 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHabibi: Laying the Open-Source Foundation of Unified-Dialectal Arabic Speech Synthesis
Jan 20, 2026A notable gap persists in speech synthesis research and development for Arabic dialects, particularly from a unified modeling perspective. Despite its high practical value, the inherent linguistic complexity of Arabic dialects, further compounded by a lack of standardized data, benchmarks, and evaluation guidelines, steers researchers toward safer ground. To bridge this divide, we present Habibi, a suite of specialized and unified text-to-speech models that harnesses existing open-source ASR corpora to support a wide range of high- to low-resource Arabic dialects through linguistically-informed curriculum learning. Our approach outperforms the leading commercial service in generation quality, while maintaining extensibility through effective in-context learning, without requiring text diacritization. We are committed to open-sourcing the model, along with creating the first systematic benchmark for multi-dialect Arabic speech synthesis. Furthermore, by identifying the key challenges in and establishing evaluation standards for the process, we aim to provide a solid groundwork for subsequent research. Resources at https://SWivid.github.io/Habibi/ .
Semantic-VAE: Semantic-Alignment Latent Representation for Better Speech Synthesis
Sep 26, 2025While mel-spectrograms have been widely utilized as intermediate representations in zero-shot text-to-speech (TTS), their inherent redundancy leads to inefficiency in learning text-speech alignment. Compact VAE-based latent representations have recently emerged as a stronger alternative, but they also face a fundamental optimization dilemma: higher-dimensional latent spaces improve reconstruction quality and speaker similarity, but degrade intelligibility, while lower-dimensional spaces improve intelligibility at the expense of reconstruction fidelity. To overcome this dilemma, we propose Semantic-VAE, a novel VAE framework that utilizes semantic alignment regularization in the latent space. This design alleviates the reconstruction-generation trade-off by capturing semantic structure in high-dimensional latent representations. Extensive experiments demonstrate that Semantic-VAE significantly improves synthesis quality and training efficiency. When integrated into F5-TTS, our method achieves 2.10% WER and 0.64 speaker similarity on LibriSpeech-PC, outperforming mel-based systems (2.23%, 0.60) and vanilla acoustic VAE baselines (2.65%, 0.59). We also release the code and models to facilitate further research.
AUV: Teaching Audio Universal Vector Quantization with Single Nested Codebook
Sep 26, 2025We propose AUV, a unified neural audio codec with a single codebook, which enables a favourable reconstruction of speech and further extends to general audio, including vocal, music, and sound. AUV is capable of tackling any 16 kHz mixed-domain audio segment at bit rates around 700 bps. To accomplish this, we guide the matryoshka codebook with nested domain-specific partitions, assigned with corresponding teacher models to perform distillation, all in a single-stage training. A conformer-style encoder-decoder architecture with STFT features as audio representation is employed, yielding better audio quality. Comprehensive evaluations demonstrate that AUV exhibits comparable audio reconstruction ability to state-of-the-art domain-specific single-layer quantizer codecs, showcasing the potential of audio universal vector quantization with a single codebook. The pre-trained model and demo samples are available at https://swivid.github.io/AUV/.
Accelerating Flow-Matching-Based Text-to-Speech via Empirically Pruned Step Sampling
May 26, 2025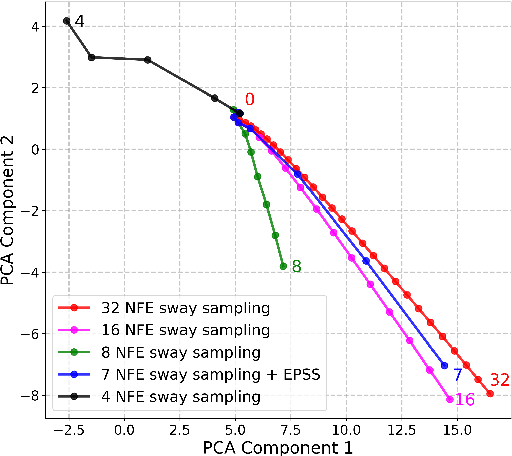
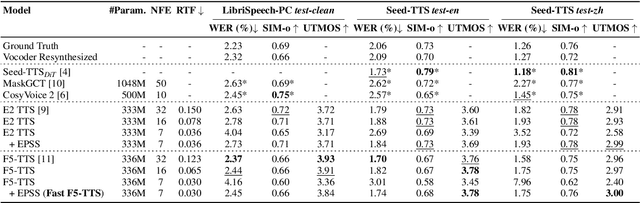
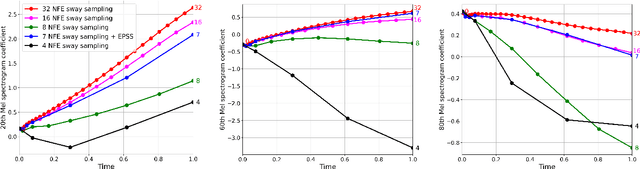

Flow-matching-based text-to-speech (TTS) models, such as Voicebox, E2 TTS, and F5-TTS, have attracted significant attention in recent years. These models require multiple sampling steps to reconstruct speech from noise, making inference speed a key challenge. Reducing the number of sampling steps can greatly improve inference efficiency. To this end, we introduce Fast F5-TTS, a training-free approach to accelerate the inference of flow-matching-based TTS models. By inspecting the sampling trajectory of F5-TTS, we identify redundant steps and propose Empirically Pruned Step Sampling (EPSS), a non-uniform time-step sampling strategy that effectively reduces the number of sampling steps. Our approach achieves a 7-step generation with an inference RTF of 0.030 on an NVIDIA RTX 3090 GPU, making it 4 times faster than the original F5-TTS while maintaining comparable performance. Furthermore, EPSS performs well on E2 TTS models, demonstrating its strong generalization ability.
Towards Flow-Matching-based TTS without Classifier-Free Guidance
Apr 29, 2025Flow matching has demonstrated strong generative capabilities and has become a core component in modern Text-to-Speech (TTS) systems. To ensure high-quality speech synthesis, Classifier-Free Guidance (CFG) is widely used during the inference of flow-matching-based TTS models. However, CFG incurs substantial computational cost as it requires two forward passes, which hinders its applicability in real-time scenarios. In this paper, we explore removing CFG from flow-matching-based TTS models to improve inference efficiency, while maintaining performance. Specifically, we reformulated the flow matching training target to directly approximate the CFG optimization trajectory. This training method eliminates the need for unconditional model evaluation and guided tuning during inference, effectively cutting the computational overhead in half. Furthermore, It can be seamlessly integrated with existing optimized sampling strategies. We validate our approach using the F5-TTS model on the LibriTTS dataset. Experimental results show that our method achieves a 9$\times$ inference speed-up compared to the baseline F5-TTS, while preserving comparable speech quality. We will release the code and models to support reproducibility and foster further research in this area.
F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching
Oct 09, 2024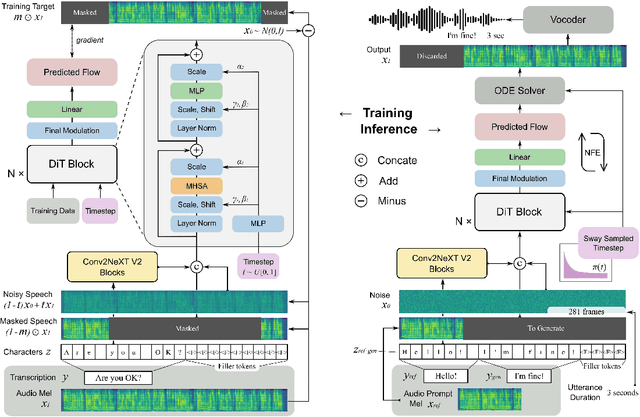
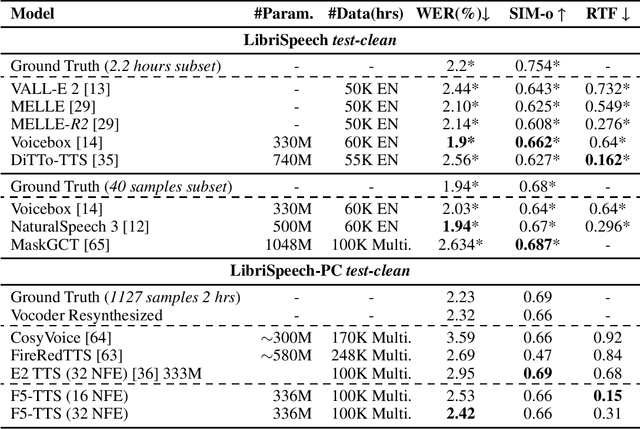
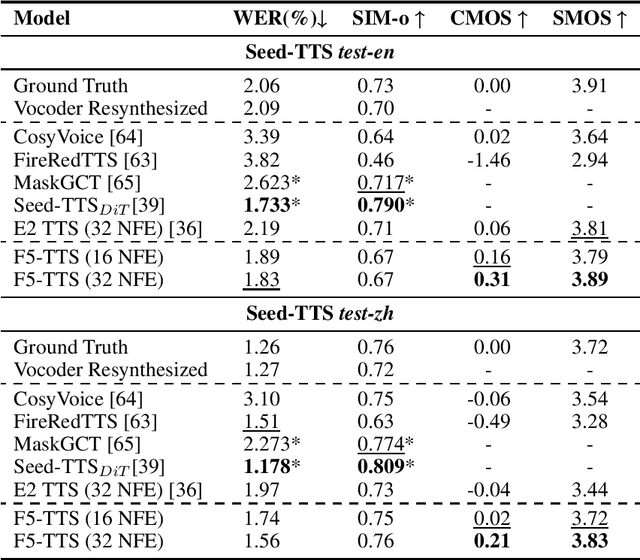
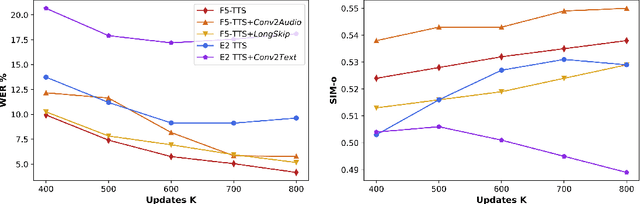
This paper introduces F5-TTS, a fully non-autoregressive text-to-speech system based on flow matching with Diffusion Transformer (DiT). Without requiring complex designs such as duration model, text encoder, and phoneme alignment, the text input is simply padded with filler tokens to the same length as input speech, and then the denoising is performed for speech generation, which was originally proved feasible by E2 TTS. However, the original design of E2 TTS makes it hard to follow due to its slow convergence and low robustness. To address these issues, we first model the input with ConvNeXt to refine the text representation, making it easy to align with the speech. We further propose an inference-time Sway Sampling strategy, which significantly improves our model's performance and efficiency. This sampling strategy for flow step can be easily applied to existing flow matching based models without retraining. Our design allows faster training and achieves an inference RTF of 0.15, which is greatly improved compared to state-of-the-art diffusion-based TTS models. Trained on a public 100K hours multilingual dataset, our Fairytaler Fakes Fluent and Faithful speech with Flow matching (F5-TTS) exhibits highly natural and expressive zero-shot ability, seamless code-switching capability, and speed control efficiency. Demo samples can be found at https://SWivid.github.io/F5-TTS. We release all code and checkpoints to promote community development.