 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Training for Discrete Token LLM based TTS System
Jun 08, 2026Recent state-of-the-art (SOTA) text-to-speech (TTS) systems typically adopt a cascaded pipeline consisting of a speech tokenizer, an autoregressive large language model (LLM), and a diffusion based flow-matching (FM) model, with these components trained independently. In this paper, we propose a fully end-to-end (E2E) optimization framework that unifies the training of the speech tokenizer, LLM, FM model, and an additional reward model (RM). Specifically, we first jointly optimize the tokenizer using multi-task objectives derived from reconstruction for FM, next-token prediction for LLM, and multi recognition task for RM. This joint training encourages the discrete speech token space to capture acoustically and semantically salient information that is better tailored to TTS. We then further optimize the LLM using downstream reconstruction and recognition by FM and RM, which reduces inference-time mismatch and steers the LLM toward more preferred generations. Experimental results show that our E2E framework consistently outperforms cascaded baselines. On the Seed-TTS-Eval benchmark, our system achieves a word error rate (WER) of 0.78% and 1.56%, a new SOTA result with a 0.6B-parameter LLM and 0.5B-parameter FM model. These results validate that holistic E2E optimization is critical for improving discrete-token-based TTS systems with a much simpler training pipeline.
Edit Content, Preserve Acoustics: Imperceptible Text-Based Speech Editing via Self-Consistency Rewards
Jan 31, 2026Imperceptible text-based speech editing allows users to modify spoken content by altering the transcript. It demands that modified segments fuse seamlessly with the surrounding context. Prevalent methods operating in the acoustic space suffer from inherent content-style entanglement, leading to generation instability and boundary artifacts. In this paper, we propose a novel framework grounded in the principle of "Edit Content, Preserve Acoustics". Our approach relies on two core components: (1) Structural Foundations, which decouples editing into a stable semantic space while delegating acoustic reconstruction to a Flow Matching decoder; and (2) Perceptual Alignment, which employs a novel Self-Consistency Rewards Group Relative Policy Optimization. By leveraging a pre-trained Text-to-Speech model as an implicit critic -- complemented by strict intelligibility and duration constraints -- we effectively align the edited semantic token sequence with the original context. Empirical evaluations demonstrate that our method significantly outperforms state-of-the-art autoregressive and non-autoregressive baselines, achieving superior intelligibility, robustness, and perceptual quality.
OV-InstructTTS: Towards Open-Vocabulary Instruct Text-to-Speech
Jan 04, 2026Instruct Text-to-Speech (InstructTTS) leverages natural language descriptions as style prompts to guide speech synthesis. However, existing InstructTTS methods mainly rely on a direct combination of audio-related labels or their diverse rephrasings, making it difficult to handle flexible, high-level instructions. Such rigid control is insufficient for users such as content creators who wish to steer generation with descriptive instructions. To address these constraints, we introduce OV-InstructTTS, a new paradigm for open-vocabulary InstructTTS. We propose a comprehensive solution comprising a newly curated dataset, OV-Speech, and a novel reasoning-driven framework. The OV-Speech dataset pairs speech with open-vocabulary instructions, each augmented with a reasoning process that connects high-level instructions to acoustic features. The reasoning-driven framework infers emotional, acoustic, and paralinguistic information from open-vocabulary instructions before synthesizing speech. Evaluations show that this reasoning-driven approach significantly improves instruction-following fidelity and speech expressiveness. We believe this work can inspire the next user-friendly InstructTTS systems with stronger generalization and real-world applicability. The dataset and demos are publicly available on our project page.
Step-Audio 2 Technical Report
Jul 24, 2025



This paper presents Step-Audio 2, an end-to-end multi-modal large language model designed for industry-strength audio understanding and speech conversation. By integrating a latent audio encoder and reasoning-centric reinforcement learning (RL), Step-Audio 2 achieves promising performance in automatic speech recognition (ASR) and audio understanding. To facilitate genuine end-to-end speech conversation, Step-Audio 2 incorporates the generation of discrete audio tokens into language modeling, significantly enhancing its responsiveness to paralinguistic information such as speaking styles and emotions. To effectively leverage the rich textual and acoustic knowledge in real-world data, Step-Audio 2 integrates retrieval-augmented generation (RAG) and is able to call external tools such as web search to mitigate hallucination and audio search to switch timbres. Trained on millions of hours of speech and audio data, Step-Audio 2 delivers intelligence and expressiveness across diverse conversational scenarios. Evaluation results demonstrate that Step-Audio 2 achieves state-of-the-art performance on various audio understanding and conversational benchmarks compared to other open-source and commercial solutions. Please visit https://github.com/stepfun-ai/Step-Audio2 for more information.
Mitigating Audiovisual Mismatch in Visual-Guide Audio Captioning
May 28, 2025Current vision-guided audio captioning systems frequently fail to address audiovisual misalignment in real-world scenarios, such as dubbed content or off-screen sounds. To bridge this critical gap, we present an entropy-aware gated fusion framework that dynamically modulates visual information flow through cross-modal uncertainty quantification. Our novel approach employs attention entropy analysis in cross-attention layers to automatically identify and suppress misleading visual cues during modal fusion. Complementing this architecture, we develop a batch-wise audiovisual shuffling technique that generates synthetic mismatched training pairs, greatly enhancing model resilience against alignment noise. Evaluations on the AudioCaps benchmark demonstrate our system's superior performance over existing baselines, especially in mismatched modality scenarios. Furthermore, our solution demonstrates an approximately 6x improvement in inference speed compared to the baseline.
Information-Theoretic Complementary Prompts for Improved Continual Text Classification
May 27, 2025Continual Text Classification (CTC) aims to continuously classify new text data over time while minimizing catastrophic forgetting of previously acquired knowledge. However, existing methods often focus on task-specific knowledge, overlooking the importance of shared, task-agnostic knowledge. Inspired by the complementary learning systems theory, which posits that humans learn continually through the interaction of two systems -- the hippocampus, responsible for forming distinct representations of specific experiences, and the neocortex, which extracts more general and transferable representations from past experiences -- we introduce Information-Theoretic Complementary Prompts (InfoComp), a novel approach for CTC. InfoComp explicitly learns two distinct prompt spaces: P(rivate)-Prompt and S(hared)-Prompt. These respectively encode task-specific and task-invariant knowledge, enabling models to sequentially learn classification tasks without relying on data replay. To promote more informative prompt learning, InfoComp uses an information-theoretic framework that maximizes mutual information between different parameters (or encoded representations). Within this framework, we design two novel loss functions: (1) to strengthen the accumulation of task-specific knowledge in P-Prompt, effectively mitigating catastrophic forgetting, and (2) to enhance the retention of task-invariant knowledge in S-Prompt, improving forward knowledge transfer. Extensive experiments on diverse CTC benchmarks show that our approach outperforms previous state-of-the-art methods.
Hearing from Silence: Reasoning Audio Descriptions from Silent Videos via Vision-Language Model
May 19, 2025Humans can intuitively infer sounds from silent videos, but whether multimodal large language models can perform modal-mismatch reasoning without accessing target modalities remains relatively unexplored. Current text-assisted-video-to-audio (VT2A) methods excel in video foley tasks but struggle to acquire audio descriptions during inference. We introduce the task of Reasoning Audio Descriptions from Silent Videos (SVAD) to address this challenge and investigate vision-language models' (VLMs) capabilities on this task. To further enhance the VLMs' reasoning capacity for the SVAD task, we construct a CoT-AudioCaps dataset and propose a Chain-of-Thought-based supervised fine-tuning strategy. Experiments on SVAD and subsequent VT2A tasks demonstrate our method's effectiveness in two key aspects: significantly improving VLMs' modal-mismatch reasoning for SVAD and effectively addressing the challenge of acquiring audio descriptions during VT2A inference.
$\mathcal{A}LLM4ADD$: Unlocking the Capabilities of Audio Large Language Models for Audio Deepfake Detection
May 16, 2025

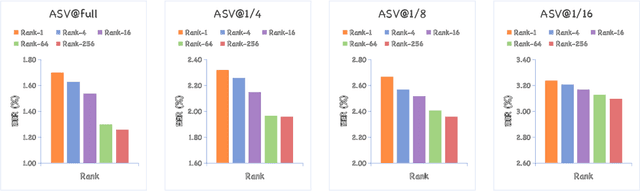
Audio deepfake detection (ADD) has grown increasingly important due to the rise of high-fidelity audio generative models and their potential for misuse. Given that audio large language models (ALLMs) have made significant progress in various audio processing tasks, a heuristic question arises: Can ALLMs be leveraged to solve ADD?. In this paper, we first conduct a comprehensive zero-shot evaluation of ALLMs on ADD, revealing their ineffectiveness in detecting fake audio. To enhance their performance, we propose $\mathcal{A}LLM4ADD$, an ALLM-driven framework for ADD. Specifically, we reformulate ADD task as an audio question answering problem, prompting the model with the question: "Is this audio fake or real?". We then perform supervised fine-tuning to enable the ALLM to assess the authenticity of query audio. Extensive experiments are conducted to demonstrate that our ALLM-based method can achieve superior performance in fake audio detection, particularly in data-scarce scenarios. As a pioneering study, we anticipate that this work will inspire the research community to leverage ALLMs to develop more effective ADD systems.
Region-Based Optimization in Continual Learning for Audio Deepfake Detection
Dec 16, 2024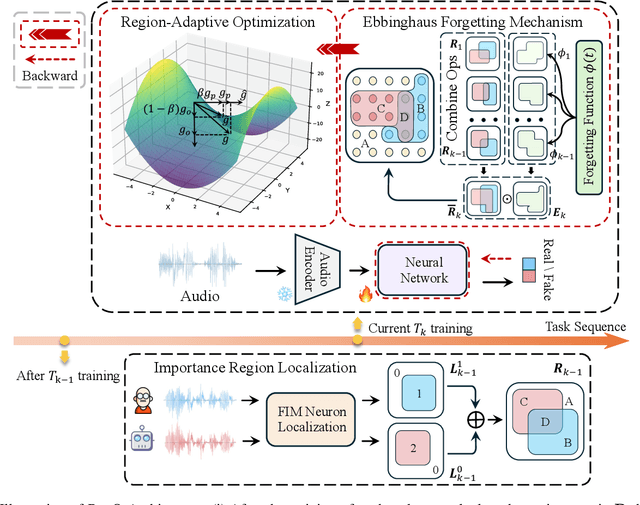
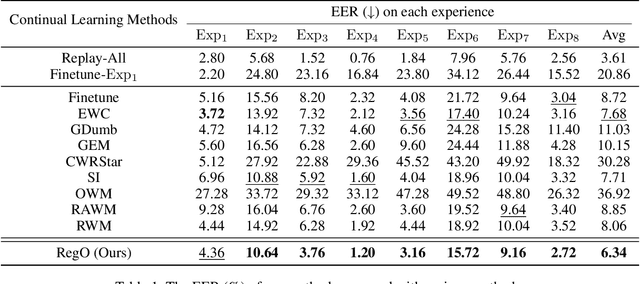
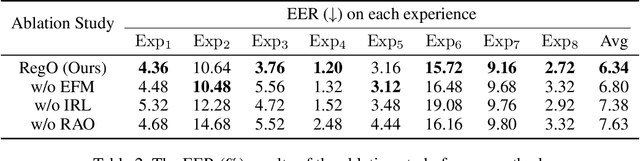
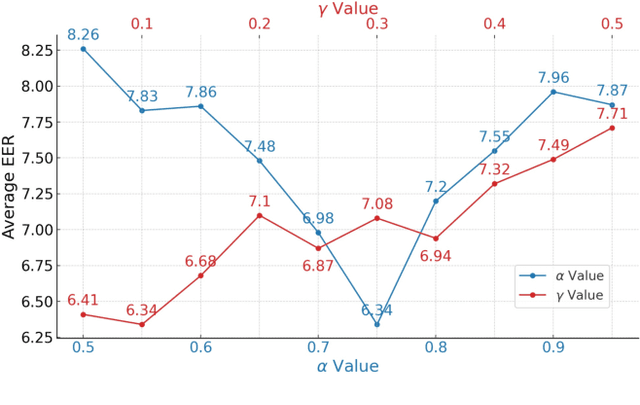
Rapid advancements in speech synthesis and voice conversion bring convenience but also new security risks, creating an urgent need for effective audio deepfake detection. Although current models perform well, their effectiveness diminishes when confronted with the diverse and evolving nature of real-world deepfakes. To address this issue, we propose a continual learning method named Region-Based Optimization (RegO) for audio deepfake detection. Specifically, we use the Fisher information matrix to measure important neuron regions for real and fake audio detection, dividing them into four regions. First, we directly fine-tune the less important regions to quickly adapt to new tasks. Next, we apply gradient optimization in parallel for regions important only to real audio detection, and in orthogonal directions for regions important only to fake audio detection. For regions that are important to both, we use sample proportion-based adaptive gradient optimization. This region-adaptive optimization ensures an appropriate trade-off between memory stability and learning plasticity. Additionally, to address the increase of redundant neurons from old tasks, we further introduce the Ebbinghaus forgetting mechanism to release them, thereby promoting the capability of the model to learn more generalized discriminative features. Experimental results show our method achieves a 21.3% improvement in EER over the state-of-the-art continual learning approach RWM for audio deepfake detection. Moreover, the effectiveness of RegO extends beyond the audio deepfake detection domain, showing potential significance in other tasks, such as image recognition. The code is available at https://github.com/cyjie429/RegO
Is FISHER All You Need in The Multi-AUV Underwater Target Tracking Task?
Dec 05, 2024



It is significant to employ multiple autonomous underwater vehicles (AUVs) to execute the underwater target tracking task collaboratively. However, it's pretty challenging to meet various prerequisites utilizing traditional control methods. Therefore, we propose an effective two-stage learning from demonstrations training framework, FISHER, to highlight the adaptability of reinforcement learning (RL) methods in the multi-AUV underwater target tracking task, while addressing its limitations such as extensive requirements for environmental interactions and the challenges in designing reward functions. The first stage utilizes imitation learning (IL) to realize policy improvement and generate offline datasets. To be specific, we introduce multi-agent discriminator-actor-critic based on improvements of the generative adversarial IL algorithm and multi-agent IL optimization objective derived from the Nash equilibrium condition. Then in the second stage, we develop multi-agent independent generalized decision transformer, which analyzes the latent representation to match the future states of high-quality samples rather than reward function, attaining further enhanced policies capable of handling various scenarios. Besides, we propose a simulation to simulation demonstration generation procedure to facilitate the generation of expert demonstrations in underwater environments, which capitalizes on traditional control methods and can easily accomplish the domain transfer to obtain demonstrations. Extensive simulation experiments from multiple scenarios showcase that FISHER possesses strong stability, multi-task performance and capability of generalization.