 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTianJi-Environ: An Autonomous AI Scientist for Atmospheric Environmental Research
Jun 05, 2026As atmospheric environmental prediction continues to improve, interpretable validation of pollution mechanisms and feedback processes has become a main challenge in atmospheric chemistry. Yet mechanism validation based on complex numerical models still relies heavily on expert knowledge: mechanistic hypotheses must be operationalized into executable experiments, and model outputs must be organized into traceable evidence. We present TianJi-Environ, an auditable AI Scientist for atmospheric-chemistry mechanism validation. TianJi-Environ establishes the first WRF-Chem-based multi-agent framework that autonomously drives complex atmospheric-chemistry simulations, converting mechanistic hypotheses into executable configurations, testing experiments, and evidence criteria. Using ozone response and particulate-matter feedback as two representative examples, we demonstrate TianJi-Environ's capability for mechanism validation. In a summertime ozone case over the North China Plain, the system detects directionally consistent aerosol-radiation-interaction signals in shortwave radiation and boundary-layer height, but judges the evidence for ozone response to NOx control to be incomplete. In a wintertime PM2.5 case over the Guanzhong Basin, it localizes the unsupported link to insufficient propagation from black-carbon perturbation to particulate response and missing diagnostics of vertical absorptive heating. These results show that TianJi-Environ makes expert-driven mechanism validation explicit, structured, and auditable, offering a reproducible paradigm for multi-agent systems coupled with complex atmospheric-chemistry models.
MSCT: Differential Cross-Modal Attention for Deepfake Detection
Apr 09, 2026Audio-visual deepfake detection typically employs a complementary multi-modal model to check the forgery traces in the video. These methods primarily extract forgery traces through audio-visual alignment, which results from the inconsistency between audio and video modalities. However, the traditional multi-modal forgery detection method has the problem of insufficient feature extraction and modal alignment deviation. To address this, we propose a multi-scale cross-modal transformer encoder (MSCT) for deepfake detection. Our approach includes a multi-scale self-attention to integrate the features of adjacent embeddings and a differential cross-modal attention to fuse multi-modal features. Our experiments demonstrate competitive performance on the FakeAVCeleb dataset, validating the effectiveness of the proposed structure.
A Wireless World Model for AI-Native 6G Networks
Mar 26, 2026Integrating AI into the physical layer is a cornerstone of 6G networks. However, current data-driven approaches struggle to generalize across dynamic environments because they lack an intrinsic understanding of electromagnetic wave propagation. We introduce the Wireless World Model (WWM), a multi-modal foundation framework predicting the spatiotemporal evolution of wireless channels by internalizing the causal relationship between 3D geometry and signal dynamics. Pre-trained on a massive ray-traced multi-modal dataset, WWM overcomes the data authenticity gap, further validated under real-world measurement data. Using a joint-embedding predictive architecture with a multi-modal mixture-of-experts Transformer, WWM fuses channel state information, 3D point clouds, and user trajectories into a unified representation. Across the five key downstream tasks supported by WWM, it achieves remarkable performance in seen environments, unseen generalization scenarios, and real-world measurements, consistently outperforming SOTA uni-modal foundation models and task-specific models. This paves the way for physics-aware 6G intelligence that adapts to the physical world.
Goal-Oriented Framework for Optical Flow-based Multi-User Multi-Task Video Transmission
Mar 20, 2026Efficient multi-user multi-task video transmission is an important research topic within the realm of current wireless communication systems. To reduce the transmission burden and save communication resources, we propose a goal-oriented semantic communication framework for optical flow-based multi-user multi-task video transmission (OF-GSC). At the transmitter, we design a semantic encoder that consists of a motion extractor and a patch-level optical flow-based semantic representation extractor to effectively identify and select important semantic representations. At the receiver, we design a transformer-based semantic decoder for high-quality video reconstruction and video classification tasks. To minimize the communication time, we develop a deep deterministic policy gradient (DDPG)-based bandwidth allocation algorithm for multi-user transmission. For video reconstruction tasks, our OF-GSC framework achieves a significant improvement in the received video quality, as evidenced by a 13.47% increase in the structural similarity index measure (SSIM) score in comparison to DeepJSCC. For video classification tasks, OF-GSC achieves a Top-1 accuracy slightly surpassing the performance of VideoMAE with only 25% required data under the same mask ratio of 0.3. For bandwidth allocation optimization, our DDPG-based algorithm reduces the maximum transmission time by 25.97% compared with the baseline equal-bandwidth allocation scheme.
Geometric Stratification for Singular Configurations of the P3P Problem via Local Dual Space
Feb 13, 2026This paper investigates singular configurations of the P3P problem. Using local dual space, a systematic algebraic-computational framework is proposed to give a complete geometric stratification for the P3P singular configurations with respect to the multiplicity $μ$ of the camera center $O$: for $μ\ge 2$, $O$ lies on the ``danger cylinder'', for $μ\ge 3$, $O$ lies on one of three generatrices of the danger cylinder associated with the first Morley triangle or the circumcircle, and for $μ\ge 4$, $O$ lies on the circumcircle which indeed corresponds to infinite P3P solutions. Furthermore, a geometric stratification for the complementary configuration $O^\prime$ associated with a singular configuration $O$ is studied as well: for $μ\ge 2$, $O^\prime$ lies on a deltoidal surface associated with the danger cylinder, and for $μ\ge 3$, $O^\prime$ lies on one of three cuspidal curves of the deltoidal surface.
Untangling Input Language from Reasoning Language: A Diagnostic Framework for Cross-Lingual Moral Alignment in LLMs
Jan 15, 2026When LLMs judge moral dilemmas, do they reach different conclusions in different languages, and if so, why? Two factors could drive such differences: the language of the dilemma itself, or the language in which the model reasons. Standard evaluation conflates these by testing only matched conditions (e.g., English dilemma with English reasoning). We introduce a methodology that separately manipulates each factor, covering also mismatched conditions (e.g., English dilemma with Chinese reasoning), enabling decomposition of their contributions. To study \emph{what} changes, we propose an approach to interpret the moral judgments in terms of Moral Foundations Theory. As a side result, we identify evidence for splitting the Authority dimension into a family-related and an institutional dimension. Applying this methodology to English-Chinese moral judgment with 13 LLMs, we demonstrate its diagnostic power: (1) the framework isolates reasoning-language effects as contributing twice the variance of input-language effects; (2) it detects context-dependency in nearly half of models that standard evaluation misses; and (3) a diagnostic taxonomy translates these patterns into deployment guidance. We release our code and datasets at https://anonymous.4open.science/r/CrossCulturalMoralJudgement.
Grounded Misunderstandings in Asymmetric Dialogue: A Perspectivist Annotation Scheme for MapTask
Nov 05, 2025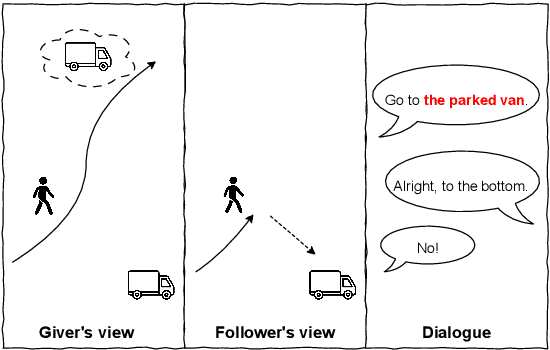
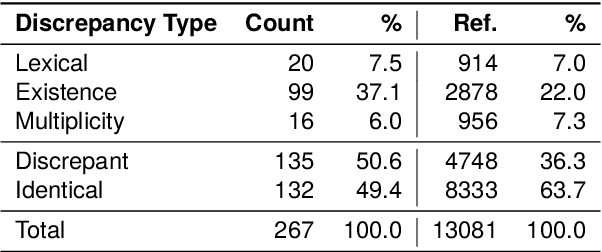

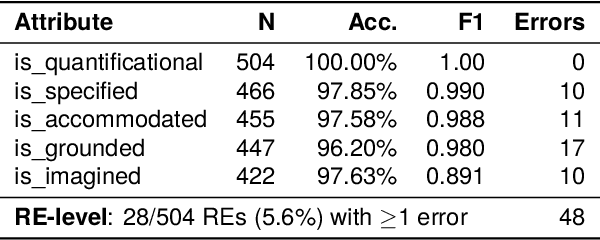
Collaborative dialogue relies on participants incrementally establishing common ground, yet in asymmetric settings they may believe they agree while referring to different entities. We introduce a perspectivist annotation scheme for the HCRC MapTask corpus (Anderson et al., 1991) that separately captures speaker and addressee grounded interpretations for each reference expression, enabling us to trace how understanding emerges, diverges, and repairs over time. Using a scheme-constrained LLM annotation pipeline, we obtain 13k annotated reference expressions with reliability estimates and analyze the resulting understanding states. The results show that full misunderstandings are rare once lexical variants are unified, but multiplicity discrepancies systematically induce divergences, revealing how apparent grounding can mask referential misalignment. Our framework provides both a resource and an analytic lens for studying grounded misunderstanding and for evaluating (V)LLMs' capacity to model perspective-dependent grounding in collaborative dialogue.
Adaptive Obstacle-Aware Task Assignment and Planning for Heterogeneous Robot Teaming
Oct 15, 2025Multi-Agent Task Assignment and Planning (MATP) has attracted growing attention but remains challenging in terms of scalability, spatial reasoning, and adaptability in obstacle-rich environments. To address these challenges, we propose OATH: Adaptive Obstacle-Aware Task Assignment and Planning for Heterogeneous Robot Teaming, which advances MATP by introducing a novel obstacle-aware strategy for task assignment. First, we develop an adaptive Halton sequence map, the first known application of Halton sampling with obstacle-aware adaptation in MATP, which adjusts sampling density based on obstacle distribution. Second, we propose a cluster-auction-selection framework that integrates obstacle-aware clustering with weighted auctions and intra-cluster task selection. These mechanisms jointly enable effective coordination among heterogeneous robots while maintaining scalability and near-optimal allocation performance. In addition, our framework leverages an LLM to interpret human instructions and directly guide the planner in real time. We validate OATH in NVIDIA Isaac Sim, showing substantial improvements in task assignment quality, scalability, adaptability to dynamic changes, and overall execution performance compared to state-of-the-art MATP baselines. A project website is available at https://llm-oath.github.io/.
Building Data-Driven Occupation Taxonomies: A Bottom-Up Multi-Stage Approach via Semantic Clustering and Multi-Agent Collaboration
Sep 19, 2025Creating robust occupation taxonomies, vital for applications ranging from job recommendation to labor market intelligence, is challenging. Manual curation is slow, while existing automated methods are either not adaptive to dynamic regional markets (top-down) or struggle to build coherent hierarchies from noisy data (bottom-up). We introduce CLIMB (CLusterIng-based Multi-agent taxonomy Builder), a framework that fully automates the creation of high-quality, data-driven taxonomies from raw job postings. CLIMB uses global semantic clustering to distill core occupations, then employs a reflection-based multi-agent system to iteratively build a coherent hierarchy. On three diverse, real-world datasets, we show that CLIMB produces taxonomies that are more coherent and scalable than existing methods and successfully capture unique regional characteristics. We release our code and datasets at https://anonymous.4open.science/r/CLIMB.
DeMeVa at LeWiDi-2025: Modeling Perspectives with In-Context Learning and Label Distribution Learning
Sep 11, 2025This system paper presents the DeMeVa team's approaches to the third edition of the Learning with Disagreements shared task (LeWiDi 2025; Leonardelli et al., 2025). We explore two directions: in-context learning (ICL) with large language models, where we compare example sampling strategies; and label distribution learning (LDL) methods with RoBERTa (Liu et al., 2019b), where we evaluate several fine-tuning methods. Our contributions are twofold: (1) we show that ICL can effectively predict annotator-specific annotations (perspectivist annotations), and that aggregating these predictions into soft labels yields competitive performance; and (2) we argue that LDL methods are promising for soft label predictions and merit further exploration by the perspectivist community.