 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNaturalL2S: End-to-End High-quality Multispeaker Lip-to-Speech Synthesis with Differential Digital Signal Processing
Feb 17, 2025



Recent advancements in visual speech recognition (VSR) have promoted progress in lip-to-speech synthesis, where pre-trained VSR models enhance the intelligibility of synthesized speech by providing valuable semantic information. The success achieved by cascade frameworks, which combine pseudo-VSR with pseudo-text-to-speech (TTS) or implicitly utilize the transcribed text, highlights the benefits of leveraging VSR models. However, these methods typically rely on mel-spectrograms as an intermediate representation, which may introduce a key bottleneck: the domain gap between synthetic mel-spectrograms, generated from inherently error-prone lip-to-speech mappings, and real mel-spectrograms used to train vocoders. This mismatch inevitably degrades synthesis quality. To bridge this gap, we propose Natural Lip-to-Speech (NaturalL2S), an end-to-end framework integrating acoustic inductive biases with differentiable speech generation components. Specifically, we introduce a fundamental frequency (F0) predictor to capture prosodic variations in synthesized speech. The predicted F0 then drives a Differentiable Digital Signal Processing (DDSP) synthesizer to generate a coarse signal which serves as prior information for subsequent speech synthesis. Additionally, instead of relying on a reference speaker embedding as an auxiliary input, our approach achieves satisfactory performance on speaker similarity without explicitly modelling speaker characteristics. Both objective and subjective evaluation results demonstrate that NaturalL2S can effectively enhance the quality of the synthesized speech when compared to state-of-the-art methods. Our demonstration page is accessible at https://yifan-liang.github.io/NaturalL2S/.
BSDB-Net: Band-Split Dual-Branch Network with Selective State Spaces Mechanism for Monaural Speech Enhancement
Dec 26, 2024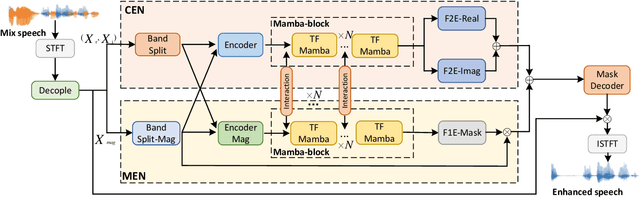
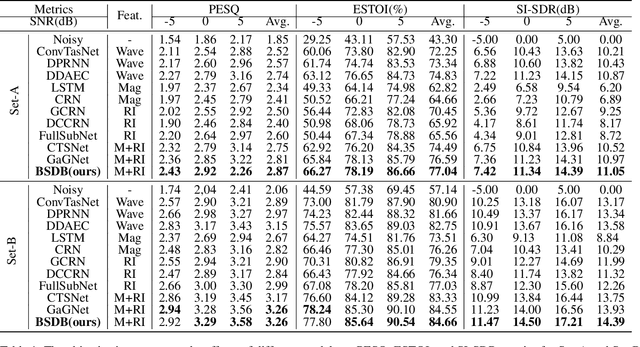
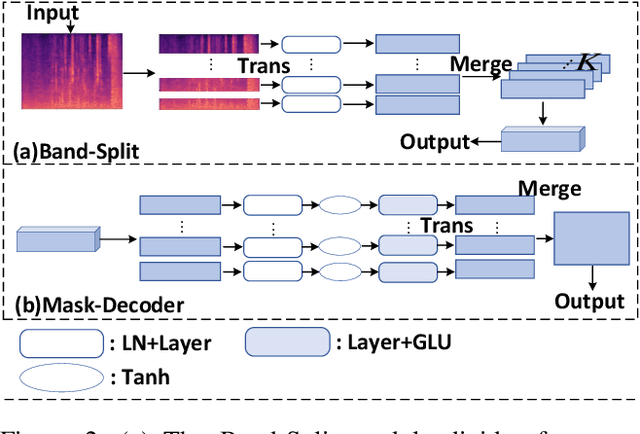
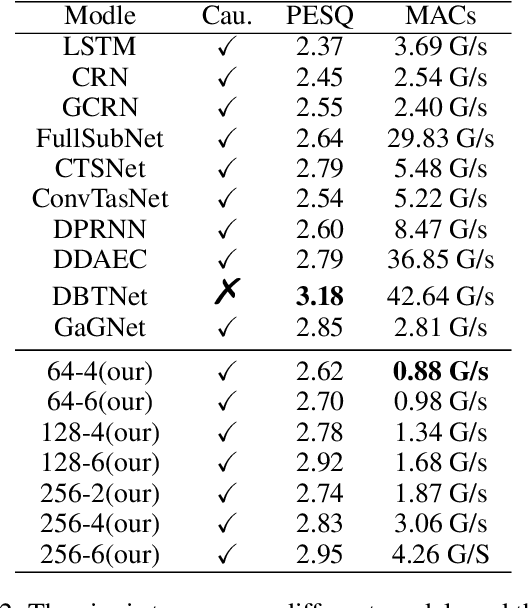
Although the complex spectrum-based speech enhancement(SE) methods have achieved significant performance, coupling amplitude and phase can lead to a compensation effect, where amplitude information is sacrificed to compensate for the phase that is harmful to SE. In addition, to further improve the performance of SE, many modules are stacked onto SE, resulting in increased model complexity that limits the application of SE. To address these problems, we proposed a dual-path network based on compressed frequency using Mamba. First, we extract amplitude and phase information through parallel dual branches. This approach leverages structured complex spectra to implicitly capture phase information and solves the compensation effect by decoupling amplitude and phase, and the network incorporates an interaction module to suppress unnecessary parts and recover missing components from the other branch. Second, to reduce network complexity, the network introduces a band-split strategy to compress the frequency dimension. To further reduce complexity while maintaining good performance, we designed a Mamba-based module that models the time and frequency dimensions under linear complexity. Finally, compared to baselines, our model achieves an average 8.3 times reduction in computational complexity while maintaining superior performance. Furthermore, it achieves a 25 times reduction in complexity compared to transformer-based models.
Array2BR: An End-to-End Noise-immune Binaural Audio Synthesis from Microphone-array Signals
Oct 08, 2024



Telepresence technology aims to provide an immersive virtual presence for remote conference applications, and it is extremely important to synthesize high-quality binaural audio signals for this aim. Because the ambient noise is often inevitable in practical application scenarios, it is highly desired that binaural audio signals without noise can be obtained from microphone-array signals directly. For this purpose, this paper proposes a new end-to-end noise-immune binaural audio synthesis framework from microphone-array signals, abbreviated as Array2BR, and experimental results show that binaural cues can be correctly mapped and noise can be well suppressed simultaneously using the proposed framework. Compared with existing methods, the proposed method achieved better performance in terms of both objective and subjective metric scores.
BAE-Net: A Low complexity and high fidelity Bandwidth-Adaptive neural network for speech super-resolution
Dec 21, 2023



Speech bandwidth extension (BWE) has demonstrated promising performance in enhancing the perceptual speech quality in real communication systems. Most existing BWE researches primarily focus on fixed upsampling ratios, disregarding the fact that the effective bandwidth of captured audio may fluctuate frequently due to various capturing devices and transmission conditions. In this paper, we propose a novel streaming adaptive bandwidth extension solution dubbed BAE-Net, which is suitable to handle the low-resolution speech with unknown and varying effective bandwidth. To address the challenges of recovering both the high-frequency magnitude and phase speech content blindly, we devise a dual-stream architecture that incorporates the magnitude inpainting and phase refinement. For potential applications on edge devices, this paper also introduces BAE-NET-lite, which is a lightweight, streaming and efficient framework. Quantitative results demonstrate the superiority of BAE-Net in terms of both performance and computational efficiency when compared with existing state-of-the-art BWE methods.
Spatial Reconstructed Local Attention Res2Net with F0 Subband for Fake Speech Detection
Aug 19, 2023The rhythm of synthetic speech is usually too smooth, which causes that the fundamental frequency (F0) of synthetic speech is significantly different from that of real speech. It is expected that the F0 feature contains the discriminative information for the fake speech detection (FSD) task. In this paper, we propose a novel F0 subband for FSD. In addition, to effectively model the F0 subband so as to improve the performance of FSD, the spatial reconstructed local attention Res2Net (SR-LA Res2Net) is proposed. Specifically, Res2Net is used as a backbone network to obtain multiscale information, and enhanced with a spatial reconstruction mechanism to avoid losing important information when the channel group is constantly superimposed. In addition, local attention is designed to make the model focus on the local information of the F0 subband. Experimental results on the ASVspoof 2019 LA dataset show that our proposed method obtains an equal error rate (EER) of 0.47% and a minimum tandem detection cost function (min t-DCF) of 0.0159, achieving the state-of-the-art performance among all of the single systems.
TaylorBeamixer: Learning Taylor-Inspired All-Neural Multi-Channel Speech Enhancement from Beam-Space Dictionary Perspective
Nov 30, 2022Despite the promising performance of existing frame-wise all-neural beamformers in the speech enhancement field, it remains unclear what the underlying mechanism exists. In this paper, we revisit the beamforming behavior from the beam-space dictionary perspective and formulate it into the learning and mixing of different beam-space components. Based on that, we propose an all-neural beamformer called TaylorBM to simulate Taylor's series expansion operation in which the 0th-order term serves as a spatial filter to conduct the beam mixing, and several high-order terms are tasked with residual noise cancellation for post-processing. The whole system is devised to work in an end-to-end manner. Experiments are conducted on the spatialized LibriSpeech corpus and results show that the proposed approach outperforms existing advanced baselines in terms of evaluation metrics.
A General Deep Learning Speech Enhancement Framework Motivated by Taylor's Theorem
Nov 30, 2022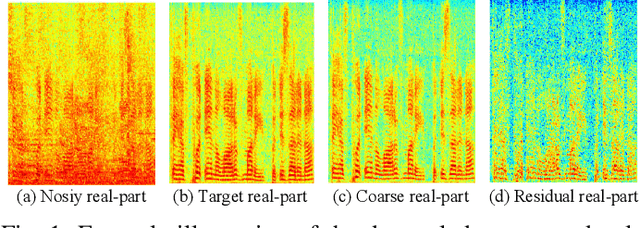
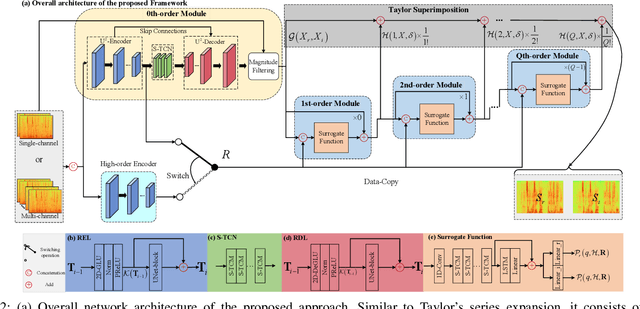
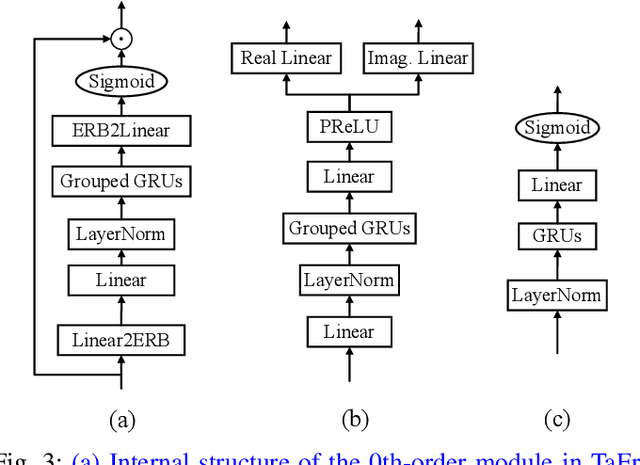
While deep neural networks greatly facilitate the proliferation of the speech enhancement field, most of the existing methods are developed following either heuristic or blind optimization criteria, which severely hampers interpretability and transparency. Inspired by Taylor's theorem, we propose a general unfolding framework for both single- and multi-channel speech enhancement tasks. Concretely, we formulate the complex spectrum recovery into the spectral magnitude mapping in the neighboring space of the noisy mixture, in which the sparse prior is introduced for phase modification in advance. Based on that, the mapping function is decomposed into the superimposition of the 0th-order and high-order polynomials in Taylor's series, where the former coarsely removes the interference in the magnitude domain and the latter progressively complements the remaining spectral detail in the complex spectrum domain. In addition, we study the relation between adjacent order term and reveal that each high-order term can be recursively estimated with its lower-order term, and each high-order term is then proposed to evaluate using a surrogate function with trainable weights, so that the whole system can be trained in an end-to-end manner. Extensive experiments are conducted on WSJ0-SI84, DNS-Challenge, Voicebank+Demand, and spatialized Librispeech datasets. Quantitative results show that the proposed approach not only yields competitive performance over existing top-performed approaches, but also enjoys decent internal transparency and flexibility.
Audio Deepfake Detection Based on a Combination of F0 Information and Real Plus Imaginary Spectrogram Features
Aug 02, 2022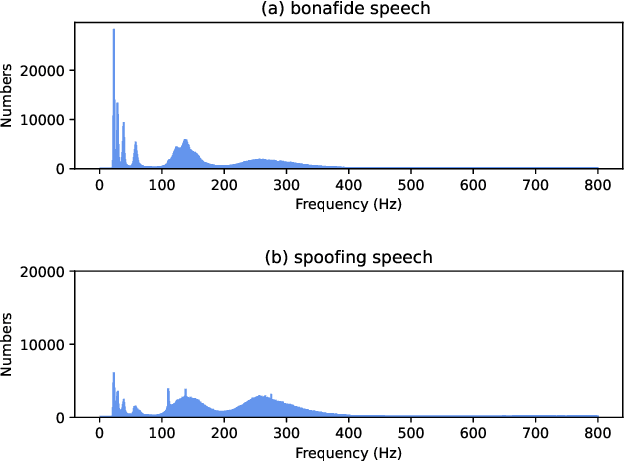


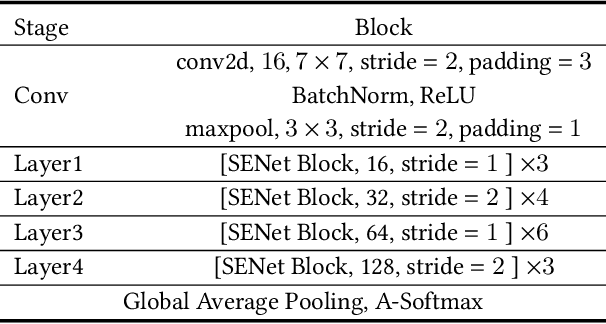
Recently, pioneer research works have proposed a large number of acoustic features (log power spectrogram, linear frequency cepstral coefficients, constant Q cepstral coefficients, etc.) for audio deepfake detection, obtaining good performance, and showing that different subbands have different contributions to audio deepfake detection. However, this lacks an explanation of the specific information in the subband, and these features also lose information such as phase. Inspired by the mechanism of synthetic speech, the fundamental frequency (F0) information is used to improve the quality of synthetic speech, while the F0 of synthetic speech is still too average, which differs significantly from that of real speech. It is expected that F0 can be used as important information to discriminate between bonafide and fake speech, while this information cannot be used directly due to the irregular distribution of F0. Insteadly, the frequency band containing most of F0 is selected as the input feature. Meanwhile, to make full use of the phase and full-band information, we also propose to use real and imaginary spectrogram features as complementary input features and model the disjoint subbands separately. Finally, the results of F0, real and imaginary spectrogram features are fused. Experimental results on the ASVspoof 2019 LA dataset show that our proposed system is very effective for the audio deepfake detection task, achieving an equivalent error rate (EER) of 0.43%, which surpasses almost all systems.
TMGAN-PLC: Audio Packet Loss Concealment using Temporal Memory Generative Adversarial Network
Jul 04, 2022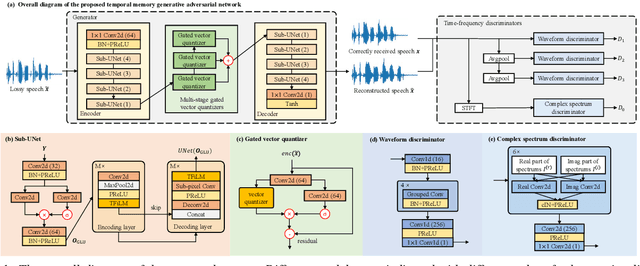
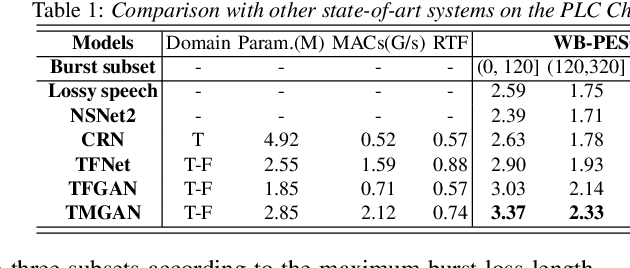
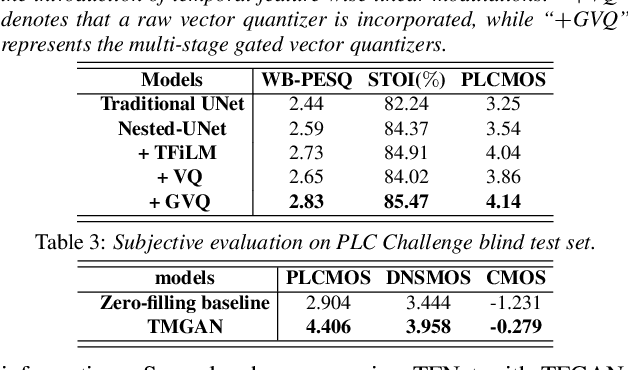
Real-time communications in packet-switched networks have become widely used in daily communication, while they inevitably suffer from network delays and data losses in constrained real-time conditions. To solve these problems, audio packet loss concealment (PLC) algorithms have been developed to mitigate voice transmission failures by reconstructing the lost information. Limited by the transmission latency and device memory, it is still intractable for PLC to accomplish high-quality voice reconstruction using a relatively small packet buffer. In this paper, we propose a temporal memory generative adversarial network for audio PLC, dubbed TMGAN-PLC, which is comprised of a novel nested-UNet generator and the time-domain/frequency-domain discriminators. Specifically, a combination of the nested-UNet and temporal feature-wise linear modulation is elaborately devised in the generator to finely adjust the intra-frame information and establish inter-frame temporal dependencies. To complement the missing speech content caused by longer loss bursts, we employ multi-stage gated vector quantizers to capture the correct content and reconstruct the near-real smooth audio. Extensive experiments on the PLC Challenge dataset demonstrate that the proposed method yields promising performance in terms of speech quality, intelligibility, and PLCMOS.
Taylor, Can You Hear Me Now? A Taylor-Unfolding Framework for Monaural Speech Enhancement
Apr 30, 2022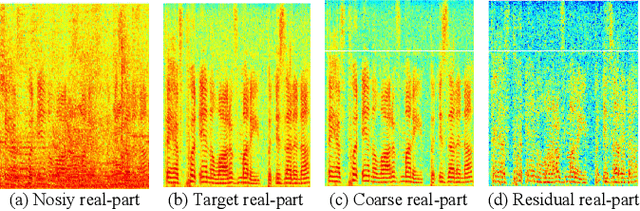

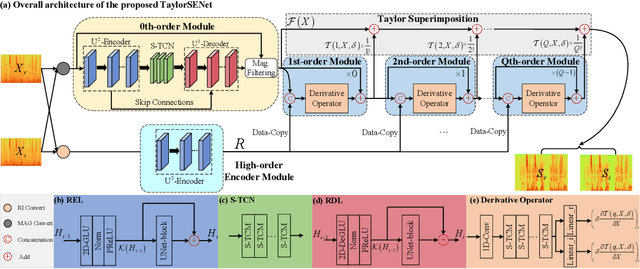

While the deep learning techniques promote the rapid development of the speech enhancement (SE) community, most schemes only pursue the performance in a black-box manner and lack adequate model interpretability. Inspired by Taylor's approximation theory, we propose an interpretable decoupling-style SE framework, which disentangles the complex spectrum recovery into two separate optimization problems \emph{i.e.}, magnitude and complex residual estimation. Specifically, serving as the 0th-order term in Taylor's series, a filter network is delicately devised to suppress the noise component only in the magnitude domain and obtain a coarse spectrum. To refine the phase distribution, we estimate the sparse complex residual, which is defined as the difference between target and coarse spectra, and measures the phase gap. In this study, we formulate the residual component as the combination of various high-order Taylor terms and propose a lightweight trainable module to replace the complicated derivative operator between adjacent terms. Finally, following Taylor's formula, we can reconstruct the target spectrum by the superimposition between 0th-order and high-order terms. Experimental results on two benchmark datasets show that our framework achieves state-of-the-art performance over previous competing baselines in various evaluation metrics. The source code is available at github.com/Andong-Lispeech/TaylorSENet.