 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Flow-Matching-based TTS without Classifier-Free Guidance
Apr 29, 2025Flow matching has demonstrated strong generative capabilities and has become a core component in modern Text-to-Speech (TTS) systems. To ensure high-quality speech synthesis, Classifier-Free Guidance (CFG) is widely used during the inference of flow-matching-based TTS models. However, CFG incurs substantial computational cost as it requires two forward passes, which hinders its applicability in real-time scenarios. In this paper, we explore removing CFG from flow-matching-based TTS models to improve inference efficiency, while maintaining performance. Specifically, we reformulated the flow matching training target to directly approximate the CFG optimization trajectory. This training method eliminates the need for unconditional model evaluation and guided tuning during inference, effectively cutting the computational overhead in half. Furthermore, It can be seamlessly integrated with existing optimized sampling strategies. We validate our approach using the F5-TTS model on the LibriTTS dataset. Experimental results show that our method achieves a 9$\times$ inference speed-up compared to the baseline F5-TTS, while preserving comparable speech quality. We will release the code and models to support reproducibility and foster further research in this area.
A High Fidelity and Low Complexity Neural Audio Coding
Oct 17, 2023Audio coding is an essential module in the real-time communication system. Neural audio codecs can compress audio samples with a low bitrate due to the strong modeling and generative capabilities of deep neural networks. To address the poor high-frequency expression and high computational cost and storage consumption, we proposed an integrated framework that utilizes a neural network to model wide-band components and adopts traditional signal processing to compress high-band components according to psychological hearing knowledge. Inspired by auditory perception theory, a perception-based loss function is designed to improve harmonic modeling. Besides, generative adversarial network (GAN) compression is proposed for the first time for neural audio codecs. Our method is superior to prior advanced neural codecs across subjective and objective metrics and allows real-time inference on desktop and mobile.
Gesper: A Restoration-Enhancement Framework for General Speech Reconstruction
Jun 14, 2023This paper describes a real-time General Speech Reconstruction (Gesper) system submitted to the ICASSP 2023 Speech Signal Improvement (SSI) Challenge. This novel proposed system is a two-stage architecture, in which the speech restoration is performed, and then cascaded by speech enhancement. We propose a complex spectral mapping-based generative adversarial network (CSM-GAN) as the speech restoration module for the first time. For noise suppression and dereverberation, the enhancement module is performed with fullband-wideband parallel processing. On the blind test set of ICASSP 2023 SSI Challenge, the proposed Gesper system, which satisfies the real-time condition, achieves 3.27 P.804 overall mean opinion score (MOS) and 3.35 P.835 overall MOS, ranked 1st in both track 1 and track 2.
A General Deep Learning Speech Enhancement Framework Motivated by Taylor's Theorem
Nov 30, 2022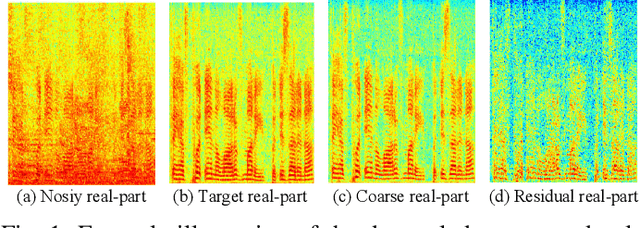
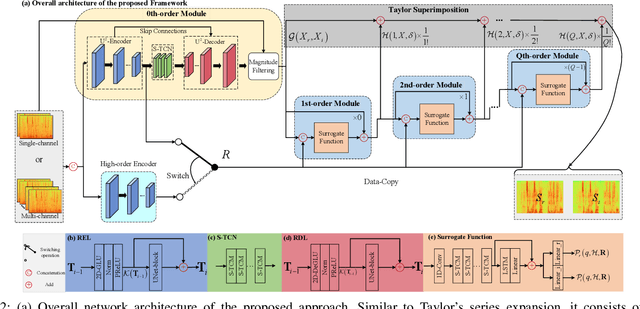
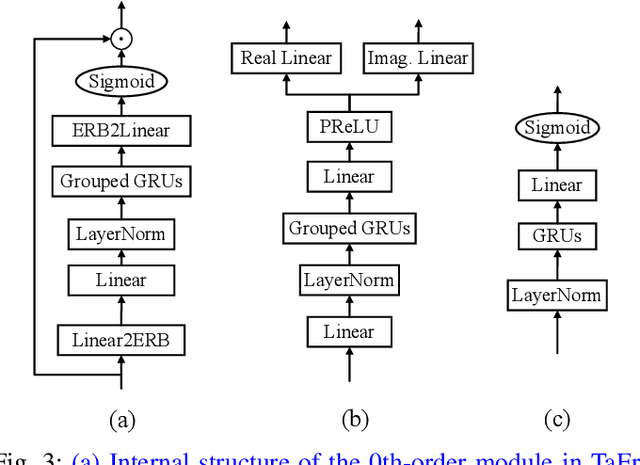
While deep neural networks greatly facilitate the proliferation of the speech enhancement field, most of the existing methods are developed following either heuristic or blind optimization criteria, which severely hampers interpretability and transparency. Inspired by Taylor's theorem, we propose a general unfolding framework for both single- and multi-channel speech enhancement tasks. Concretely, we formulate the complex spectrum recovery into the spectral magnitude mapping in the neighboring space of the noisy mixture, in which the sparse prior is introduced for phase modification in advance. Based on that, the mapping function is decomposed into the superimposition of the 0th-order and high-order polynomials in Taylor's series, where the former coarsely removes the interference in the magnitude domain and the latter progressively complements the remaining spectral detail in the complex spectrum domain. In addition, we study the relation between adjacent order term and reveal that each high-order term can be recursively estimated with its lower-order term, and each high-order term is then proposed to evaluate using a surrogate function with trainable weights, so that the whole system can be trained in an end-to-end manner. Extensive experiments are conducted on WSJ0-SI84, DNS-Challenge, Voicebank+Demand, and spatialized Librispeech datasets. Quantitative results show that the proposed approach not only yields competitive performance over existing top-performed approaches, but also enjoys decent internal transparency and flexibility.
TaylorBeamixer: Learning Taylor-Inspired All-Neural Multi-Channel Speech Enhancement from Beam-Space Dictionary Perspective
Nov 30, 2022Despite the promising performance of existing frame-wise all-neural beamformers in the speech enhancement field, it remains unclear what the underlying mechanism exists. In this paper, we revisit the beamforming behavior from the beam-space dictionary perspective and formulate it into the learning and mixing of different beam-space components. Based on that, we propose an all-neural beamformer called TaylorBM to simulate Taylor's series expansion operation in which the 0th-order term serves as a spatial filter to conduct the beam mixing, and several high-order terms are tasked with residual noise cancellation for post-processing. The whole system is devised to work in an end-to-end manner. Experiments are conducted on the spatialized LibriSpeech corpus and results show that the proposed approach outperforms existing advanced baselines in terms of evaluation metrics.
Optimizing Shoulder to Shoulder: A Coordinated Sub-Band Fusion Model for Real-Time Full-Band Speech Enhancement
Mar 30, 2022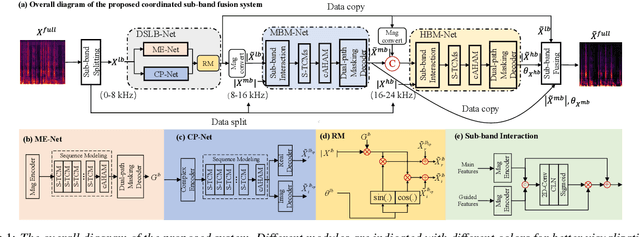
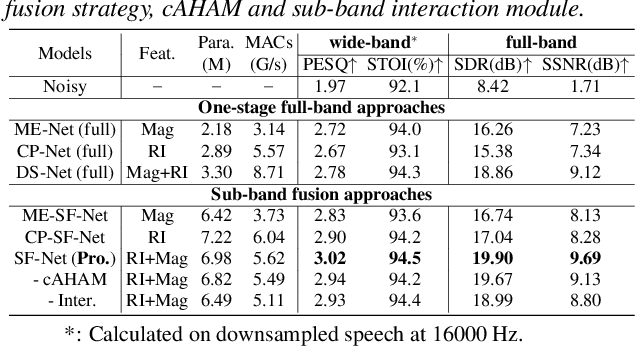
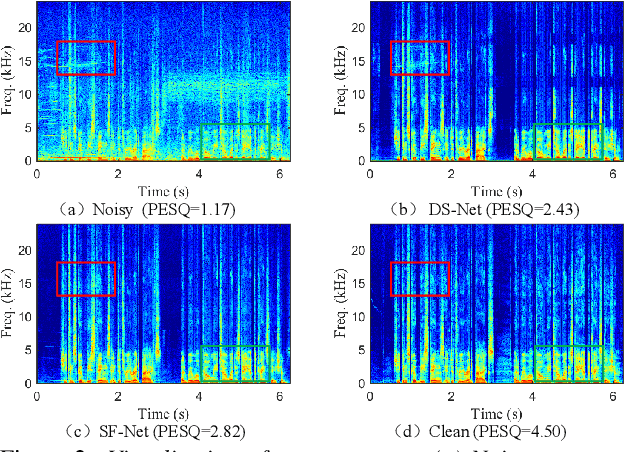
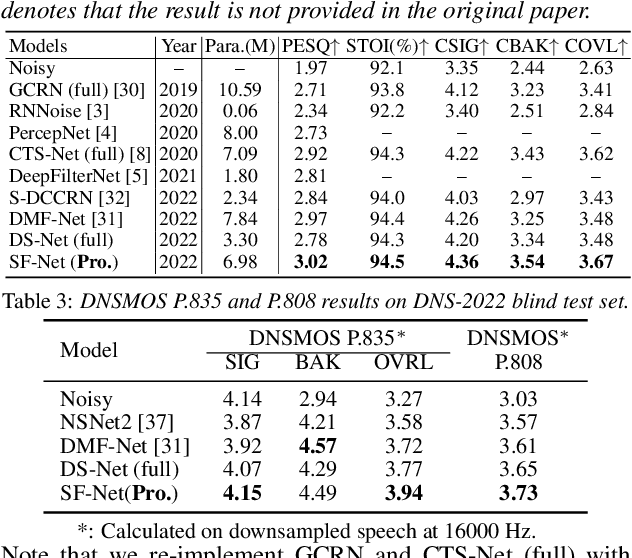
Due to the high computational complexity to model more frequency bands, it is still intractable to conduct real-time full-band speech enhancement based on deep neural networks. Recent studies typically utilize the compressed perceptually motivated features with relatively low frequency resolution to filter the full-band spectrum by one-stage networks, leading to limited speech quality improvements. In this paper, we propose a coordinated sub-band fusion network for full-band speech enhancement, which aims to recover the low- (0-8 kHz), middle- (8-16 kHz), and high-band (16-24 kHz) in a step-wise manner. Specifically, a dual-stream network is first pretrained to recover the low-band complex spectrum, and another two sub-networks are designed as the middle- and high-band noise suppressors in the magnitude-only domain. To fully capitalize on the information intercommunication, we employ a sub-band interaction module to provide external knowledge guidance across different frequency bands. Extensive experiments show that the proposed method yields consistent performance advantages over state-of-the-art full-band baselines.
Low-latency Monaural Speech Enhancement with Deep Filter-bank Equalizer
Feb 14, 2022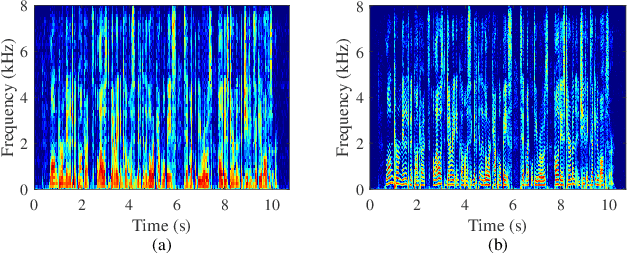

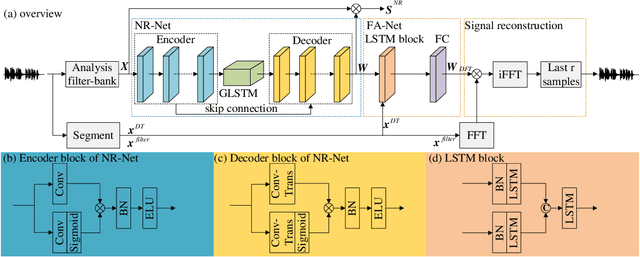
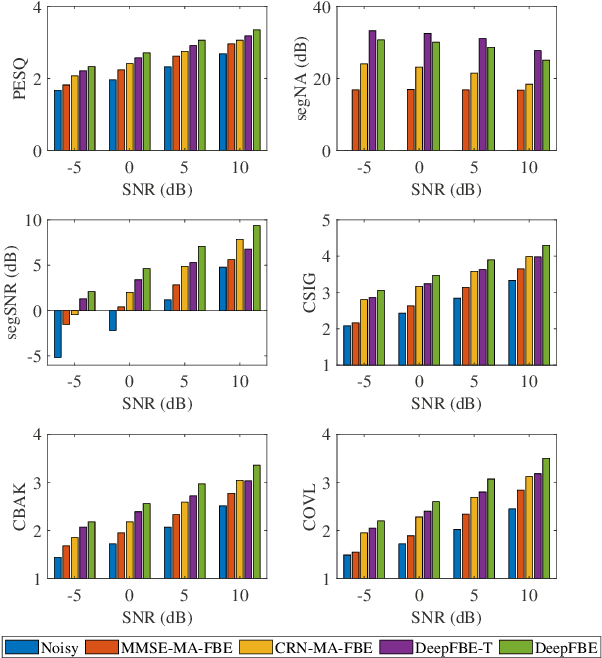
It is highly desirable that speech enhancement algorithms can achieve good performance while keeping low latency for many applications, such as digital hearing aids, acoustically transparent hearing devices, and public address systems. To improve the performance of traditional low-latency speech enhancement algorithms, a deep filter-bank equalizer (FBE) framework was proposed, which integrated a deep learning-based subband noise reduction network with a deep learning-based shortened digital filter mapping network. In the first network, a deep learning model was trained with a controllable small frame shift to satisfy the low-latency demand, i.e., $\le$ 4 ms, so as to obtain (complex) subband gains, which could be regarded as an adaptive digital filter in each frame. In the second network, to reduce the latency, this adaptive digital filter was implicitly shortened by a deep learning-based framework, and was then applied to noisy speech to reconstruct the enhanced speech without the overlap-add method. Experimental results on the WSJ0-SI84 corpus indicated that the proposed deep FBE with only 4-ms latency achieved much better performance than traditional low-latency speech enhancement algorithms in terms of the indices such as PESQ, STOI, and the amount of noise reduction.
A Neural Beam Filter for Real-time Multi-channel Speech Enhancement
Feb 05, 2022


Most deep learning-based multi-channel speech enhancement methods focus on designing a set of beamforming coefficients to directly filter the low signal-to-noise ratio signals received by microphones, which hinders the performance of these approaches. To handle these problems, this paper designs a causal neural beam filter that fully exploits the spatial-spectral information in the beam domain. Specifically, multiple beams are designed to steer towards all directions using a parameterized super-directive beamformer in the first stage. After that, the neural spatial filter is learned by simultaneously modeling the spatial and spectral discriminability of the speech and the interference, so as to extract the desired speech coarsely in the second stage. Finally, to further suppress the interference components especially at low frequencies, a residual estimation module is adopted to refine the output of the second stage. Experimental results demonstrate that the proposed approach outperforms many state-of-the-art multi-channel methods on the generated multi-channel speech dataset based on the DNS-Challenge dataset.
Embedding and Beamforming: All-neural Causal Beamformer for Multichannel Speech Enhancement
Sep 02, 2021

The spatial covariance matrix has been considered to be significant for beamformers. Standing upon the intersection of traditional beamformers and deep neural networks, we propose a causal neural beamformer paradigm called Embedding and Beamforming, and two core modules are designed accordingly, namely EM and BM. For EM, instead of estimating spatial covariance matrix explicitly, the 3-D embedding tensor is learned with the network, where both spectral and spatial discriminative information can be represented. For BM, a network is directly leveraged to derive the beamforming weights so as to implement filter-and-sum operation. To further improve the speech quality, a post-processing module is introduced to further suppress the residual noise. Based on the DNS-Challenge dataset, we conduct the experiments for multichannel speech enhancement and the results show that the proposed system outperforms previous advanced baselines by a large margin in multiple evaluation metrics.
Pixel Difference Networks for Efficient Edge Detection
Aug 16, 2021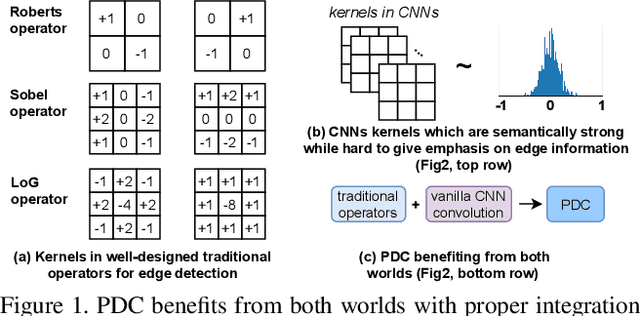

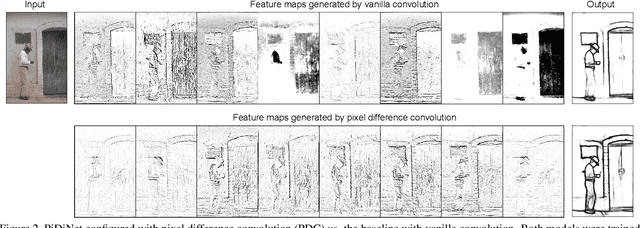
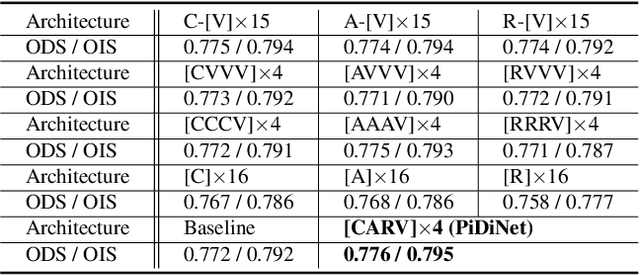
Recently, deep Convolutional Neural Networks (CNNs) can achieve human-level performance in edge detection with the rich and abstract edge representation capacities. However, the high performance of CNN based edge detection is achieved with a large pretrained CNN backbone, which is memory and energy consuming. In addition, it is surprising that the previous wisdom from the traditional edge detectors, such as Canny, Sobel, and LBP are rarely investigated in the rapid-developing deep learning era. To address these issues, we propose a simple, lightweight yet effective architecture named Pixel Difference Network (PiDiNet) for efficient edge detection. Extensive experiments on BSDS500, NYUD, and Multicue are provided to demonstrate its effectiveness, and its high training and inference efficiency. Surprisingly, when training from scratch with only the BSDS500 and VOC datasets, PiDiNet can surpass the recorded result of human perception (0.807 vs. 0.803 in ODS F-measure) on the BSDS500 dataset with 100 FPS and less than 1M parameters. A faster version of PiDiNet with less than 0.1M parameters can still achieve comparable performance among state of the arts with 200 FPS. Results on the NYUD and Multicue datasets show similar observations. The codes are available at https://github.com/zhuoinoulu/pidinet.