 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealizing Immersive Volumetric Video: A Multimodal Framework for 6-DoF VR Engagement
Apr 10, 2026Fully immersive experiences that tightly integrate 6-DoF visual and auditory interaction are essential for virtual and augmented reality. While such experiences can be achieved through computer-generated content, constructing them directly from real-world captured videos remains largely unexplored. We introduce Immersive Volumetric Videos, a new volumetric media format designed to provide large 6-DoF interaction spaces, audiovisual feedback, and high-resolution, high-frame-rate dynamic content. To support IVV construction, we present ImViD, a multi-view, multi-modal dataset built upon a space-oriented capture philosophy. Our custom capture rig enables synchronized multi-view video-audio acquisition during motion, facilitating efficient capture of complex indoor and outdoor scenes with rich foreground--background interactions and challenging dynamics. The dataset provides 5K-resolution videos at 60 FPS with durations of 1-5 minutes, offering richer spatial, temporal, and multimodal coverage than existing benchmarks. Leveraging this dataset, we develop a dynamic light field reconstruction framework built upon a Gaussian-based spatio-temporal representation, incorporating flow-guided sparse initialization, joint camera temporal calibration, and multi-term spatio-temporal supervision for robust and accurate modeling of complex motion. We further propose, to our knowledge, the first method for sound field reconstruction from such multi-view audiovisual data. Together, these components form a unified pipeline for immersive volumetric video production. Extensive benchmarks and immersive VR experiments demonstrate that our pipeline generates high-quality, temporally stable audiovisual volumetric content with large 6-DoF interaction spaces. This work provides both a foundational definition and a practical construction methodology for immersive volumetric videos.
ImViD: Immersive Volumetric Videos for Enhanced VR Engagement
Mar 18, 2025User engagement is greatly enhanced by fully immersive multi-modal experiences that combine visual and auditory stimuli. Consequently, the next frontier in VR/AR technologies lies in immersive volumetric videos with complete scene capture, large 6-DoF interaction space, multi-modal feedback, and high resolution & frame-rate contents. To stimulate the reconstruction of immersive volumetric videos, we introduce ImViD, a multi-view, multi-modal dataset featuring complete space-oriented data capture and various indoor/outdoor scenarios. Our capture rig supports multi-view video-audio capture while on the move, a capability absent in existing datasets, significantly enhancing the completeness, flexibility, and efficiency of data capture. The captured multi-view videos (with synchronized audios) are in 5K resolution at 60FPS, lasting from 1-5 minutes, and include rich foreground-background elements, and complex dynamics. We benchmark existing methods using our dataset and establish a base pipeline for constructing immersive volumetric videos from multi-view audiovisual inputs for 6-DoF multi-modal immersive VR experiences. The benchmark and the reconstruction and interaction results demonstrate the effectiveness of our dataset and baseline method, which we believe will stimulate future research on immersive volumetric video production.
MTPareto: A MultiModal Targeted Pareto Framework for Fake News Detection
Jan 12, 2025Multimodal fake news detection is essential for maintaining the authenticity of Internet multimedia information. Significant differences in form and content of multimodal information lead to intensified optimization conflicts, hindering effective model training as well as reducing the effectiveness of existing fusion methods for bimodal. To address this problem, we propose the MTPareto framework to optimize multimodal fusion, using a Targeted Pareto(TPareto) optimization algorithm for fusion-level-specific objective learning with a certain focus. Based on the designed hierarchical fusion network, the algorithm defines three fusion levels with corresponding losses and implements all-modal-oriented Pareto gradient integration for each. This approach accomplishes superior multimodal fusion by utilizing the information obtained from intermediate fusion to provide positive effects to the entire process. Experiment results on FakeSV and FVC datasets show that the proposed framework outperforms baselines and the TPareto optimization algorithm achieves 2.40% and 1.89% accuracy improvement respectively.
Reject Threshold Adaptation for Open-Set Model Attribution of Deepfake Audio
Dec 02, 2024

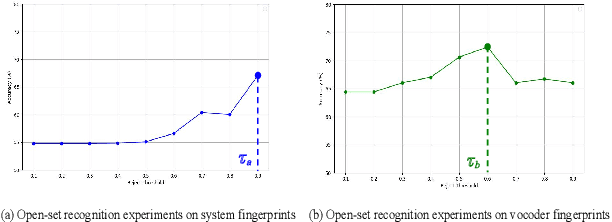

Open environment oriented open set model attribution of deepfake audio is an emerging research topic, aiming to identify the generation models of deepfake audio. Most previous work requires manually setting a rejection threshold for unknown classes to compare with predicted probabilities. However, models often overfit training instances and generate overly confident predictions. Moreover, thresholds that effectively distinguish unknown categories in the current dataset may not be suitable for identifying known and unknown categories in another data distribution. To address the issues, we propose a novel framework for open set model attribution of deepfake audio with rejection threshold adaptation (ReTA). Specifically, the reconstruction error learning module trains by combining the representation of system fingerprints with labels corresponding to either the target class or a randomly chosen other class label. This process generates matching and non-matching reconstructed samples, establishing the reconstruction error distributions for each class and laying the foundation for the reject threshold calculation module. The reject threshold calculation module utilizes gaussian probability estimation to fit the distributions of matching and non-matching reconstruction errors. It then computes adaptive reject thresholds for all classes through probability minimization criteria. The experimental results demonstrate the effectiveness of ReTA in improving the open set model attributes of deepfake audio.
DPI-TTS: Directional Patch Interaction for Fast-Converging and Style Temporal Modeling in Text-to-Speech
Sep 18, 2024


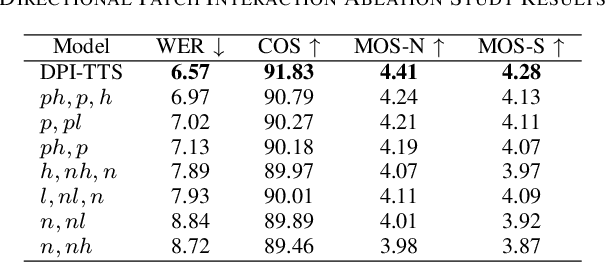
In recent years, speech diffusion models have advanced rapidly. Alongside the widely used U-Net architecture, transformer-based models such as the Diffusion Transformer (DiT) have also gained attention. However, current DiT speech models treat Mel spectrograms as general images, which overlooks the specific acoustic properties of speech. To address these limitations, we propose a method called Directional Patch Interaction for Text-to-Speech (DPI-TTS), which builds on DiT and achieves fast training without compromising accuracy. Notably, DPI-TTS employs a low-to-high frequency, frame-by-frame progressive inference approach that aligns more closely with acoustic properties, enhancing the naturalness of the generated speech. Additionally, we introduce a fine-grained style temporal modeling method that further improves speaker style similarity. Experimental results demonstrate that our method increases the training speed by nearly 2 times and significantly outperforms the baseline models.
Mixture of Experts Fusion for Fake Audio Detection Using Frozen wav2vec 2.0
Sep 18, 2024



Speech synthesis technology has posed a serious threat to speaker verification systems. Currently, the most effective fake audio detection methods utilize pretrained models, and integrating features from various layers of pretrained model further enhances detection performance. However, most of the previously proposed fusion methods require fine-tuning the pretrained models, resulting in excessively long training times and hindering model iteration when facing new speech synthesis technology. To address this issue, this paper proposes a feature fusion method based on the Mixture of Experts, which extracts and integrates features relevant to fake audio detection from layer features, guided by a gating network based on the last layer feature, while freezing the pretrained model. Experiments conducted on the ASVspoof2019 and ASVspoof2021 datasets demonstrate that the proposed method achieves competitive performance compared to those requiring fine-tuning.
Text Prompt is Not Enough: Sound Event Enhanced Prompt Adapter for Target Style Audio Generation
Sep 14, 2024



Current mainstream audio generation methods primarily rely on simple text prompts, often failing to capture the nuanced details necessary for multi-style audio generation. To address this limitation, the Sound Event Enhanced Prompt Adapter is proposed. Unlike traditional static global style transfer, this method extracts style embedding through cross-attention between text and reference audio for adaptive style control. Adaptive layer normalization is then utilized to enhance the model's capacity to express multiple styles. Additionally, the Sound Event Reference Style Transfer Dataset (SERST) is introduced for the proposed target style audio generation task, enabling dual-prompt audio generation using both text and audio references. Experimental results demonstrate the robustness of the model, achieving state-of-the-art Fr\'echet Distance of 26.94 and KL Divergence of 1.82, surpassing Tango, AudioLDM, and AudioGen. Furthermore, the generated audio shows high similarity to its corresponding audio reference. The demo, code, and dataset are publicly available.
Does Current Deepfake Audio Detection Model Effectively Detect ALM-based Deepfake Audio?
Aug 20, 2024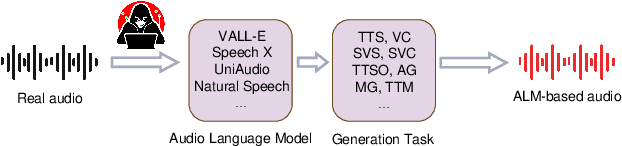
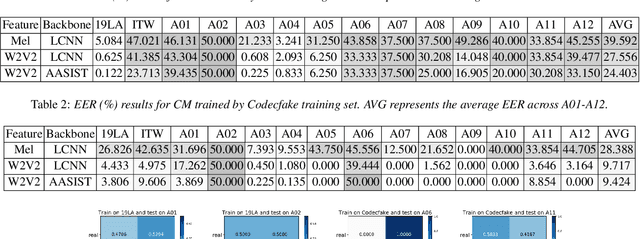

Currently, Audio Language Models (ALMs) are rapidly advancing due to the developments in large language models and audio neural codecs. These ALMs have significantly lowered the barrier to creating deepfake audio, generating highly realistic and diverse types of deepfake audio, which pose severe threats to society. Consequently, effective audio deepfake detection technologies to detect ALM-based audio have become increasingly critical. This paper investigate the effectiveness of current countermeasure (CM) against ALM-based audio. Specifically, we collect 12 types of the latest ALM-based deepfake audio and utilizing the latest CMs to evaluate. Our findings reveal that the latest codec-trained CM can effectively detect ALM-based audio, achieving 0% equal error rate under most ALM test conditions, which exceeded our expectations. This indicates promising directions for future research in ALM-based deepfake audio detection.
EELE: Exploring Efficient and Extensible LoRA Integration in Emotional Text-to-Speech
Aug 20, 2024



In the current era of Artificial Intelligence Generated Content (AIGC), a Low-Rank Adaptation (LoRA) method has emerged. It uses a plugin-based approach to learn new knowledge with lower parameter quantities and computational costs, and it can be plugged in and out based on the specific sub-tasks, offering high flexibility. However, the current application schemes primarily incorporate LoRA into the pre-introduced conditional parts of the speech models. This fixes the position of LoRA, limiting the flexibility and scalability of its application. Therefore, we propose the Exploring Efficient and Extensible LoRA Integration in Emotional Text-to-Speech (EELE) method. Starting from a general neutral speech model, we do not pre-introduce emotional information but instead use the LoRA plugin to design a flexible adaptive scheme that endows the model with emotional generation capabilities. Specifically, we initially train the model using only neutral speech data. After training is complete, we insert LoRA into different modules and fine-tune the model with emotional speech data to find the optimal insertion scheme. Through experiments, we compare and test the effects of inserting LoRA at different positions within the model and assess LoRA's ability to learn various emotions, effectively proving the validity of our method. Additionally, we explore the impact of the rank size of LoRA and the difference compared to directly fine-tuning the entire model.
A Noval Feature via Color Quantisation for Fake Audio Detection
Aug 20, 2024



In the field of deepfake detection, previous studies focus on using reconstruction or mask and prediction methods to train pre-trained models, which are then transferred to fake audio detection training where the encoder is used to extract features, such as wav2vec2.0 and Masked Auto Encoder. These methods have proven that using real audio for reconstruction pre-training can better help the model distinguish fake audio. However, the disadvantage lies in poor interpretability, meaning it is hard to intuitively present the differences between deepfake and real audio. This paper proposes a noval feature extraction method via color quantisation which constrains the reconstruction to use a limited number of colors for the spectral image-like input. The proposed method ensures reconstructed input differs from the original, which allows for intuitive observation of the focus areas in the spectral reconstruction. Experiments conducted on the ASVspoof2019 dataset demonstrate that the proposed method achieves better classification performance compared to using the original spectral as input and pretraining the recolor network can also benefit the fake audio detection.