions recorded in search logs to yield insights into users' implicit search intentions. The challenge lies in the effective prompting of LLMs to capture dynamic search intentions, which poses several obstacles in real-world relevance scenarios, i.e., the absence of domain-specific knowledge, the inadequacy of an isolated prompt, and the prohibitive costs associated with deploying LLMs. In response, we propose ProRBP, a novel Progressive Retrieved Behavior-augmented Prompting framework for integrating search scenario-oriented knowledge with LLMs effectively. Specifically, we perform the user-driven behavior neighbors retrieval from the daily search logs to obtain domain-specific knowledge in time, retrieving candidates that users consider to meet their expectations. Then, we guide LLMs for relevance modeling by employing advanced prompting techniques that progressively improve the outputs of the LLMs, followed by a progressive aggregation with comprehensive consideration of diverse aspects. For online serving, we have developed an industrial application framework tailored for the deployment of LLMs in relevance modeling. Experiments on real-world industry data and online A/B testing demonstrate our proposal achieves promising performance.
SEMINAR: Search Enhanced Multi-modal Interest Network and Approximate Retrieval for Lifelong Sequential Recommendation
Jul 15, 2024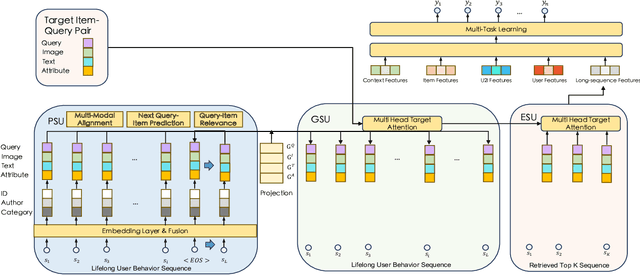

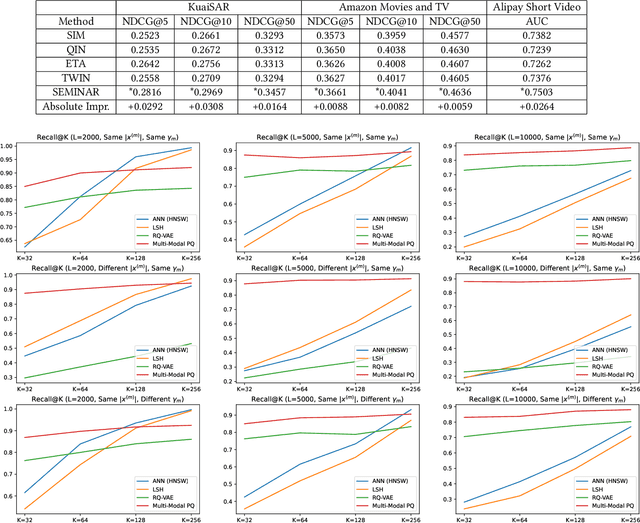
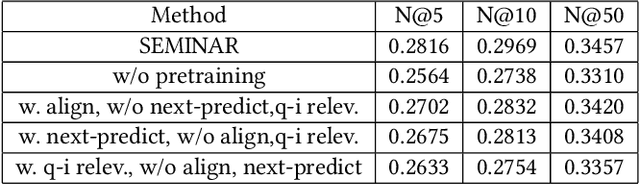
The modeling of users' behaviors is crucial in modern recommendation systems. A lot of research focuses on modeling users' lifelong sequences, which can be extremely long and sometimes exceed thousands of items. These models use the target item to search for the most relevant items from the historical sequence. However, training lifelong sequences in click through rate (CTR) prediction or personalized search ranking (PSR) is extremely difficult due to the insufficient learning problem of ID embedding, especially when the IDs in the lifelong sequence features do not exist in the samples of training dataset. Additionally, existing target attention mechanisms struggle to learn the multi-modal representations of items in the sequence well. The distribution of multi-modal embedding (text, image and attributes) output of user's interacted items are not properly aligned and there exist divergence across modalities. We also observe that users' search query sequences and item browsing sequences can fully depict users' intents and benefit from each other. To address these challenges, we propose a unified lifelong multi-modal sequence model called SEMINAR-Search Enhanced Multi-Modal Interest Network and Approximate Retrieval. Specifically, a network called Pretraining Search Unit (PSU) learns the lifelong sequences of multi-modal query-item pairs in a pretraining-finetuning manner with multiple objectives: multi-modal alignment, next query-item pair prediction, query-item relevance prediction, etc. After pretraining, the downstream model restores the pretrained embedding as initialization and finetunes the network. To accelerate the online retrieval speed of multi-modal embedding, we propose a multi-modal codebook-based product quantization strategy to approximate the exact attention calculati
Feature-based Low-Rank Compression of Large Language Models via Bayesian Optimization
May 17, 2024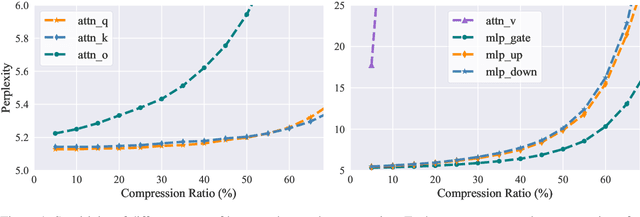

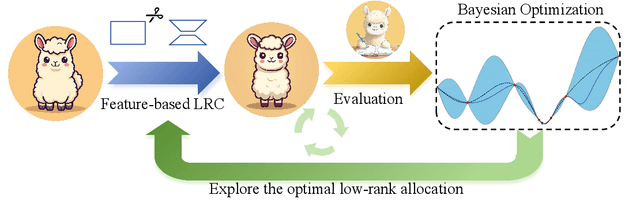

In recent years, large language models (LLMs) have driven advances in natural language processing. Still, their growing scale has increased the computational burden, necessitating a balance between efficiency and performance. Low-rank compression, a promising technique, reduces non-essential parameters by decomposing weight matrices into products of two low-rank matrices. Yet, its application in LLMs has not been extensively studied. The key to low-rank compression lies in low-rank factorization and low-rank dimensions allocation. To address the challenges of low-rank compression in LLMs, we conduct empirical research on the low-rank characteristics of large models. We propose a low-rank compression method suitable for LLMs. This approach involves precise estimation of feature distributions through pooled covariance matrices and a Bayesian optimization strategy for allocating low-rank dimensions. Experiments on the LLaMA-2 models demonstrate that our method outperforms existing strong structured pruning and low-rank compression techniques in maintaining model performance at the same compression ratio.
Multi-Intent Attribute-Aware Text Matching in Searching
Feb 12, 2024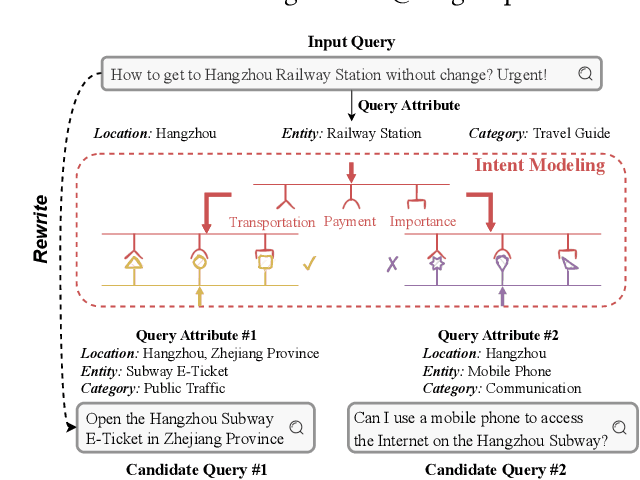
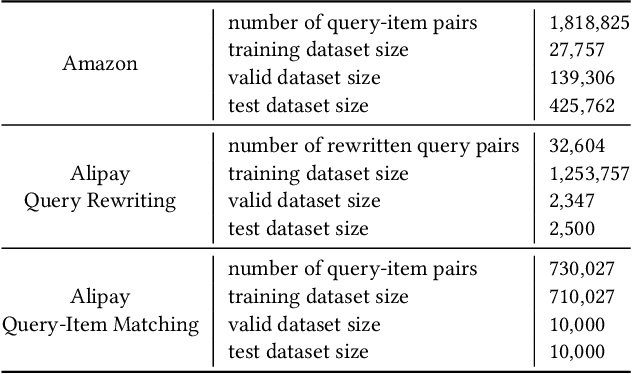
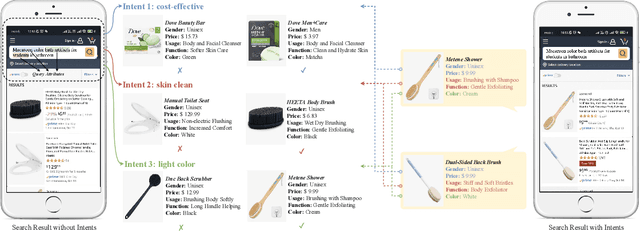
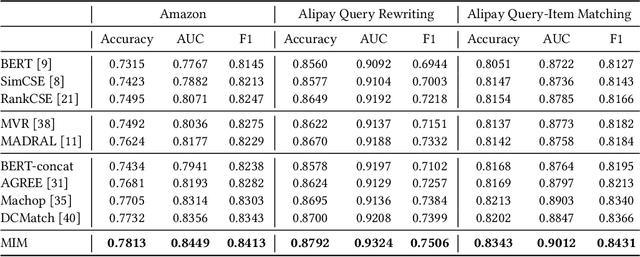
Text matching systems have become a fundamental service in most searching platforms. For instance, they are responsible for matching user queries to relevant candidate items, or rewriting the user-input query to a pre-selected high-performing one for a better search experience. In practice, both the queries and items often contain multiple attributes, such as the category of the item and the location mentioned in the query, which represent condensed key information that is helpful for matching. However, most of the existing works downplay the effectiveness of attributes by integrating them into text representations as supplementary information. Hence, in this work, we focus on exploring the relationship between the attributes from two sides. Since attributes from two ends are often not aligned in terms of number and type, we propose to exploit the benefit of attributes by multiple-intent modeling. The intents extracted from attributes summarize the diverse needs of queries and provide rich content of items, which are more refined and abstract, and can be aligned for paired inputs. Concretely, we propose a multi-intent attribute-aware matching model (MIM), which consists of three main components: attribute-aware encoder, multi-intent modeling, and intent-aware matching. In the attribute-aware encoder, the text and attributes are weighted and processed through a scaled attention mechanism with regard to the attributes' importance. Afterward, the multi-intent modeling extracts intents from two ends and aligns them. Herein, we come up with a distribution loss to ensure the learned intents are diverse but concentrated, and a kullback-leibler divergence loss that aligns the learned intents. Finally, in the intent-aware matching, the intents are evaluated by a self-supervised masking task, and then incorporated to output the final matching result.
A Multi-Granularity-Aware Aspect Learning Model for Multi-Aspect Dense Retrieval
Dec 05, 2023



Dense retrieval methods have been mostly focused on unstructured text and less attention has been drawn to structured data with various aspects, e.g., products with aspects such as category and brand. Recent work has proposed two approaches to incorporate the aspect information into item representations for effective retrieval by predicting the values associated with the item aspects. Despite their efficacy, they treat the values as isolated classes (e.g., "Smart Homes", "Home, Garden & Tools", and "Beauty & Health") and ignore their fine-grained semantic relation. Furthermore, they either enforce the learning of aspects into the CLS token, which could confuse it from its designated use for representing the entire content semantics, or learn extra aspect embeddings only with the value prediction objective, which could be insufficient especially when there are no annotated values for an item aspect. Aware of these limitations, we propose a MUlti-granulaRity-aware Aspect Learning model (MURAL) for multi-aspect dense retrieval. It leverages aspect information across various granularities to capture both coarse and fine-grained semantic relations between values. Moreover, MURAL incorporates separate aspect embeddings as input to transformer encoders so that the masked language model objective can assist implicit aspect learning even without aspect-value annotations. Extensive experiments on two real-world datasets of products and mini-programs show that MURAL outperforms state-of-the-art baselines significantly.
Dual-Modal Attention-Enhanced Text-Video Retrieval with Triplet Partial Margin Contrastive Learning
Sep 20, 2023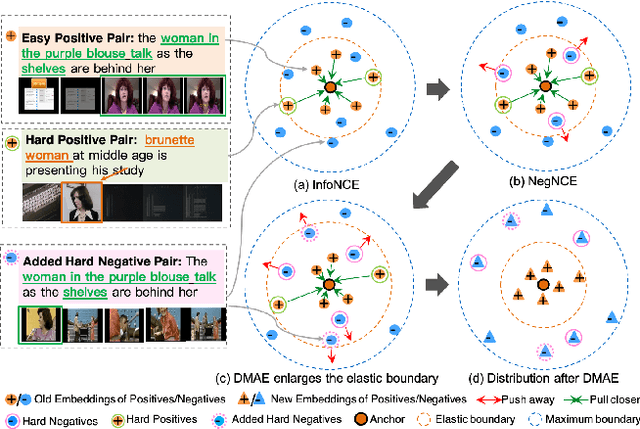
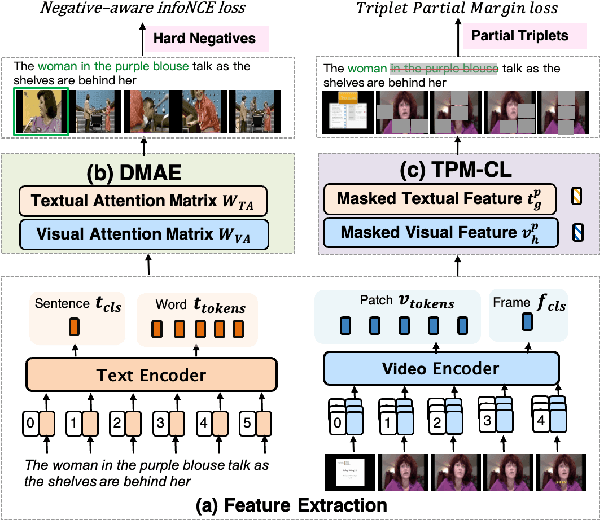
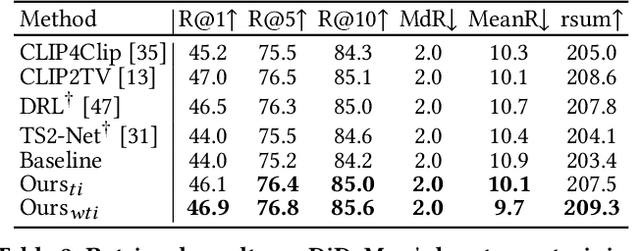
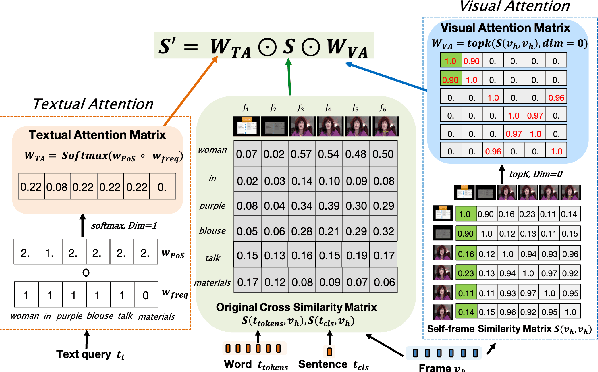
In recent years, the explosion of web videos makes text-video retrieval increasingly essential and popular for video filtering, recommendation, and search. Text-video retrieval aims to rank relevant text/video higher than irrelevant ones. The core of this task is to precisely measure the cross-modal similarity between texts and videos. Recently, contrastive learning methods have shown promising results for text-video retrieval, most of which focus on the construction of positive and negative pairs to learn text and video representations. Nevertheless, they do not pay enough attention to hard negative pairs and lack the ability to model different levels of semantic similarity. To address these two issues, this paper improves contrastive learning using two novel techniques. First, to exploit hard examples for robust discriminative power, we propose a novel Dual-Modal Attention-Enhanced Module (DMAE) to mine hard negative pairs from textual and visual clues. By further introducing a Negative-aware InfoNCE (NegNCE) loss, we are able to adaptively identify all these hard negatives and explicitly highlight their impacts in the training loss. Second, our work argues that triplet samples can better model fine-grained semantic similarity compared to pairwise samples. We thereby present a new Triplet Partial Margin Contrastive Learning (TPM-CL) module to construct partial order triplet samples by automatically generating fine-grained hard negatives for matched text-video pairs. The proposed TPM-CL designs an adaptive token masking strategy with cross-modal interaction to model subtle semantic differences. Extensive experiments demonstrate that the proposed approach outperforms existing methods on four widely-used text-video retrieval datasets, including MSR-VTT, MSVD, DiDeMo and ActivityNet.
An Unified Search and Recommendation Foundation Model for Cold-Start Scenario
Sep 16, 2023


In modern commercial search engines and recommendation systems, data from multiple domains is available to jointly train the multi-domain model. Traditional methods train multi-domain models in the multi-task setting, with shared parameters to learn the similarity of multiple tasks, and task-specific parameters to learn the divergence of features, labels, and sample distributions of individual tasks. With the development of large language models, LLM can extract global domain-invariant text features that serve both search and recommendation tasks. We propose a novel framework called S\&R Multi-Domain Foundation, which uses LLM to extract domain invariant features, and Aspect Gating Fusion to merge the ID feature, domain invariant text features and task-specific heterogeneous sparse features to obtain the representations of query and item. Additionally, samples from multiple search and recommendation scenarios are trained jointly with Domain Adaptive Multi-Task module to obtain the multi-domain foundation model. We apply the S\&R Multi-Domain foundation model to cold start scenarios in the pretrain-finetune manner, which achieves better performance than other SOTA transfer learning methods. The S\&R Multi-Domain Foundation model has been successfully deployed in Alipay Mobile Application's online services, such as content query recommendation and service card recommendation, etc.