 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyncBreaker:Stage-Aware Multimodal Adversarial Attacks on Audio-Driven Talking Head Generation
Apr 09, 2026Diffusion-based audio-driven talking-head generation enables realistic portrait animation, but also introduces risks of misuse, such as fraud and misinformation. Existing protection methods are largely limited to a single modality, and neither image-only nor audio-only attacks can effectively suppress speech-driven facial dynamics. To address this gap, we propose SyncBreaker, a stage-aware multimodal protection framework that jointly perturbs portrait and audio inputs under modality-specific perceptual constraints. Our key contributions are twofold. First, for the image stream, we introduce nullifying supervision with Multi-Interval Sampling (MIS) across diffusion stages to steer the generation toward the static reference portrait by aggregating guidance from multiple denoising intervals. Second, for the audio stream, we propose Cross-Attention Fooling (CAF), which suppresses interval-specific audio-conditioned cross-attention responses. Both streams are optimized independently and combined at inference time to enable flexible deployment. We evaluate SyncBreaker in a white-box proactive protection setting. Extensive experiments demonstrate that SyncBreaker more effectively degrades lip synchronization and facial dynamics than strong single-modality baselines, while preserving input perceptual quality and remaining robust under purification. Code: https://github.com/kitty384/SyncBreaker.
IF-GEO: Conflict-Aware Instruction Fusion for Multi-Query Generative Engine Optimization
Jan 20, 2026As Generative Engines revolutionize information retrieval by synthesizing direct answers from retrieved sources, ensuring source visibility becomes a significant challenge. Improving it through targeted content revisions is a practical strategy termed Generative Engine Optimization (GEO). However, optimizing a document for diverse queries presents a constrained optimization challenge where heterogeneous queries often impose conflicting and competing revision requirements under a limited content budget. To address this challenge, we propose IF-GEO, a "diverge-then-converge" framework comprising two phases: (i) mining distinct optimization preferences from representative latent queries; (ii) synthesizing a Global Revision Blueprint for guided editing by coordinating preferences via conflict-aware instruction fusion. To explicitly quantify IF-GEO's objective of cross-query stability, we introduce risk-aware stability metrics. Experiments on multi-query benchmarks demonstrate that IF-GEO achieves substantial performance gains while maintaining robustness across diverse retrieval scenarios.
Your One-Stop Solution for AI-Generated Video Detection
Jan 16, 2026Recent advances in generative modeling can create remarkably realistic synthetic videos, making it increasingly difficult for humans to distinguish them from real ones and necessitating reliable detection methods. However, two key limitations hinder the development of this field. \textbf{From the dataset perspective}, existing datasets are often limited in scale and constructed using outdated or narrowly scoped generative models, making it difficult to capture the diversity and rapid evolution of modern generative techniques. Moreover, the dataset construction process frequently prioritizes quantity over quality, neglecting essential aspects such as semantic diversity, scenario coverage, and technological representativeness. \textbf{From the benchmark perspective}, current benchmarks largely remain at the stage of dataset creation, leaving many fundamental issues and in-depth analysis yet to be systematically explored. Addressing this gap, we propose AIGVDBench, a benchmark designed to be comprehensive and representative, covering \textbf{31} state-of-the-art generation models and over \textbf{440,000} videos. By executing more than \textbf{1,500} evaluations on \textbf{33} existing detectors belonging to four distinct categories. This work presents \textbf{8 in-depth analyses} from multiple perspectives and identifies \textbf{4 novel findings} that offer valuable insights for future research. We hope this work provides a solid foundation for advancing the field of AI-generated video detection. Our benchmark is open-sourced at https://github.com/LongMa-2025/AIGVDBench.
Caption Injection for Optimization in Generative Search Engine
Nov 06, 2025Generative Search Engines (GSEs) leverage Retrieval-Augmented Generation (RAG) techniques and Large Language Models (LLMs) to integrate multi-source information and provide users with accurate and comprehensive responses. Unlike traditional search engines that present results in ranked lists, GSEs shift users' attention from sequential browsing to content-driven subjective perception, driving a paradigm shift in information retrieval. In this context, enhancing the subjective visibility of content through Generative Search Engine Optimization (G-SEO) methods has emerged as a new research focus. With the rapid advancement of Multimodal Retrieval-Augmented Generation (MRAG) techniques, GSEs can now efficiently integrate text, images, audio, and video, producing richer responses that better satisfy complex information needs. Existing G-SEO methods, however, remain limited to text-based optimization and fail to fully exploit multimodal data. To address this gap, we propose Caption Injection, the first multimodal G-SEO approach, which extracts captions from images and injects them into textual content, integrating visual semantics to enhance the subjective visibility of content in generative search scenarios. We systematically evaluate Caption Injection on MRAMG, a benchmark for MRAG, under both unimodal and multimodal settings. Experimental results show that Caption Injection significantly outperforms text-only G-SEO baselines under the G-Eval metric, demonstrating the necessity and effectiveness of multimodal integration in G-SEO to improve user-perceived content visibility.
RS-RAG: Bridging Remote Sensing Imagery and Comprehensive Knowledge with a Multi-Modal Dataset and Retrieval-Augmented Generation Model
Apr 07, 2025



Recent progress in VLMs has demonstrated impressive capabilities across a variety of tasks in the natural image domain. Motivated by these advancements, the remote sensing community has begun to adopt VLMs for remote sensing vision-language tasks, including scene understanding, image captioning, and visual question answering. However, existing remote sensing VLMs typically rely on closed-set scene understanding and focus on generic scene descriptions, yet lack the ability to incorporate external knowledge. This limitation hinders their capacity for semantic reasoning over complex or context-dependent queries that involve domain-specific or world knowledge. To address these challenges, we first introduced a multimodal Remote Sensing World Knowledge (RSWK) dataset, which comprises high-resolution satellite imagery and detailed textual descriptions for 14,141 well-known landmarks from 175 countries, integrating both remote sensing domain knowledge and broader world knowledge. Building upon this dataset, we proposed a novel Remote Sensing Retrieval-Augmented Generation (RS-RAG) framework, which consists of two key components. The Multi-Modal Knowledge Vector Database Construction module encodes remote sensing imagery and associated textual knowledge into a unified vector space. The Knowledge Retrieval and Response Generation module retrieves and re-ranks relevant knowledge based on image and/or text queries, and incorporates the retrieved content into a knowledge-augmented prompt to guide the VLM in producing contextually grounded responses. We validated the effectiveness of our approach on three representative vision-language tasks, including image captioning, image classification, and visual question answering, where RS-RAG significantly outperformed state-of-the-art baselines.
From Specificity to Generality: Revisiting Generalizable Artifacts in Detecting Face Deepfakes
Apr 07, 2025Detecting deepfakes has been an increasingly important topic, especially given the rapid development of AI generation techniques. In this paper, we ask: How can we build a universal detection framework that is effective for most facial deepfakes? One significant challenge is the wide variety of deepfake generators available, resulting in varying forgery artifacts (e.g., lighting inconsistency, color mismatch, etc). But should we ``teach" the detector to learn all these artifacts separately? It is impossible and impractical to elaborate on them all. So the core idea is to pinpoint the more common and general artifacts across different deepfakes. Accordingly, we categorize deepfake artifacts into two distinct yet complementary types: Face Inconsistency Artifacts (FIA) and Up-Sampling Artifacts (USA). FIA arise from the challenge of generating all intricate details, inevitably causing inconsistencies between the complex facial features and relatively uniform surrounding areas. USA, on the other hand, are the inevitable traces left by the generator's decoder during the up-sampling process. This categorization stems from the observation that all existing deepfakes typically exhibit one or both of these artifacts. To achieve this, we propose a new data-level pseudo-fake creation framework that constructs fake samples with only the FIA and USA, without introducing extra less-general artifacts. Specifically, we employ a super-resolution to simulate the USA, while design a Blender module that uses image-level self-blending on diverse facial regions to create the FIA. We surprisingly found that, with this intuitive design, a standard image classifier trained only with our pseudo-fake data can non-trivially generalize well to unseen deepfakes.
Certainly Bot Or Not? Trustworthy Social Bot Detection via Robust Multi-Modal Neural Processes
Mar 11, 2025



Social bot detection is crucial for mitigating misinformation, online manipulation, and coordinated inauthentic behavior. While existing neural network-based detectors perform well on benchmarks, they struggle with generalization due to distribution shifts across datasets and frequently produce overconfident predictions for out-of-distribution accounts beyond the training data. To address this, we introduce a novel Uncertainty Estimation for Social Bot Detection (UESBD) framework, which quantifies the predictive uncertainty of detectors beyond mere classification. For this task, we propose Robust Multi-modal Neural Processes (RMNP), which aims to enhance the robustness of multi-modal neural processes to modality inconsistencies caused by social bot camouflage. RMNP first learns unimodal representations through modality-specific encoders. Then, unimodal attentive neural processes are employed to encode the Gaussian distribution of unimodal latent variables. Furthermore, to avoid social bots stealing human features to camouflage themselves thus causing certain modalities to provide conflictive information, we introduce an evidential gating network to explicitly model the reliability of modalities. The joint latent distribution is learned through the generalized product of experts, which takes the reliability of each modality into consideration during fusion. The final prediction is obtained through Monte Carlo sampling of the joint latent distribution followed by a decoder. Experiments on three real-world benchmarks show the effectiveness of RMNP in classification and uncertainty estimation, as well as its robustness to modality conflicts.
FCoT-VL:Advancing Text-oriented Large Vision-Language Models with Efficient Visual Token Compression
Feb 22, 2025The rapid success of Vision Large Language Models (VLLMs) often depends on the high-resolution images with abundant visual tokens, which hinders training and deployment efficiency. Current training-free visual token compression methods exhibit serious performance degradation in tasks involving high-resolution, text-oriented image understanding and reasoning. In this paper, we propose an efficient visual token compression framework for text-oriented VLLMs in high-resolution scenarios. In particular, we employ a light-weight self-distillation pre-training stage to compress the visual tokens, requiring a limited numbers of image-text pairs and minimal learnable parameters. Afterwards, to mitigate potential performance degradation of token-compressed models, we construct a high-quality post-train stage. To validate the effectiveness of our method, we apply it to an advanced VLLMs, InternVL2. Experimental results show that our approach significantly reduces computational overhead while outperforming the baselines across a range of text-oriented benchmarks. We will release the models and code soon.
EvoWiki: Evaluating LLMs on Evolving Knowledge
Dec 18, 2024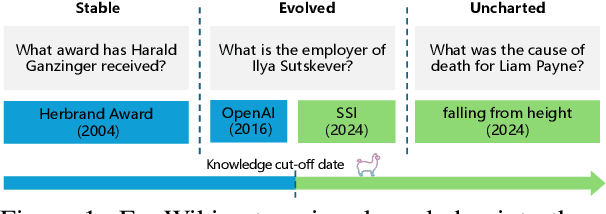
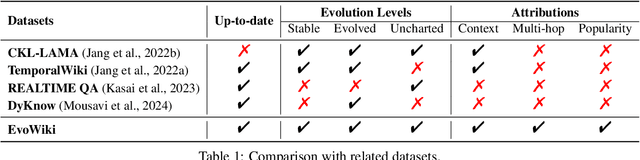
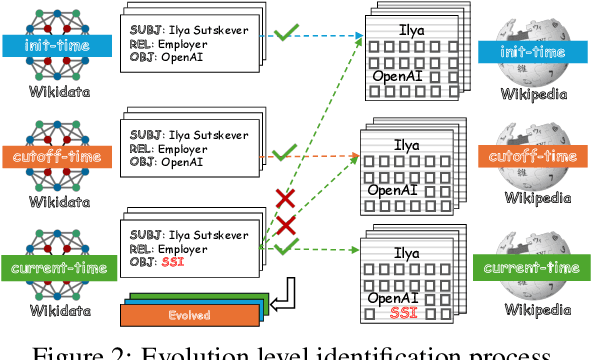
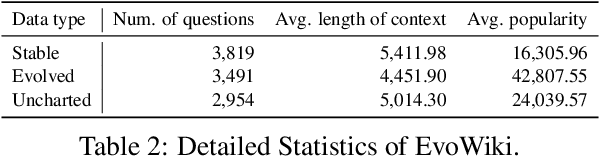
Knowledge utilization is a critical aspect of LLMs, and understanding how they adapt to evolving knowledge is essential for their effective deployment. However, existing benchmarks are predominantly static, failing to capture the evolving nature of LLMs and knowledge, leading to inaccuracies and vulnerabilities such as contamination. In this paper, we introduce EvoWiki, an evolving dataset designed to reflect knowledge evolution by categorizing information into stable, evolved, and uncharted states. EvoWiki is fully auto-updatable, enabling precise evaluation of continuously changing knowledge and newly released LLMs. Through experiments with Retrieval-Augmented Generation (RAG) and Contunual Learning (CL), we evaluate how effectively LLMs adapt to evolving knowledge. Our results indicate that current models often struggle with evolved knowledge, frequently providing outdated or incorrect responses. Moreover, the dataset highlights a synergistic effect between RAG and CL, demonstrating their potential to better adapt to evolving knowledge. EvoWiki provides a robust benchmark for advancing future research on the knowledge evolution capabilities of large language models.
Enhanced 3D Generation by 2D Editing
Dec 08, 2024



Distilling 3D representations from pretrained 2D diffusion models is essential for 3D creative applications across gaming, film, and interior design. Current SDS-based methods are hindered by inefficient information distillation from diffusion models, which prevents the creation of photorealistic 3D contents. Our research reevaluates the SDS approach by analyzing its fundamental nature as a basic image editing process that commonly results in over-saturation, over-smoothing and lack of rich content due to the poor-quality single-step denoising. To address these limitations, we propose GE3D (3D Generation by Editing). Each iteration of GE3D utilizes a 2D editing framework that combines a noising trajectory to preserve the information of the input image, alongside a text-guided denoising trajectory. We optimize the process by aligning the latents across both trajectories. This approach fully exploits pretrained diffusion models to distill multi-granularity information through multiple denoising steps, resulting in photorealistic 3D outputs. Both theoretical and experimental results confirm the effectiveness of our approach, which not only advances 3D generation technology but also establishes a novel connection between 3D generation and 2D editing. This could potentially inspire further research in the field. Code and demos are released at https://jahnsonblack.github.io/GE3D/.