 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEMINAR: Search Enhanced Multi-modal Interest Network and Approximate Retrieval for Lifelong Sequential Recommendation
Jul 15, 2024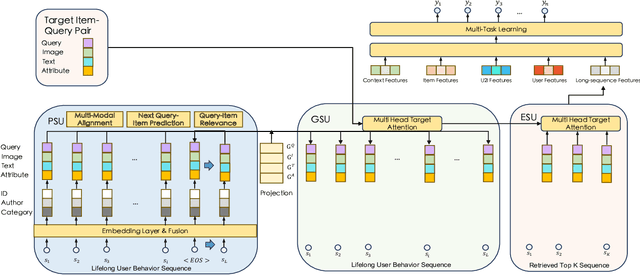

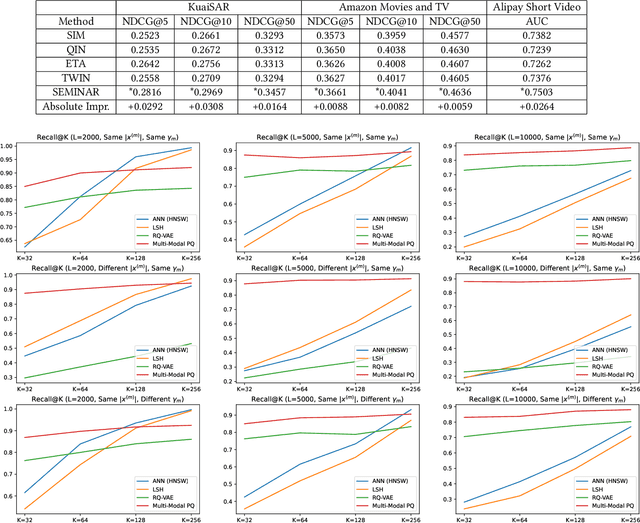
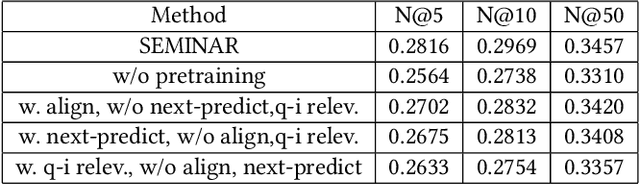
The modeling of users' behaviors is crucial in modern recommendation systems. A lot of research focuses on modeling users' lifelong sequences, which can be extremely long and sometimes exceed thousands of items. These models use the target item to search for the most relevant items from the historical sequence. However, training lifelong sequences in click through rate (CTR) prediction or personalized search ranking (PSR) is extremely difficult due to the insufficient learning problem of ID embedding, especially when the IDs in the lifelong sequence features do not exist in the samples of training dataset. Additionally, existing target attention mechanisms struggle to learn the multi-modal representations of items in the sequence well. The distribution of multi-modal embedding (text, image and attributes) output of user's interacted items are not properly aligned and there exist divergence across modalities. We also observe that users' search query sequences and item browsing sequences can fully depict users' intents and benefit from each other. To address these challenges, we propose a unified lifelong multi-modal sequence model called SEMINAR-Search Enhanced Multi-Modal Interest Network and Approximate Retrieval. Specifically, a network called Pretraining Search Unit (PSU) learns the lifelong sequences of multi-modal query-item pairs in a pretraining-finetuning manner with multiple objectives: multi-modal alignment, next query-item pair prediction, query-item relevance prediction, etc. After pretraining, the downstream model restores the pretrained embedding as initialization and finetunes the network. To accelerate the online retrieval speed of multi-modal embedding, we propose a multi-modal codebook-based product quantization strategy to approximate the exact attention calculati