 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniSonate: A Unified Model for Speech, Music, and Sound Effect Generation with Text Instructions
Apr 24, 2026Generative audio modeling has largely been fragmented into specialized tasks, text-to-speech (TTS), text-to-music (TTM), and text-to-audio (TTA), each operating under heterogeneous control paradigms. Unifying these modalities remains a fundamental challenge due to the intrinsic dissonance between structured semantic representations (speech/music) and unstructured acoustic textures (sound effects). In this paper, we introduce UniSonate, a unified flow-matching framework capable of synthesizing speech, music, and sound effects through a standardized, reference-free natural language instruction interface. To reconcile structural disparities, we propose a novel dynamic token injection mechanism that projects unstructured environmental sounds into a structured temporal latent space, enabling precise duration control within a phoneme-driven Multimodal Diffusion Transformer (MM-DiT). Coupled with a multi-stage curriculum learning strategy, this approach effectively mitigates cross-modal optimization conflicts. Extensive experiments demonstrate that UniSonate achieves state-of-the-art performance in instruction-based TTS (WER 1.47%) and TTM (SongEval Coherence 3.18), while maintaining competitive fidelity in TTA. Crucially, we observe positive transfer, where joint training on diverse audio data significantly enhances structural coherence and prosodic expressiveness compared to single-task baselines. Audio samples are available at https://qiangchunyu.github.io/UniSonate/.
AT-ADD: All-Type Audio Deepfake Detection Challenge Evaluation Plan
Apr 09, 2026The rapid advancement of Audio Large Language Models (ALLMs) has enabled cost-effective, high-fidelity generation and manipulation of both speech and non-speech audio, including sound effects, singing voices, and music. While these capabilities foster creativity and content production, they also introduce significant security and trust challenges, as realistic audio deepfakes can now be generated and disseminated at scale. Existing audio deepfake detection (ADD) countermeasures (CMs) and benchmarks, however, remain largely speech-centric, often relying on speech-specific artifacts and exhibiting limited robustness to real-world distortions, as well as restricted generalization to heterogeneous audio types and emerging spoofing techniques. To address these gaps, we propose the All-Type Audio Deepfake Detection (AT-ADD) Grand Challenge for ACM Multimedia 2026, designed to bridge controlled academic evaluation with practical multimedia forensics. AT-ADD comprises two tracks: (1) Robust Speech Deepfake Detection, which evaluates detectors under real-world scenarios and against unseen, state-of-the-art speech generation methods; and (2) All-Type Audio Deepfake Detection, which extends detection beyond speech to diverse, unknown audio types and promotes type-agnostic generalization across speech, sound, singing, and music. By providing standardized datasets, rigorous evaluation protocols, and reproducible baselines, AT-ADD aims to accelerate the development of robust and generalizable audio forensic technologies, supporting secure communication, reliable media verification, and responsible governance in an era of pervasive synthetic audio.
Interpretable All-Type Audio Deepfake Detection with Audio LLMs via Frequency-Time Reinforcement Learning
Jan 06, 2026Recent advances in audio large language models (ALLMs) have made high-quality synthetic audio widely accessible, increasing the risk of malicious audio deepfakes across speech, environmental sounds, singing voice, and music. Real-world audio deepfake detection (ADD) therefore requires all-type detectors that generalize across heterogeneous audio and provide interpretable decisions. Given the strong multi-task generalization ability of ALLMs, we first investigate their performance on all-type ADD under both supervised fine-tuning (SFT) and reinforcement fine-tuning (RFT). However, SFT using only binary real/fake labels tends to reduce the model to a black-box classifier, sacrificing interpretability. Meanwhile, vanilla RFT under sparse supervision is prone to reward hacking and can produce hallucinated, ungrounded rationales. To address this, we propose an automatic annotation and polishing pipeline that constructs Frequency-Time structured chain-of-thought (CoT) rationales, producing ~340K cold-start demonstrations. Building on CoT data, we propose Frequency Time-Group Relative Policy Optimization (FT-GRPO), a two-stage training paradigm that cold-starts ALLMs with SFT and then applies GRPO under rule-based frequency-time constraints. Experiments demonstrate that FT-GRPO achieves state-of-the-art performance on all-type ADD while producing interpretable, FT-grounded rationales. The data and code are available online.
SynParaSpeech: Automated Synthesis of Paralinguistic Datasets for Speech Generation and Understanding
Sep 18, 2025



Paralinguistic sounds, like laughter and sighs, are crucial for synthesizing more realistic and engaging speech. However, existing methods typically depend on proprietary datasets, while publicly available resources often suffer from incomplete speech, inaccurate or missing timestamps, and limited real-world relevance. To address these problems, we propose an automated framework for generating large-scale paralinguistic data and apply it to construct the SynParaSpeech dataset. The dataset comprises 6 paralinguistic categories with 118.75 hours of data and precise timestamps, all derived from natural conversational speech. Our contributions lie in introducing the first automated method for constructing large-scale paralinguistic datasets and releasing the SynParaSpeech corpus, which advances speech generation through more natural paralinguistic synthesis and enhances speech understanding by improving paralinguistic event detection. The dataset and audio samples are available at https://github.com/ShawnPi233/SynParaSpeech.
Mitigating Audiovisual Mismatch in Visual-Guide Audio Captioning
May 28, 2025Current vision-guided audio captioning systems frequently fail to address audiovisual misalignment in real-world scenarios, such as dubbed content or off-screen sounds. To bridge this critical gap, we present an entropy-aware gated fusion framework that dynamically modulates visual information flow through cross-modal uncertainty quantification. Our novel approach employs attention entropy analysis in cross-attention layers to automatically identify and suppress misleading visual cues during modal fusion. Complementing this architecture, we develop a batch-wise audiovisual shuffling technique that generates synthetic mismatched training pairs, greatly enhancing model resilience against alignment noise. Evaluations on the AudioCaps benchmark demonstrate our system's superior performance over existing baselines, especially in mismatched modality scenarios. Furthermore, our solution demonstrates an approximately 6x improvement in inference speed compared to the baseline.
Hearing from Silence: Reasoning Audio Descriptions from Silent Videos via Vision-Language Model
May 19, 2025Humans can intuitively infer sounds from silent videos, but whether multimodal large language models can perform modal-mismatch reasoning without accessing target modalities remains relatively unexplored. Current text-assisted-video-to-audio (VT2A) methods excel in video foley tasks but struggle to acquire audio descriptions during inference. We introduce the task of Reasoning Audio Descriptions from Silent Videos (SVAD) to address this challenge and investigate vision-language models' (VLMs) capabilities on this task. To further enhance the VLMs' reasoning capacity for the SVAD task, we construct a CoT-AudioCaps dataset and propose a Chain-of-Thought-based supervised fine-tuning strategy. Experiments on SVAD and subsequent VT2A tasks demonstrate our method's effectiveness in two key aspects: significantly improving VLMs' modal-mismatch reasoning for SVAD and effectively addressing the challenge of acquiring audio descriptions during VT2A inference.
Exploring Modality Disruption in Multimodal Fake News Detection
Apr 12, 2025
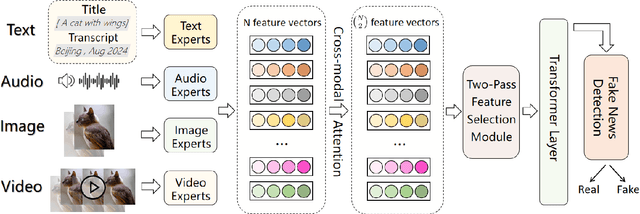
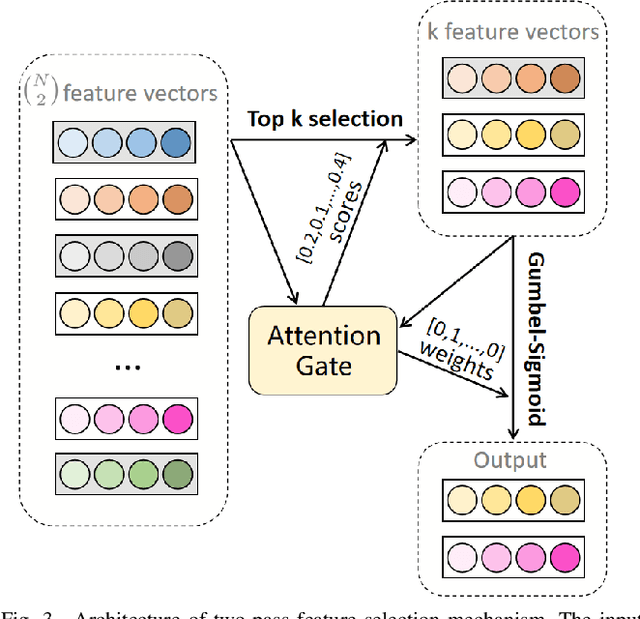
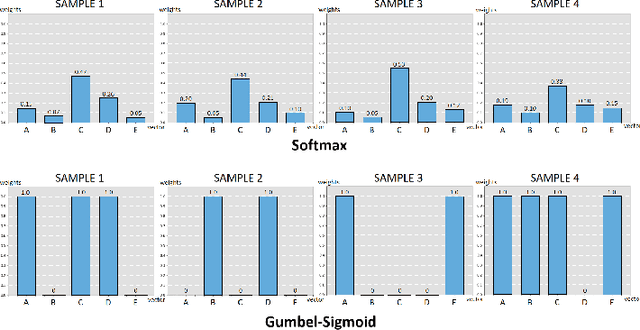
The rapid growth of social media has led to the widespread dissemination of fake news across multiple content forms, including text, images, audio, and video. Compared to unimodal fake news detection, multimodal fake news detection benefits from the increased availability of information across multiple modalities. However, in the context of social media, certain modalities in multimodal fake news detection tasks may contain disruptive or over-expressive information. These elements often include exaggerated or embellished content. We define this phenomenon as modality disruption and explore its impact on detection models through experiments. To address the issue of modality disruption in a targeted manner, we propose a multimodal fake news detection framework, FND-MoE. Additionally, we design a two-pass feature selection mechanism to further mitigate the impact of modality disruption. Extensive experiments on the FakeSV and FVC-2018 datasets demonstrate that FND-MoE significantly outperforms state-of-the-art methods, with accuracy improvements of 3.45% and 3.71% on the respective datasets compared to baseline models.
Deconfounded Reasoning for Multimodal Fake News Detection via Causal Intervention
Apr 12, 2025



The rapid growth of social media has led to the widespread dissemination of fake news across multiple content forms, including text, images, audio, and video. Traditional unimodal detection methods fall short in addressing complex cross-modal manipulations; as a result, multimodal fake news detection has emerged as a more effective solution. However, existing multimodal approaches, especially in the context of fake news detection on social media, often overlook the confounders hidden within complex cross-modal interactions, leading models to rely on spurious statistical correlations rather than genuine causal mechanisms. In this paper, we propose the Causal Intervention-based Multimodal Deconfounded Detection (CIMDD) framework, which systematically models three types of confounders via a unified Structural Causal Model (SCM): (1) Lexical Semantic Confounder (LSC); (2) Latent Visual Confounder (LVC); (3) Dynamic Cross-Modal Coupling Confounder (DCCC). To mitigate the influence of these confounders, we specifically design three causal modules based on backdoor adjustment, frontdoor adjustment, and cross-modal joint intervention to block spurious correlations from different perspectives and achieve causal disentanglement of representations for deconfounded reasoning. Experimental results on the FakeSV and FVC datasets demonstrate that CIMDD significantly improves detection accuracy, outperforming state-of-the-art methods by 4.27% and 4.80%, respectively. Furthermore, extensive experimental results indicate that CIMDD exhibits strong generalization and robustness across diverse multimodal scenarios.
Detect All-Type Deepfake Audio: Wavelet Prompt Tuning for Enhanced Auditory Perception
Apr 09, 2025



The rapid advancement of audio generation technologies has escalated the risks of malicious deepfake audio across speech, sound, singing voice, and music, threatening multimedia security and trust. While existing countermeasures (CMs) perform well in single-type audio deepfake detection (ADD), their performance declines in cross-type scenarios. This paper is dedicated to studying the alltype ADD task. We are the first to comprehensively establish an all-type ADD benchmark to evaluate current CMs, incorporating cross-type deepfake detection across speech, sound, singing voice, and music. Then, we introduce the prompt tuning self-supervised learning (PT-SSL) training paradigm, which optimizes SSL frontend by learning specialized prompt tokens for ADD, requiring 458x fewer trainable parameters than fine-tuning (FT). Considering the auditory perception of different audio types,we propose the wavelet prompt tuning (WPT)-SSL method to capture type-invariant auditory deepfake information from the frequency domain without requiring additional training parameters, thereby enhancing performance over FT in the all-type ADD task. To achieve an universally CM, we utilize all types of deepfake audio for co-training. Experimental results demonstrate that WPT-XLSR-AASIST achieved the best performance, with an average EER of 3.58% across all evaluation sets. The code is available online.
MTPareto: A MultiModal Targeted Pareto Framework for Fake News Detection
Jan 12, 2025Multimodal fake news detection is essential for maintaining the authenticity of Internet multimedia information. Significant differences in form and content of multimodal information lead to intensified optimization conflicts, hindering effective model training as well as reducing the effectiveness of existing fusion methods for bimodal. To address this problem, we propose the MTPareto framework to optimize multimodal fusion, using a Targeted Pareto(TPareto) optimization algorithm for fusion-level-specific objective learning with a certain focus. Based on the designed hierarchical fusion network, the algorithm defines three fusion levels with corresponding losses and implements all-modal-oriented Pareto gradient integration for each. This approach accomplishes superior multimodal fusion by utilizing the information obtained from intermediate fusion to provide positive effects to the entire process. Experiment results on FakeSV and FVC datasets show that the proposed framework outperforms baselines and the TPareto optimization algorithm achieves 2.40% and 1.89% accuracy improvement respectively.