 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Explicit Acoustic Evidence Perception in Audio LLMs for Speech Deepfake Detection
Jan 30, 2026Speech deepfake detection (SDD) focuses on identifying whether a given speech signal is genuine or has been synthetically generated. Existing audio large language model (LLM)-based methods excel in content understanding; however, their predictions are often biased toward semantically correlated cues, which results in fine-grained acoustic artifacts being overlooked during the decisionmaking process. Consequently, fake speech with natural semantics can bypass detectors despite harboring subtle acoustic anomalies; this suggests that the challenge stems not from the absence of acoustic data, but from its inadequate accessibility when semantic-dominant reasoning prevails. To address this issue, we investigate SDD within the audio LLM paradigm and introduce SDD with Auditory Perception-enhanced Audio Large Language Model (SDD-APALLM), an acoustically enhanced framework designed to explicitly expose fine-grained time-frequency evidence as accessible acoustic cues. By combining raw audio with structured spectrograms, the proposed framework empowers audio LLMs to more effectively capture subtle acoustic inconsistencies without compromising their semantic understanding. Experimental results indicate consistent gains in detection accuracy and robustness, especially in cases where semantic cues are misleading. Further analysis reveals that these improvements stem from a coordinated utilization of semantic and acoustic information, as opposed to simple modality aggregation.
Unifying Speech Editing Detection and Content Localization via Prior-Enhanced Audio LLMs
Jan 29, 2026Speech editing achieves semantic inversion by performing fine-grained segment-level manipulation on original utterances, while preserving global perceptual naturalness. Existing detection studies mainly focus on manually edited speech with explicit splicing artifacts, and therefore struggle to cope with emerging end-to-end neural speech editing techniques that generate seamless acoustic transitions. To address this challenge, we first construct a large-scale bilingual dataset, AiEdit, which leverages large language models to drive precise semantic tampering logic and employs multiple advanced neural speech editing methods for data synthesis, thereby filling the gap of high-quality speech editing datasets. Building upon this foundation, we propose PELM (Prior-Enhanced Audio Large Language Model), the first large-model framework that unifies speech editing detection and content localization by formulating them as an audio question answering task. To mitigate the inherent forgery bias and semantic-priority bias observed in existing audio large models, PELM incorporates word-level probability priors to provide explicit acoustic cues, and further designs a centroid-aggregation-based acoustic consistency perception loss to explicitly enforce the modeling of subtle local distribution anomalies. Extensive experimental results demonstrate that PELM significantly outperforms state-of-the-art methods on both the HumanEdit and AiEdit datasets, achieving equal error rates (EER) of 0.57\% and 9.28\% (localization), respectively.
Interpretable All-Type Audio Deepfake Detection with Audio LLMs via Frequency-Time Reinforcement Learning
Jan 06, 2026Recent advances in audio large language models (ALLMs) have made high-quality synthetic audio widely accessible, increasing the risk of malicious audio deepfakes across speech, environmental sounds, singing voice, and music. Real-world audio deepfake detection (ADD) therefore requires all-type detectors that generalize across heterogeneous audio and provide interpretable decisions. Given the strong multi-task generalization ability of ALLMs, we first investigate their performance on all-type ADD under both supervised fine-tuning (SFT) and reinforcement fine-tuning (RFT). However, SFT using only binary real/fake labels tends to reduce the model to a black-box classifier, sacrificing interpretability. Meanwhile, vanilla RFT under sparse supervision is prone to reward hacking and can produce hallucinated, ungrounded rationales. To address this, we propose an automatic annotation and polishing pipeline that constructs Frequency-Time structured chain-of-thought (CoT) rationales, producing ~340K cold-start demonstrations. Building on CoT data, we propose Frequency Time-Group Relative Policy Optimization (FT-GRPO), a two-stage training paradigm that cold-starts ALLMs with SFT and then applies GRPO under rule-based frequency-time constraints. Experiments demonstrate that FT-GRPO achieves state-of-the-art performance on all-type ADD while producing interpretable, FT-grounded rationales. The data and code are available online.
Detect All-Type Deepfake Audio: Wavelet Prompt Tuning for Enhanced Auditory Perception
Apr 09, 2025



The rapid advancement of audio generation technologies has escalated the risks of malicious deepfake audio across speech, sound, singing voice, and music, threatening multimedia security and trust. While existing countermeasures (CMs) perform well in single-type audio deepfake detection (ADD), their performance declines in cross-type scenarios. This paper is dedicated to studying the alltype ADD task. We are the first to comprehensively establish an all-type ADD benchmark to evaluate current CMs, incorporating cross-type deepfake detection across speech, sound, singing voice, and music. Then, we introduce the prompt tuning self-supervised learning (PT-SSL) training paradigm, which optimizes SSL frontend by learning specialized prompt tokens for ADD, requiring 458x fewer trainable parameters than fine-tuning (FT). Considering the auditory perception of different audio types,we propose the wavelet prompt tuning (WPT)-SSL method to capture type-invariant auditory deepfake information from the frequency domain without requiring additional training parameters, thereby enhancing performance over FT in the all-type ADD task. To achieve an universally CM, we utilize all types of deepfake audio for co-training. Experimental results demonstrate that WPT-XLSR-AASIST achieved the best performance, with an average EER of 3.58% across all evaluation sets. The code is available online.
Neural Codec Source Tracing: Toward Comprehensive Attribution in Open-Set Condition
Jan 11, 2025



Current research in audio deepfake detection is gradually transitioning from binary classification to multi-class tasks, referred as audio deepfake source tracing task. However, existing studies on source tracing consider only closed-set scenarios and have not considered the challenges posed by open-set conditions. In this paper, we define the Neural Codec Source Tracing (NCST) task, which is capable of performing open-set neural codec classification and interpretable ALM detection. Specifically, we constructed the ST-Codecfake dataset for the NCST task, which includes bilingual audio samples generated by 11 state-of-the-art neural codec methods and ALM-based out-ofdistribution (OOD) test samples. Furthermore, we establish a comprehensive source tracing benchmark to assess NCST models in open-set conditions. The experimental results reveal that although the NCST models perform well in in-distribution (ID) classification and OOD detection, they lack robustness in classifying unseen real audio. The ST-codecfake dataset and code are available.
Mixture of Experts Fusion for Fake Audio Detection Using Frozen wav2vec 2.0
Sep 18, 2024



Speech synthesis technology has posed a serious threat to speaker verification systems. Currently, the most effective fake audio detection methods utilize pretrained models, and integrating features from various layers of pretrained model further enhances detection performance. However, most of the previously proposed fusion methods require fine-tuning the pretrained models, resulting in excessively long training times and hindering model iteration when facing new speech synthesis technology. To address this issue, this paper proposes a feature fusion method based on the Mixture of Experts, which extracts and integrates features relevant to fake audio detection from layer features, guided by a gating network based on the last layer feature, while freezing the pretrained model. Experiments conducted on the ASVspoof2019 and ASVspoof2021 datasets demonstrate that the proposed method achieves competitive performance compared to those requiring fine-tuning.
DPI-TTS: Directional Patch Interaction for Fast-Converging and Style Temporal Modeling in Text-to-Speech
Sep 18, 2024


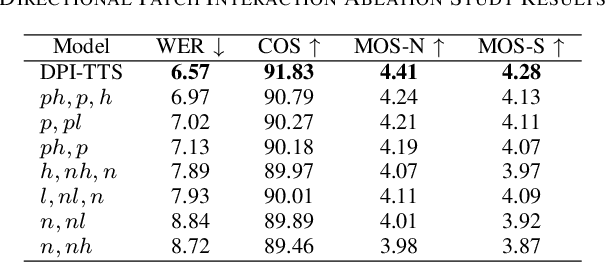
In recent years, speech diffusion models have advanced rapidly. Alongside the widely used U-Net architecture, transformer-based models such as the Diffusion Transformer (DiT) have also gained attention. However, current DiT speech models treat Mel spectrograms as general images, which overlooks the specific acoustic properties of speech. To address these limitations, we propose a method called Directional Patch Interaction for Text-to-Speech (DPI-TTS), which builds on DiT and achieves fast training without compromising accuracy. Notably, DPI-TTS employs a low-to-high frequency, frame-by-frame progressive inference approach that aligns more closely with acoustic properties, enhancing the naturalness of the generated speech. Additionally, we introduce a fine-grained style temporal modeling method that further improves speaker style similarity. Experimental results demonstrate that our method increases the training speed by nearly 2 times and significantly outperforms the baseline models.
Text Prompt is Not Enough: Sound Event Enhanced Prompt Adapter for Target Style Audio Generation
Sep 14, 2024



Current mainstream audio generation methods primarily rely on simple text prompts, often failing to capture the nuanced details necessary for multi-style audio generation. To address this limitation, the Sound Event Enhanced Prompt Adapter is proposed. Unlike traditional static global style transfer, this method extracts style embedding through cross-attention between text and reference audio for adaptive style control. Adaptive layer normalization is then utilized to enhance the model's capacity to express multiple styles. Additionally, the Sound Event Reference Style Transfer Dataset (SERST) is introduced for the proposed target style audio generation task, enabling dual-prompt audio generation using both text and audio references. Experimental results demonstrate the robustness of the model, achieving state-of-the-art Fr\'echet Distance of 26.94 and KL Divergence of 1.82, surpassing Tango, AudioLDM, and AudioGen. Furthermore, the generated audio shows high similarity to its corresponding audio reference. The demo, code, and dataset are publicly available.
Does Current Deepfake Audio Detection Model Effectively Detect ALM-based Deepfake Audio?
Aug 20, 2024
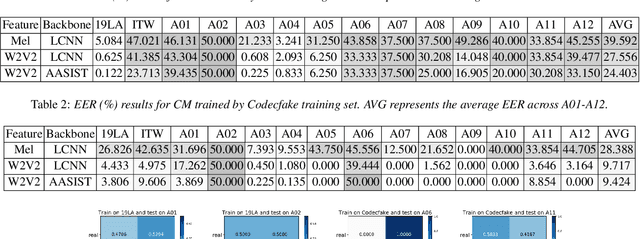

Currently, Audio Language Models (ALMs) are rapidly advancing due to the developments in large language models and audio neural codecs. These ALMs have significantly lowered the barrier to creating deepfake audio, generating highly realistic and diverse types of deepfake audio, which pose severe threats to society. Consequently, effective audio deepfake detection technologies to detect ALM-based audio have become increasingly critical. This paper investigate the effectiveness of current countermeasure (CM) against ALM-based audio. Specifically, we collect 12 types of the latest ALM-based deepfake audio and utilizing the latest CMs to evaluate. Our findings reveal that the latest codec-trained CM can effectively detect ALM-based audio, achieving 0% equal error rate under most ALM test conditions, which exceeded our expectations. This indicates promising directions for future research in ALM-based deepfake audio detection.
A Noval Feature via Color Quantisation for Fake Audio Detection
Aug 20, 2024



In the field of deepfake detection, previous studies focus on using reconstruction or mask and prediction methods to train pre-trained models, which are then transferred to fake audio detection training where the encoder is used to extract features, such as wav2vec2.0 and Masked Auto Encoder. These methods have proven that using real audio for reconstruction pre-training can better help the model distinguish fake audio. However, the disadvantage lies in poor interpretability, meaning it is hard to intuitively present the differences between deepfake and real audio. This paper proposes a noval feature extraction method via color quantisation which constrains the reconstruction to use a limited number of colors for the spectral image-like input. The proposed method ensures reconstructed input differs from the original, which allows for intuitive observation of the focus areas in the spectral reconstruction. Experiments conducted on the ASVspoof2019 dataset demonstrate that the proposed method achieves better classification performance compared to using the original spectral as input and pretraining the recolor network can also benefit the fake audio detection.