 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDMF2Mel: A Dynamic Multiscale Fusion Network for EEG-Driven Mel Spectrogram Reconstruction
Jul 10, 2025Decoding speech from brain signals is a challenging research problem. Although existing technologies have made progress in reconstructing the mel spectrograms of auditory stimuli at the word or letter level, there remain core challenges in the precise reconstruction of minute-level continuous imagined speech: traditional models struggle to balance the efficiency of temporal dependency modeling and information retention in long-sequence decoding. To address this issue, this paper proposes the Dynamic Multiscale Fusion Network (DMF2Mel), which consists of four core components: the Dynamic Contrastive Feature Aggregation Module (DC-FAM), the Hierarchical Attention-Guided Multi-Scale Network (HAMS-Net), the SplineMap attention mechanism, and the bidirectional state space module (convMamba). Specifically, the DC-FAM separates speech-related "foreground features" from noisy "background features" through local convolution and global attention mechanisms, effectively suppressing interference and enhancing the representation of transient signals. HAMS-Net, based on the U-Net framework,achieves cross-scale fusion of high-level semantics and low-level details. The SplineMap attention mechanism integrates the Adaptive Gated Kolmogorov-Arnold Network (AGKAN) to combine global context modeling with spline-based local fitting. The convMamba captures long-range temporal dependencies with linear complexity and enhances nonlinear dynamic modeling capabilities. Results on the SparrKULee dataset show that DMF2Mel achieves a Pearson correlation coefficient of 0.074 in mel spectrogram reconstruction for known subjects (a 48% improvement over the baseline) and 0.048 for unknown subjects (a 35% improvement over the baseline).Code is available at: https://github.com/fchest/DMF2Mel.
MHANet: Multi-scale Hybrid Attention Network for Auditory Attention Detection
May 21, 2025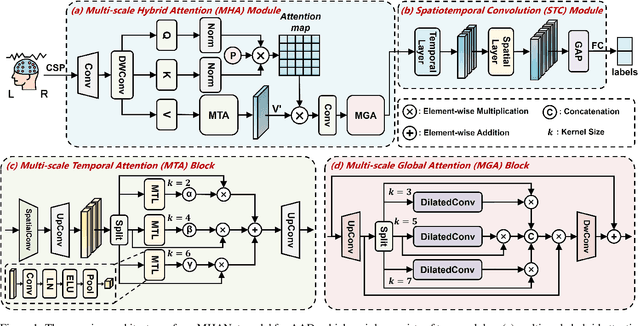
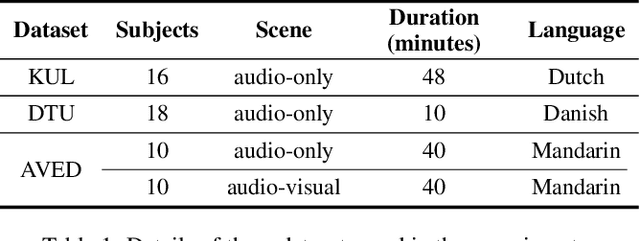
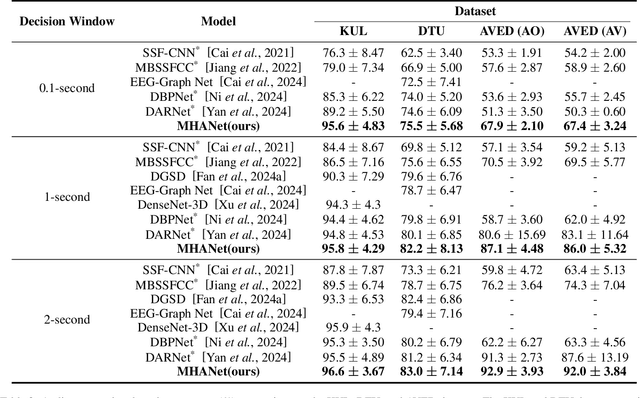
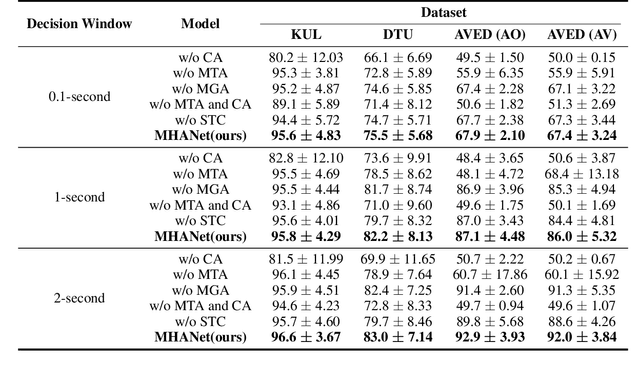
Auditory attention detection (AAD) aims to detect the target speaker in a multi-talker environment from brain signals, such as electroencephalography (EEG), which has made great progress. However, most AAD methods solely utilize attention mechanisms sequentially and overlook valuable multi-scale contextual information within EEG signals, limiting their ability to capture long-short range spatiotemporal dependencies simultaneously. To address these issues, this paper proposes a multi-scale hybrid attention network (MHANet) for AAD, which consists of the multi-scale hybrid attention (MHA) module and the spatiotemporal convolution (STC) module. Specifically, MHA combines channel attention and multi-scale temporal and global attention mechanisms. This effectively extracts multi-scale temporal patterns within EEG signals and captures long-short range spatiotemporal dependencies simultaneously. To further improve the performance of AAD, STC utilizes temporal and spatial convolutions to aggregate expressive spatiotemporal representations. Experimental results show that the proposed MHANet achieves state-of-the-art performance with fewer trainable parameters across three datasets, 3 times lower than that of the most advanced model. Code is available at: https://github.com/fchest/MHANet.
ListenNet: A Lightweight Spatio-Temporal Enhancement Nested Network for Auditory Attention Detection
May 15, 2025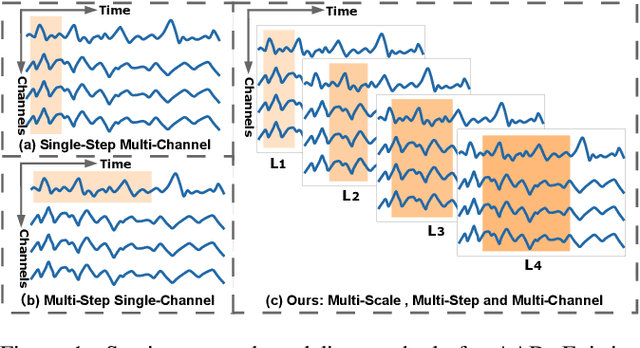
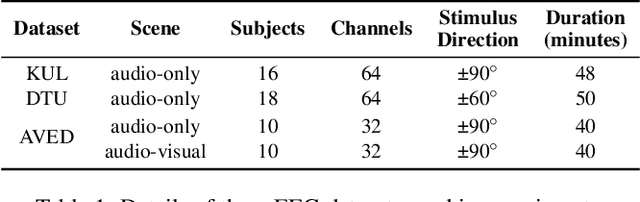
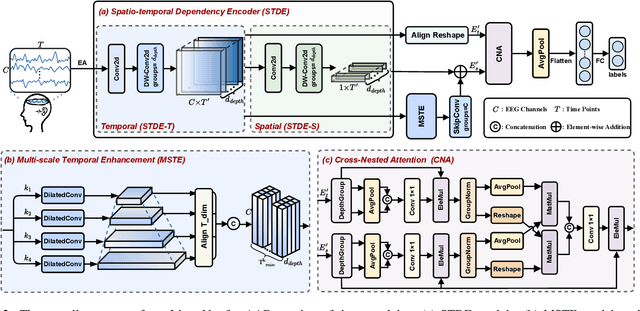
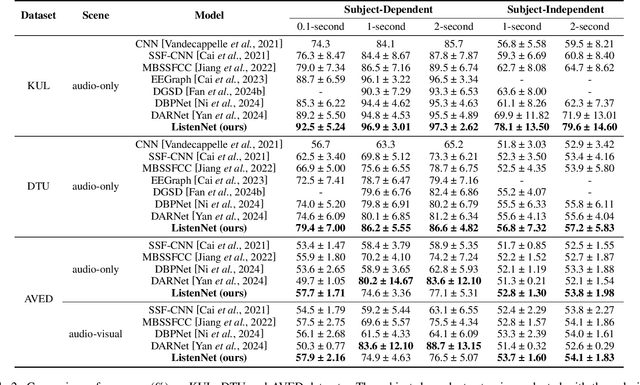
Auditory attention detection (AAD) aims to identify the direction of the attended speaker in multi-speaker environments from brain signals, such as Electroencephalography (EEG) signals. However, existing EEG-based AAD methods overlook the spatio-temporal dependencies of EEG signals, limiting their decoding and generalization abilities. To address these issues, this paper proposes a Lightweight Spatio-Temporal Enhancement Nested Network (ListenNet) for AAD. The ListenNet has three key components: Spatio-temporal Dependency Encoder (STDE), Multi-scale Temporal Enhancement (MSTE), and Cross-Nested Attention (CNA). The STDE reconstructs dependencies between consecutive time windows across channels, improving the robustness of dynamic pattern extraction. The MSTE captures temporal features at multiple scales to represent both fine-grained and long-range temporal patterns. In addition, the CNA integrates hierarchical features more effectively through novel dynamic attention mechanisms to capture deep spatio-temporal correlations. Experimental results on three public datasets demonstrate the superiority of ListenNet over state-of-the-art methods in both subject-dependent and challenging subject-independent settings, while reducing the trainable parameter count by approximately 7 times. Code is available at:https://github.com/fchest/ListenNet.
Improved Feature Extraction Network for Neuro-Oriented Target Speaker Extraction
Jan 03, 2025



The recent rapid development of auditory attention decoding (AAD) offers the possibility of using electroencephalography (EEG) as auxiliary information for target speaker extraction. However, effectively modeling long sequences of speech and resolving the identity of the target speaker from EEG signals remains a major challenge. In this paper, an improved feature extraction network (IFENet) is proposed for neuro-oriented target speaker extraction, which mainly consists of a speech encoder with dual-path Mamba and an EEG encoder with Kolmogorov-Arnold Networks (KAN). We propose SpeechBiMamba, which makes use of dual-path Mamba in modeling local and global speech sequences to extract speech features. In addition, we propose EEGKAN to effectively extract EEG features that are closely related to the auditory stimuli and locate the target speaker through the subject's attention information. Experiments on the KUL and AVED datasets show that IFENet outperforms the state-of-the-art model, achieving 36\% and 29\% relative improvements in terms of scale-invariant signal-to-distortion ratio (SI-SDR) under an open evaluation condition.
BSDB-Net: Band-Split Dual-Branch Network with Selective State Spaces Mechanism for Monaural Speech Enhancement
Dec 26, 2024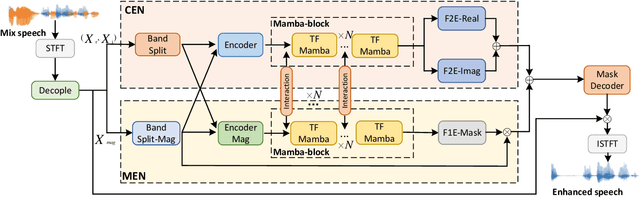
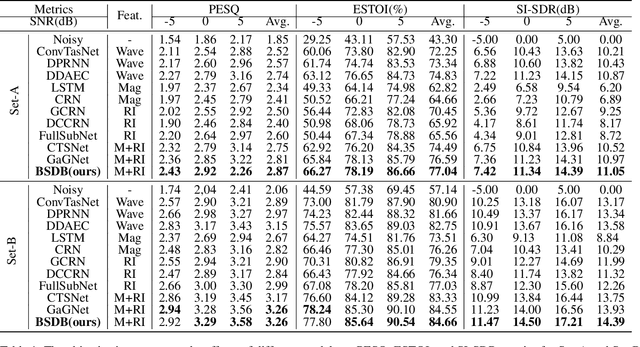
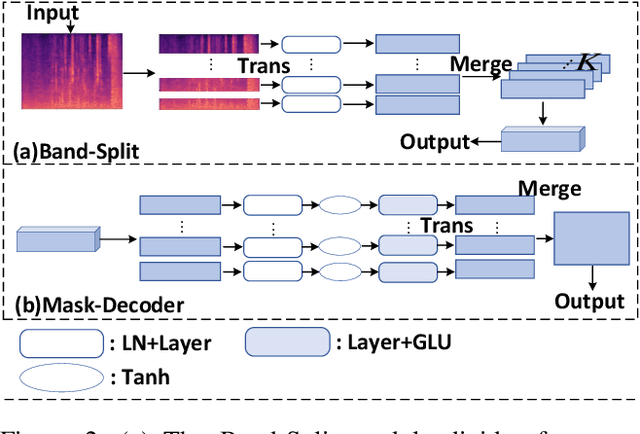
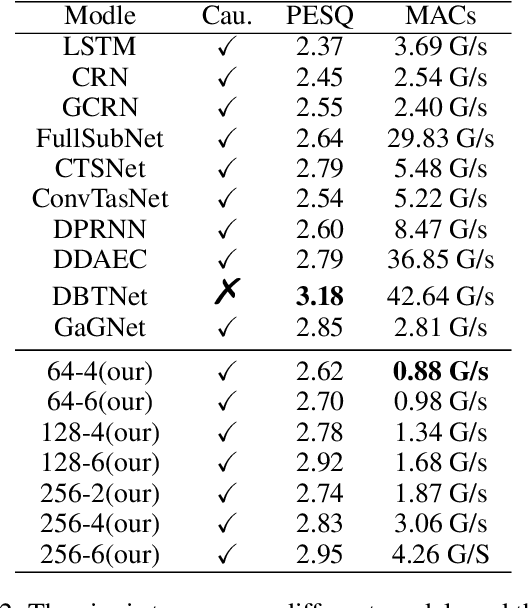
Although the complex spectrum-based speech enhancement(SE) methods have achieved significant performance, coupling amplitude and phase can lead to a compensation effect, where amplitude information is sacrificed to compensate for the phase that is harmful to SE. In addition, to further improve the performance of SE, many modules are stacked onto SE, resulting in increased model complexity that limits the application of SE. To address these problems, we proposed a dual-path network based on compressed frequency using Mamba. First, we extract amplitude and phase information through parallel dual branches. This approach leverages structured complex spectra to implicitly capture phase information and solves the compensation effect by decoupling amplitude and phase, and the network incorporates an interaction module to suppress unnecessary parts and recover missing components from the other branch. Second, to reduce network complexity, the network introduces a band-split strategy to compress the frequency dimension. To further reduce complexity while maintaining good performance, we designed a Mamba-based module that models the time and frequency dimensions under linear complexity. Finally, compared to baselines, our model achieves an average 8.3 times reduction in computational complexity while maintaining superior performance. Furthermore, it achieves a 25 times reduction in complexity compared to transformer-based models.
Region-Based Optimization in Continual Learning for Audio Deepfake Detection
Dec 16, 2024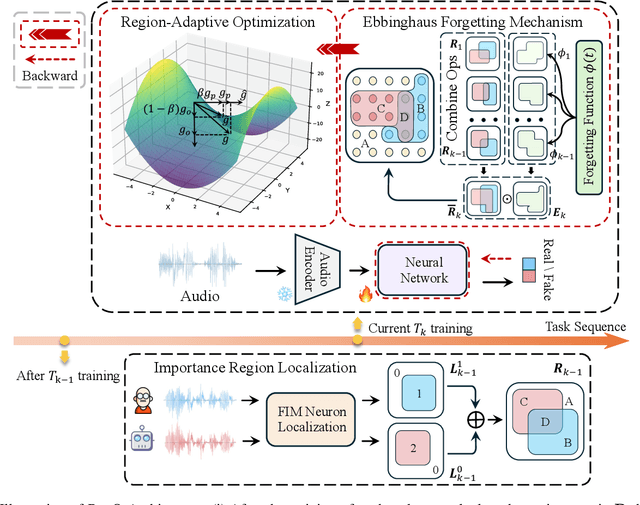
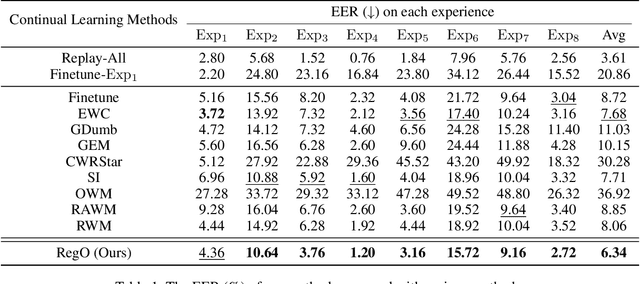
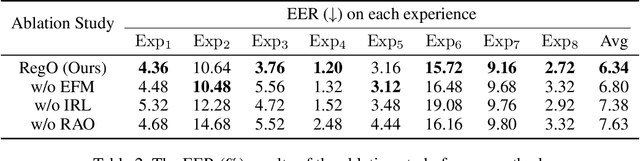
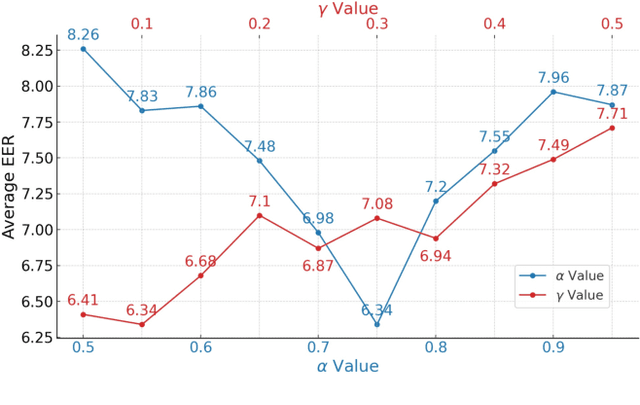
Rapid advancements in speech synthesis and voice conversion bring convenience but also new security risks, creating an urgent need for effective audio deepfake detection. Although current models perform well, their effectiveness diminishes when confronted with the diverse and evolving nature of real-world deepfakes. To address this issue, we propose a continual learning method named Region-Based Optimization (RegO) for audio deepfake detection. Specifically, we use the Fisher information matrix to measure important neuron regions for real and fake audio detection, dividing them into four regions. First, we directly fine-tune the less important regions to quickly adapt to new tasks. Next, we apply gradient optimization in parallel for regions important only to real audio detection, and in orthogonal directions for regions important only to fake audio detection. For regions that are important to both, we use sample proportion-based adaptive gradient optimization. This region-adaptive optimization ensures an appropriate trade-off between memory stability and learning plasticity. Additionally, to address the increase of redundant neurons from old tasks, we further introduce the Ebbinghaus forgetting mechanism to release them, thereby promoting the capability of the model to learn more generalized discriminative features. Experimental results show our method achieves a 21.3% improvement in EER over the state-of-the-art continual learning approach RWM for audio deepfake detection. Moreover, the effectiveness of RegO extends beyond the audio deepfake detection domain, showing potential significance in other tasks, such as image recognition. The code is available at https://github.com/cyjie429/RegO
Mitigating Gender Bias in Code Large Language Models via Model Editing
Oct 10, 2024In recent years, with the maturation of large language model (LLM) technology and the emergence of high-quality programming code datasets, researchers have become increasingly confident in addressing the challenges of program synthesis automatically. However, since most of the training samples for LLMs are unscreened, it is inevitable that LLMs' performance may not align with real-world scenarios, leading to the presence of social bias. To evaluate and quantify the gender bias in code LLMs, we propose a dataset named CodeGenBias (Gender Bias in the Code Generation) and an evaluation metric called FB-Score (Factual Bias Score) based on the actual gender distribution of correlative professions. With the help of CodeGenBias and FB-Score, we evaluate and analyze the gender bias in eight mainstream Code LLMs. Previous work has demonstrated that model editing methods that perform well in knowledge editing have the potential to mitigate social bias in LLMs. Therefore, we develop a model editing approach named MG-Editing (Multi-Granularity model Editing), which includes the locating and editing phases. Our model editing method MG-Editing can be applied at five different levels of model parameter granularity: full parameters level, layer level, module level, row level, and neuron level. Extensive experiments not only demonstrate that our MG-Editing can effectively mitigate the gender bias in code LLMs while maintaining their general code generation capabilities, but also showcase its excellent generalization. At the same time, the experimental results show that, considering both the gender bias of the model and its general code generation capability, MG-Editing is most effective when applied at the row and neuron levels of granularity.
UNO Arena for Evaluating Sequential Decision-Making Capability of Large Language Models
Jun 24, 2024Sequential decision-making refers to algorithms that take into account the dynamics of the environment, where early decisions affect subsequent decisions. With large language models (LLMs) demonstrating powerful capabilities between tasks, we can't help but ask: Can Current LLMs Effectively Make Sequential Decisions? In order to answer this question, we propose the UNO Arena based on the card game UNO to evaluate the sequential decision-making capability of LLMs and explain in detail why we choose UNO. In UNO Arena, We evaluate the sequential decision-making capability of LLMs dynamically with novel metrics based Monte Carlo methods. We set up random players, DQN-based reinforcement learning players, and LLM players (e.g. GPT-4, Gemini-pro) for comparison testing. Furthermore, in order to improve the sequential decision-making capability of LLMs, we propose the TUTRI player, which can involves having LLMs reflect their own actions wtih the summary of game history and the game strategy. Numerous experiments demonstrate that the TUTRI player achieves a notable breakthrough in the performance of sequential decision-making compared to the vanilla LLM player.
Pruning via Merging: Compressing LLMs via Manifold Alignment Based Layer Merging
Jun 24, 2024While large language models (LLMs) excel in many domains, their complexity and scale challenge deployment in resource-limited environments. Current compression techniques, such as parameter pruning, often fail to effectively utilize the knowledge from pruned parameters. To address these challenges, we propose Manifold-Based Knowledge Alignment and Layer Merging Compression (MKA), a novel approach that uses manifold learning and the Normalized Pairwise Information Bottleneck (NPIB) measure to merge similar layers, reducing model size while preserving essential performance. We evaluate MKA on multiple benchmark datasets and various LLMs. Our findings show that MKA not only preserves model performance but also achieves substantial compression ratios, outperforming traditional pruning methods. Moreover, when coupled with quantization, MKA delivers even greater compression. Specifically, on the MMLU dataset using the Llama3-8B model, MKA achieves a compression ratio of 43.75% with a minimal performance decrease of only 2.82\%. The proposed MKA method offers a resource-efficient and performance-preserving model compression technique for LLMs.
Frequency-mix Knowledge Distillation for Fake Speech Detection
Jun 14, 2024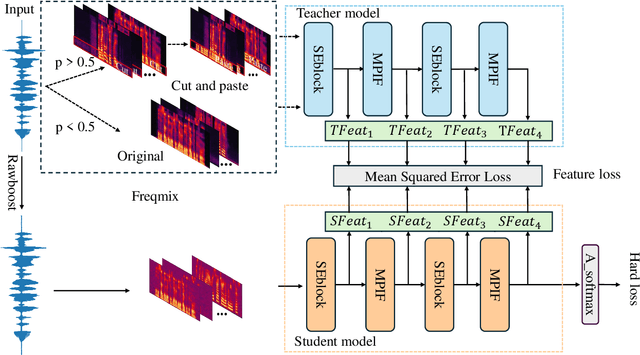
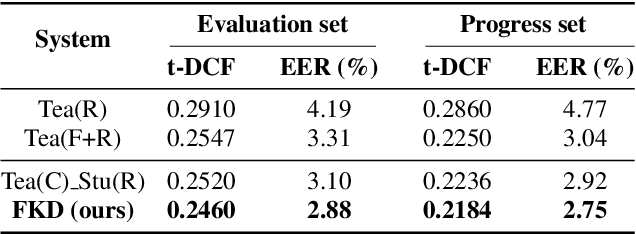
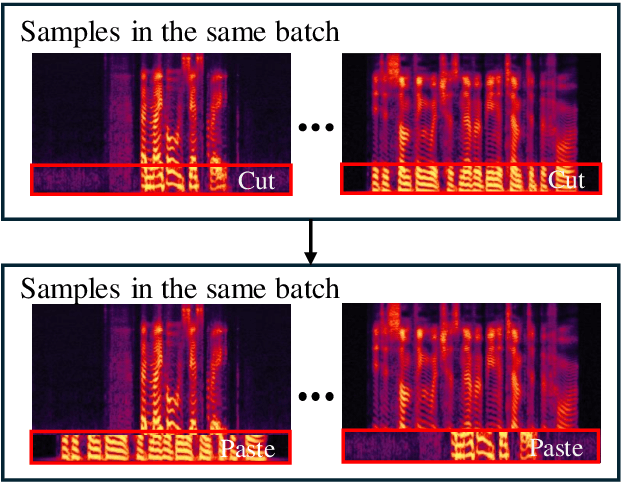
In the telephony scenarios, the fake speech detection (FSD) task to combat speech spoofing attacks is challenging. Data augmentation (DA) methods are considered effective means to address the FSD task in telephony scenarios, typically divided into time domain and frequency domain stages. While each has its advantages, both can result in information loss. To tackle this issue, we propose a novel DA method, Frequency-mix (Freqmix), and introduce the Freqmix knowledge distillation (FKD) to enhance model information extraction and generalization abilities. Specifically, we use Freqmix-enhanced data as input for the teacher model, while the student model's input undergoes time-domain DA method. We use a multi-level feature distillation approach to restore information and improve the model's generalization capabilities. Our approach achieves state-of-the-art results on ASVspoof 2021 LA dataset, showing a 31\% improvement over baseline and performs competitively on ASVspoof 2021 DF dataset.