 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEMINAR: Search Enhanced Multi-modal Interest Network and Approximate Retrieval for Lifelong Sequential Recommendation
Jul 15, 2024

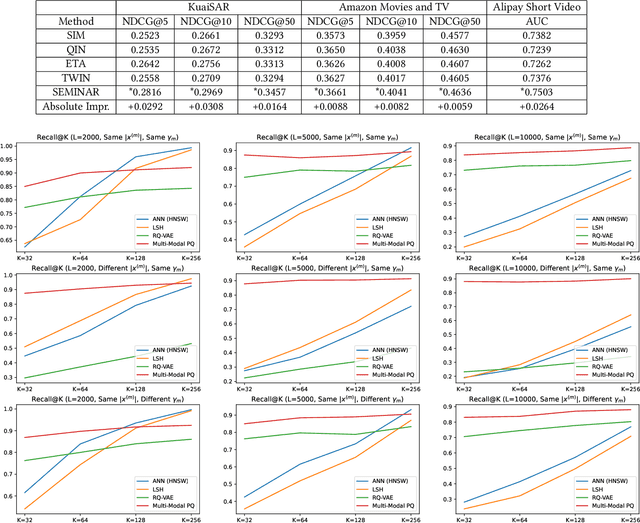
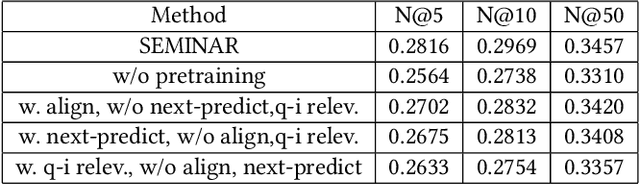
The modeling of users' behaviors is crucial in modern recommendation systems. A lot of research focuses on modeling users' lifelong sequences, which can be extremely long and sometimes exceed thousands of items. These models use the target item to search for the most relevant items from the historical sequence. However, training lifelong sequences in click through rate (CTR) prediction or personalized search ranking (PSR) is extremely difficult due to the insufficient learning problem of ID embedding, especially when the IDs in the lifelong sequence features do not exist in the samples of training dataset. Additionally, existing target attention mechanisms struggle to learn the multi-modal representations of items in the sequence well. The distribution of multi-modal embedding (text, image and attributes) output of user's interacted items are not properly aligned and there exist divergence across modalities. We also observe that users' search query sequences and item browsing sequences can fully depict users' intents and benefit from each other. To address these challenges, we propose a unified lifelong multi-modal sequence model called SEMINAR-Search Enhanced Multi-Modal Interest Network and Approximate Retrieval. Specifically, a network called Pretraining Search Unit (PSU) learns the lifelong sequences of multi-modal query-item pairs in a pretraining-finetuning manner with multiple objectives: multi-modal alignment, next query-item pair prediction, query-item relevance prediction, etc. After pretraining, the downstream model restores the pretrained embedding as initialization and finetunes the network. To accelerate the online retrieval speed of multi-modal embedding, we propose a multi-modal codebook-based product quantization strategy to approximate the exact attention calculati
Detect Depression from Social Networks with Sentiment Knowledge Sharing
Jun 13, 2023

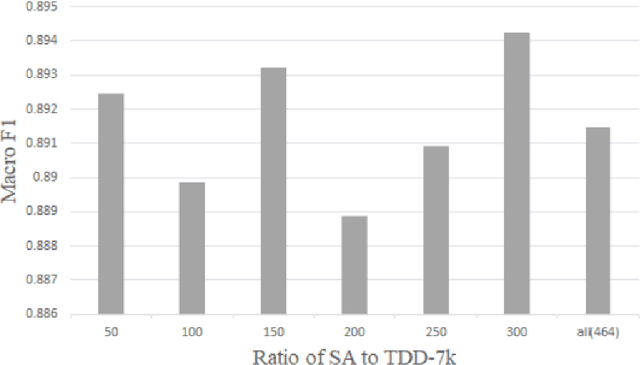
Social network plays an important role in propagating people's viewpoints, emotions, thoughts, and fears. Notably, following lockdown periods during the COVID-19 pandemic, the issue of depression has garnered increasing attention, with a significant portion of individuals resorting to social networks as an outlet for expressing emotions. Using deep learning techniques to discern potential signs of depression from social network messages facilitates the early identification of mental health conditions. Current efforts in detecting depression through social networks typically rely solely on analyzing the textual content, overlooking other potential information. In this work, we conduct a thorough investigation that unveils a strong correlation between depression and negative emotional states. The integration of such associations as external knowledge can provide valuable insights for detecting depression. Accordingly, we propose a multi-task training framework, DeSK, which utilizes shared sentiment knowledge to enhance the efficacy of depression detection. Experiments conducted on both Chinese and English datasets demonstrate the cross-lingual effectiveness of DeSK.
DeepErase: Weakly Supervised Ink Artifact Removal in Document Text Images
Oct 17, 2019
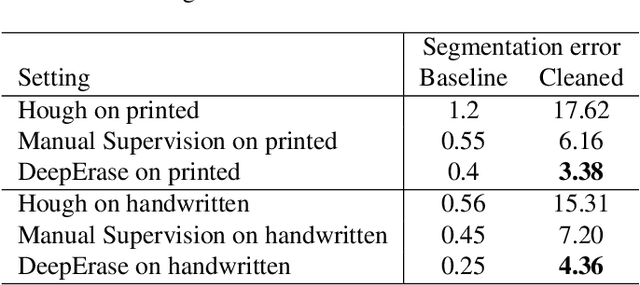

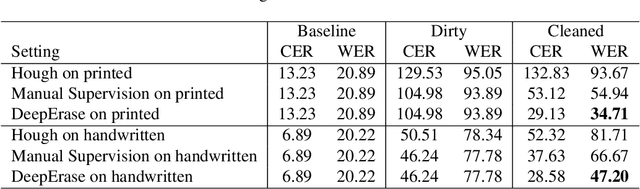
Paper-intensive industries like insurance, law, and government have long leveraged optical character recognition (OCR) to automatically transcribe hordes of scanned documents into text strings for downstream processing. Even in 2019, there are still many scanned documents and mail that come into businesses in non-digital format. Text to be extracted from real world documents is often nestled inside rich formatting, such as tabular structures or forms with fill-in-the-blank boxes or underlines whose ink often touches or even strikes through the ink of the text itself. Further, the text region could have random ink smudges or spurious strokes. Such ink artifacts can severely interfere with the performance of recognition algorithms or other downstream processing tasks. In this work, we propose DeepErase, a neural-based preprocessor to erase ink artifacts from text images. We devise a method to programmatically assemble real text images and real artifacts into realistic-looking "dirty" text images, and use them to train an artifact segmentation network in a weakly supervised manner, since pixel-level annotations are automatically obtained during the assembly process. In addition to high segmentation accuracy, we show that our cleansed images achieve a significant boost in recognition accuracy by popular OCR software such as Tesseract 4.0. Finally, we test DeepErase on out-of-distribution datasets (NIST SDB) of scanned IRS tax return forms and achieve double-digit improvements in accuracy. All experiments are performed on both printed and handwritten text. Code for all experiments is available at https://github.com/yikeqicn/DeepErase