 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFireRed-OCR Technical Report
Mar 02, 2026We present FireRed-OCR, a systematic framework to specialize general VLMs into high-performance OCR models. Large Vision-Language Models (VLMs) have demonstrated impressive general capabilities but frequently suffer from ``structural hallucination'' when processing complex documents, limiting their utility in industrial OCR applications. In this paper, we introduce FireRed-OCR, a novel framework designed to transform general-purpose VLMs (based on Qwen3-VL) into pixel-precise structural document parsing experts. To address the scarcity of high-quality structured data, we construct a ``Geometry + Semantics'' Data Factory. Unlike traditional random sampling, our pipeline leverages geometric feature clustering and multi-dimensional tagging to synthesize and curate a highly balanced dataset, effectively handling long-tail layouts and rare document types. Furthermore, we propose a Three-Stage Progressive Training strategy that guides the model from pixel-level perception to logical structure generation. This curriculum includes: (1) Multi-task Pre-alignment to ground the model's understanding of document structure; (2) Specialized SFT for standardizing full-image Markdown output; and (3) Format-Constrained Group Relative Policy Optimization (GRPO), which utilizes reinforcement learning to enforce strict syntactic validity and structural integrity (e.g., table closure, formula syntax). Extensive evaluations on OmniDocBench v1.5 demonstrate that FireRed-OCR achieves state-of-the-art performance with an overall score of 92.94\%, significantly outperforming strong baselines such as DeepSeek-OCR 2 and OCRVerse across text, formula, table, and reading order metrics. We open-source our code and model weights to facilitate the ``General VLM to Specialized Structural Expert'' paradigm.
Code over Words: Overcoming Semantic Inertia via Code-Grounded Reasoning
Jan 26, 2026LLMs struggle with Semantic Inertia: the inability to inhibit pre-trained priors (e.g., "Lava is Dangerous") when dynamic, in-context rules contradict them. We probe this phenomenon using Baba Is You, where physical laws are mutable text rules, enabling precise evaluation of models' ability to override learned priors when rules change. We quantatively observe that larger models can exhibit inverse scaling: they perform worse than smaller models when natural language reasoning requires suppressing pre-trained associations (e.g., accepting "Lava is Safe"). Our analysis attributes this to natural language encoding, which entangles descriptive semantics and logical rules, leading to persistent hallucinations of familiar physics despite explicit contradictory rules. Here we show that representing dynamics as executable code, rather than descriptive text, reverses this trend and enables effective prior inhibition. We introduce Code-Grounded Vistas (LCV), which fine-tunes models on counterfactual pairs and identifies states with contradictory rules, thereby forcing attention to logical constraints rather than visual semantics. This training-time approach outperforms expensive inference-time search methods in both efficiency and accuracy. Our results demonstrate that representation fundamentally determines whether scaling improves or impairs contextual reasoning. This challenges the assumption that larger models are universally better, with implications for domains that require dynamic overriding of learned priors.
Hearing from Silence: Reasoning Audio Descriptions from Silent Videos via Vision-Language Model
May 19, 2025Humans can intuitively infer sounds from silent videos, but whether multimodal large language models can perform modal-mismatch reasoning without accessing target modalities remains relatively unexplored. Current text-assisted-video-to-audio (VT2A) methods excel in video foley tasks but struggle to acquire audio descriptions during inference. We introduce the task of Reasoning Audio Descriptions from Silent Videos (SVAD) to address this challenge and investigate vision-language models' (VLMs) capabilities on this task. To further enhance the VLMs' reasoning capacity for the SVAD task, we construct a CoT-AudioCaps dataset and propose a Chain-of-Thought-based supervised fine-tuning strategy. Experiments on SVAD and subsequent VT2A tasks demonstrate our method's effectiveness in two key aspects: significantly improving VLMs' modal-mismatch reasoning for SVAD and effectively addressing the challenge of acquiring audio descriptions during VT2A inference.
Learning to Plan with Personalized Preferences
Feb 02, 2025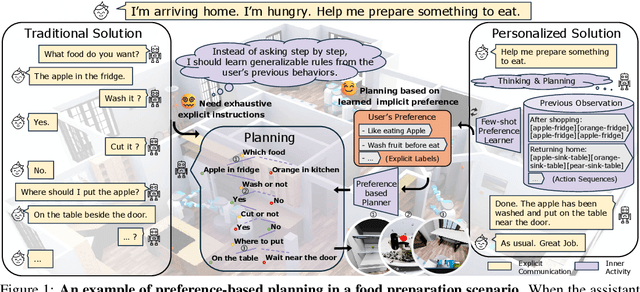
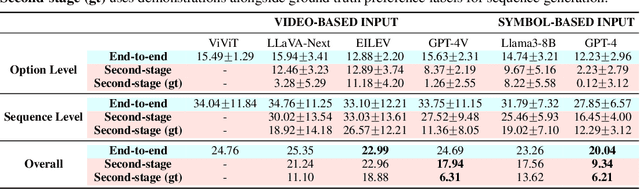
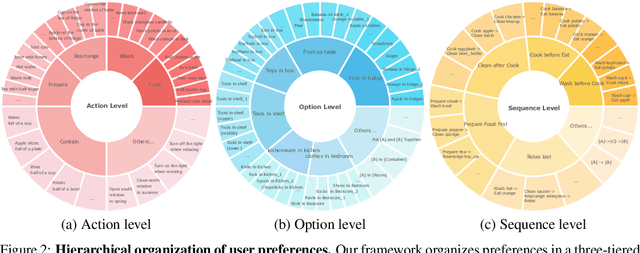
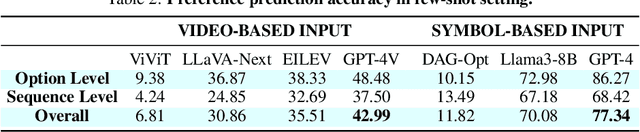
Effective integration of AI agents into daily life requires them to understand and adapt to individual human preferences, particularly in collaborative roles. Although recent studies on embodied intelligence have advanced significantly, they typically adopt generalized approaches that overlook personal preferences in planning. We address this limitation by developing agents that not only learn preferences from few demonstrations but also learn to adapt their planning strategies based on these preferences. Our research leverages the observation that preferences, though implicitly expressed through minimal demonstrations, can generalize across diverse planning scenarios. To systematically evaluate this hypothesis, we introduce Preference-based Planning (PbP) benchmark, an embodied benchmark featuring hundreds of diverse preferences spanning from atomic actions to complex sequences. Our evaluation of SOTA methods reveals that while symbol-based approaches show promise in scalability, significant challenges remain in learning to generate and execute plans that satisfy personalized preferences. We further demonstrate that incorporating learned preferences as intermediate representations in planning significantly improves the agent's ability to construct personalized plans. These findings establish preferences as a valuable abstraction layer for adaptive planning, opening new directions for research in preference-guided plan generation and execution.
SRC-gAudio: Sampling-Rate-Controlled Audio Generation
Oct 09, 2024
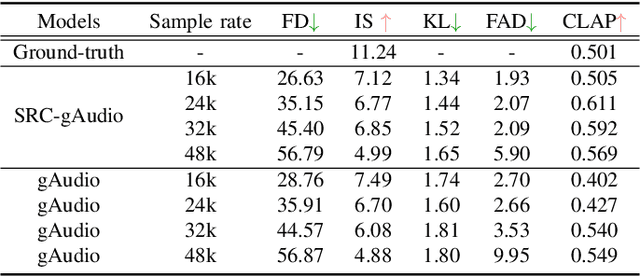
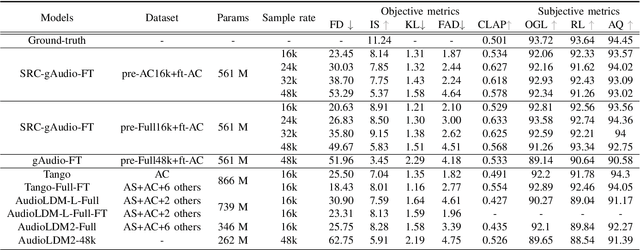
We introduce SRC-gAudio, a novel audio generation model designed to facilitate text-to-audio generation across a wide range of sampling rates within a single model architecture. SRC-gAudio incorporates the sampling rate as part of the generation condition to guide the diffusion-based audio generation process. Our model enables the generation of audio at multiple sampling rates with a single unified model. Furthermore, we explore the potential benefits of large-scale, low-sampling-rate data in enhancing the generation quality of high-sampling-rate audio. Through extensive experiments, we demonstrate that SRC-gAudio effectively generates audio under controlled sampling rates. Additionally, our results indicate that pre-training on low-sampling-rate data can lead to significant improvements in audio quality across various metrics.
Towards Diverse and Efficient Audio Captioning via Diffusion Models
Sep 14, 2024We introduce Diffusion-based Audio Captioning (DAC), a non-autoregressive diffusion model tailored for diverse and efficient audio captioning. Although existing captioning models relying on language backbones have achieved remarkable success in various captioning tasks, their insufficient performance in terms of generation speed and diversity impede progress in audio understanding and multimedia applications. Our diffusion-based framework offers unique advantages stemming from its inherent stochasticity and holistic context modeling in captioning. Through rigorous evaluation, we demonstrate that DAC not only achieves SOTA performance levels compared to existing benchmarks in the caption quality, but also significantly outperforms them in terms of generation speed and diversity. The success of DAC illustrates that text generation can also be seamlessly integrated with audio and visual generation tasks using a diffusion backbone, paving the way for a unified, audio-related generative model across different modalities.
STA-V2A: Video-to-Audio Generation with Semantic and Temporal Alignment
Sep 13, 2024
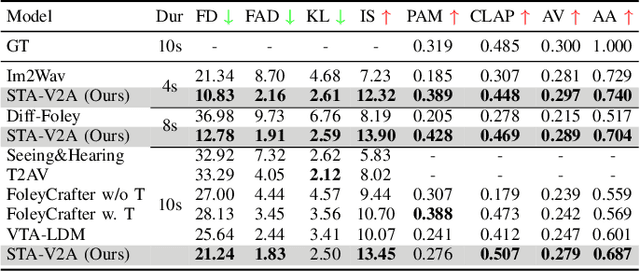


Visual and auditory perception are two crucial ways humans experience the world. Text-to-video generation has made remarkable progress over the past year, but the absence of harmonious audio in generated video limits its broader applications. In this paper, we propose Semantic and Temporal Aligned Video-to-Audio (STA-V2A), an approach that enhances audio generation from videos by extracting both local temporal and global semantic video features and combining these refined video features with text as cross-modal guidance. To address the issue of information redundancy in videos, we propose an onset prediction pretext task for local temporal feature extraction and an attentive pooling module for global semantic feature extraction. To supplement the insufficient semantic information in videos, we propose a Latent Diffusion Model with Text-to-Audio priors initialization and cross-modal guidance. We also introduce Audio-Audio Align, a new metric to assess audio-temporal alignment. Subjective and objective metrics demonstrate that our method surpasses existing Video-to-Audio models in generating audio with better quality, semantic consistency, and temporal alignment. The ablation experiment validated the effectiveness of each module. Audio samples are available at https://y-ren16.github.io/STAV2A.
Video-to-Audio Generation with Hidden Alignment
Jul 10, 2024



Generating semantically and temporally aligned audio content in accordance with video input has become a focal point for researchers, particularly following the remarkable breakthrough in text-to-video generation. In this work, we aim to offer insights into the video-to-audio generation paradigm, focusing on three crucial aspects: vision encoders, auxiliary embeddings, and data augmentation techniques. Beginning with a foundational model VTA-LDM built on a simple yet surprisingly effective intuition, we explore various vision encoders and auxiliary embeddings through ablation studies. Employing a comprehensive evaluation pipeline that emphasizes generation quality and video-audio synchronization alignment, we demonstrate that our model exhibits state-of-the-art video-to-audio generation capabilities. Furthermore, we provide critical insights into the impact of different data augmentation methods on enhancing the generation framework's overall capacity. We showcase possibilities to advance the challenge of generating synchronized audio from semantic and temporal perspectives. We hope these insights will serve as a stepping stone toward developing more realistic and accurate audio-visual generation models.
Active Reasoning in an Open-World Environment
Nov 03, 2023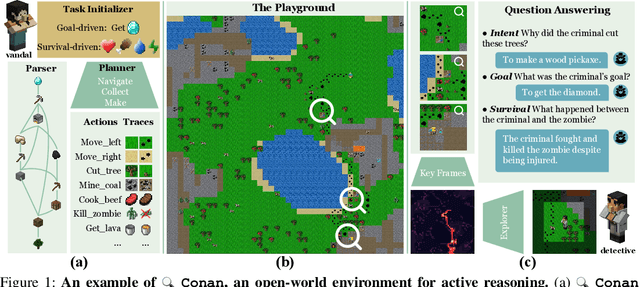

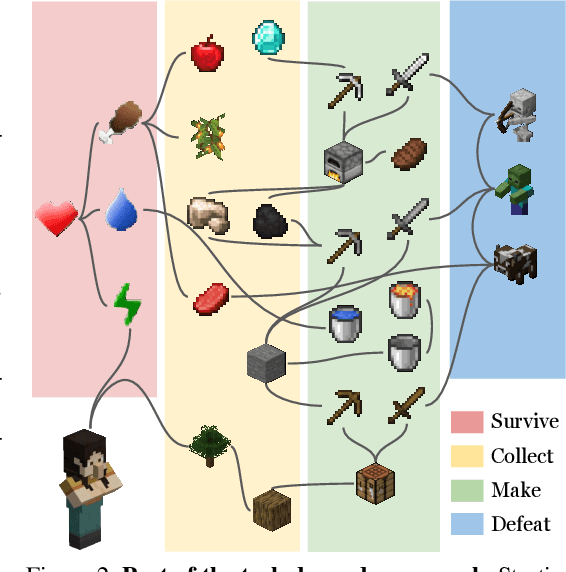

Recent advances in vision-language learning have achieved notable success on complete-information question-answering datasets through the integration of extensive world knowledge. Yet, most models operate passively, responding to questions based on pre-stored knowledge. In stark contrast, humans possess the ability to actively explore, accumulate, and reason using both newfound and existing information to tackle incomplete-information questions. In response to this gap, we introduce $Conan$, an interactive open-world environment devised for the assessment of active reasoning. $Conan$ facilitates active exploration and promotes multi-round abductive inference, reminiscent of rich, open-world settings like Minecraft. Diverging from previous works that lean primarily on single-round deduction via instruction following, $Conan$ compels agents to actively interact with their surroundings, amalgamating new evidence with prior knowledge to elucidate events from incomplete observations. Our analysis on $Conan$ underscores the shortcomings of contemporary state-of-the-art models in active exploration and understanding complex scenarios. Additionally, we explore Abduction from Deduction, where agents harness Bayesian rules to recast the challenge of abduction as a deductive process. Through $Conan$, we aim to galvanize advancements in active reasoning and set the stage for the next generation of artificial intelligence agents adept at dynamically engaging in environments.
MEWL: Few-shot multimodal word learning with referential uncertainty
Jun 01, 2023

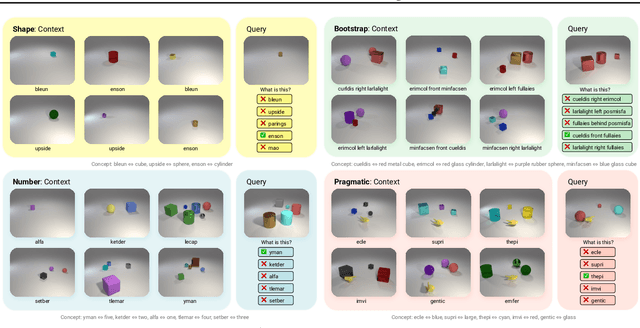
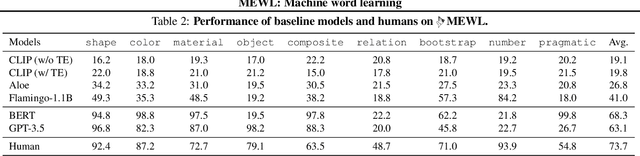
Without explicit feedback, humans can rapidly learn the meaning of words. Children can acquire a new word after just a few passive exposures, a process known as fast mapping. This word learning capability is believed to be the most fundamental building block of multimodal understanding and reasoning. Despite recent advancements in multimodal learning, a systematic and rigorous evaluation is still missing for human-like word learning in machines. To fill in this gap, we introduce the MachinE Word Learning (MEWL) benchmark to assess how machines learn word meaning in grounded visual scenes. MEWL covers human's core cognitive toolkits in word learning: cross-situational reasoning, bootstrapping, and pragmatic learning. Specifically, MEWL is a few-shot benchmark suite consisting of nine tasks for probing various word learning capabilities. These tasks are carefully designed to be aligned with the children's core abilities in word learning and echo the theories in the developmental literature. By evaluating multimodal and unimodal agents' performance with a comparative analysis of human performance, we notice a sharp divergence in human and machine word learning. We further discuss these differences between humans and machines and call for human-like few-shot word learning in machines.