 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Shoulder to Shoulder: A Coordinated Sub-Band Fusion Model for Real-Time Full-Band Speech Enhancement
Paper and Code
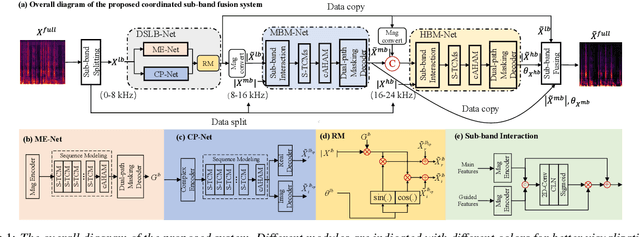
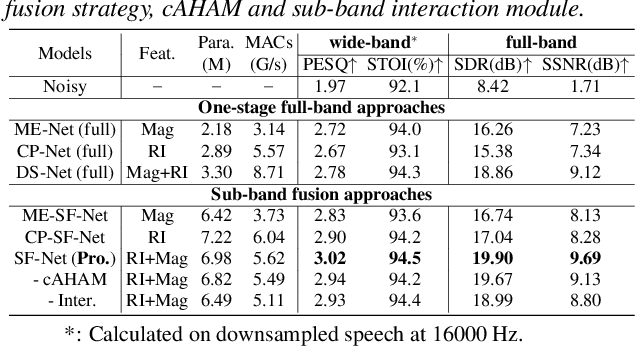
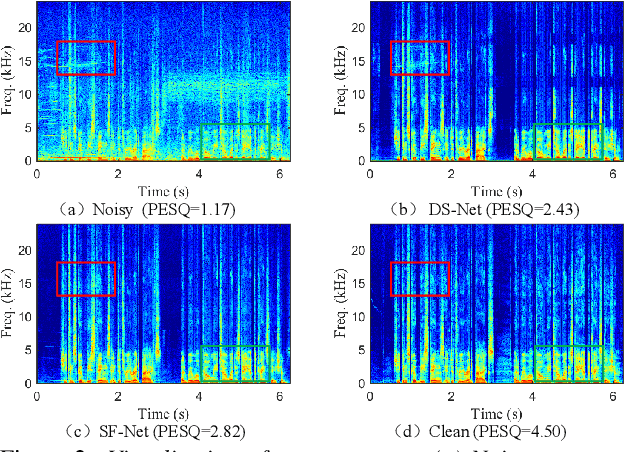
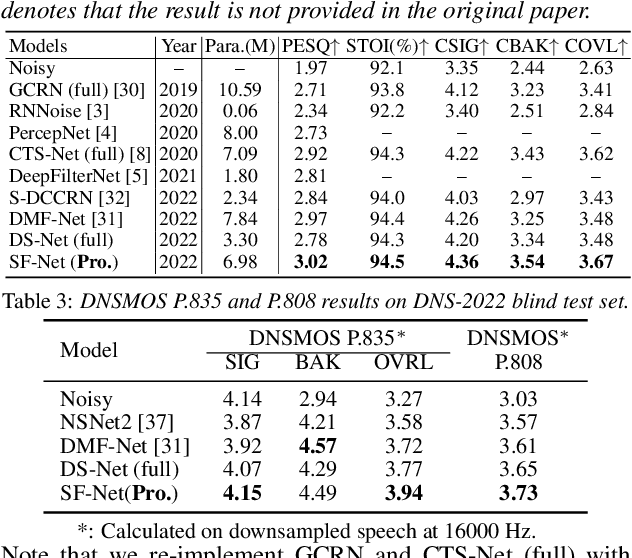
Due to the high computational complexity to model more frequency bands, it is still intractable to conduct real-time full-band speech enhancement based on deep neural networks. Recent studies typically utilize the compressed perceptually motivated features with relatively low frequency resolution to filter the full-band spectrum by one-stage networks, leading to limited speech quality improvements. In this paper, we propose a coordinated sub-band fusion network for full-band speech enhancement, which aims to recover the low- (0-8 kHz), middle- (8-16 kHz), and high-band (16-24 kHz) in a step-wise manner. Specifically, a dual-stream network is first pretrained to recover the low-band complex spectrum, and another two sub-networks are designed as the middle- and high-band noise suppressors in the magnitude-only domain. To fully capitalize on the information intercommunication, we employ a sub-band interaction module to provide external knowledge guidance across different frequency bands. Extensive experiments show that the proposed method yields consistent performance advantages over state-of-the-art full-band baselines.