 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Autoencoders as Universal Speech Enhancer
Feb 02, 2026Supervised speech enhancement methods have been very successful. However, in practical scenarios, there is a lack of clean speech, and self-supervised learning-based (SSL) speech enhancement methods that offer comparable enhancement performance and can be applied to other speech-related downstream applications are desired. In this work, we develop a masked autoencoder based universal speech enhancer that is agnostic to the type of distortion affecting speech, can handle multiple distortions simultaneously, and is trained in a self-supervised manner. An augmentation stack adds further distortions to the noisy input data. The masked autoencoder model learns to remove the added distortions along with reconstructing the masked regions of the spectrogram during pre-training. The pre-trained embeddings are then used by fine-tuning models trained on a small amount of paired data for specific downstream tasks. We evaluate the pre-trained features for denoising and dereverberation downstream tasks. We explore different augmentations (like single or multi-speaker) in the pre-training augmentation stack and the effect of different noisy input feature representations (like $log1p$ compression) on pre-trained embeddings and downstream fine-tuning enhancement performance. We show that the proposed method not only outperforms the baseline but also achieves state-of-the-art performance for both in-domain and out-of-domain evaluation datasets.
Unifying Speech Editing Detection and Content Localization via Prior-Enhanced Audio LLMs
Jan 29, 2026Speech editing achieves semantic inversion by performing fine-grained segment-level manipulation on original utterances, while preserving global perceptual naturalness. Existing detection studies mainly focus on manually edited speech with explicit splicing artifacts, and therefore struggle to cope with emerging end-to-end neural speech editing techniques that generate seamless acoustic transitions. To address this challenge, we first construct a large-scale bilingual dataset, AiEdit, which leverages large language models to drive precise semantic tampering logic and employs multiple advanced neural speech editing methods for data synthesis, thereby filling the gap of high-quality speech editing datasets. Building upon this foundation, we propose PELM (Prior-Enhanced Audio Large Language Model), the first large-model framework that unifies speech editing detection and content localization by formulating them as an audio question answering task. To mitigate the inherent forgery bias and semantic-priority bias observed in existing audio large models, PELM incorporates word-level probability priors to provide explicit acoustic cues, and further designs a centroid-aggregation-based acoustic consistency perception loss to explicitly enforce the modeling of subtle local distribution anomalies. Extensive experimental results demonstrate that PELM significantly outperforms state-of-the-art methods on both the HumanEdit and AiEdit datasets, achieving equal error rates (EER) of 0.57\% and 9.28\% (localization), respectively.
Origami-Inspired Soft Gripper with Tunable Constant Force Output
Mar 03, 2025Soft robotic grippers gently and safely manipulate delicate objects due to their inherent adaptability and softness. Limited by insufficient stiffness and imprecise force control, conventional soft grippers are not suitable for applications that require stable grasping force. In this work, we propose a soft gripper that utilizes an origami-inspired structure to achieve tunable constant force output over a wide strain range. The geometry of each taper panel is established to provide necessary parameters such as protrusion distance, taper angle, and crease thickness required for 3D modeling and FEA analysis. Simulations and experiments show that by optimizing these parameters, our design can achieve a tunable constant force output. Moreover, the origami-inspired soft gripper dynamically adapts to different shapes while preventing excessive forces, with potential applications in logistics, manufacturing, and other industrial settings that require stable and adaptive operations
Bag of Tricks for Multimodal AutoML with Image, Text, and Tabular Data
Dec 19, 2024



This paper studies the best practices for automatic machine learning (AutoML). While previous AutoML efforts have predominantly focused on unimodal data, the multimodal aspect remains under-explored. Our study delves into classification and regression problems involving flexible combinations of image, text, and tabular data. We curate a benchmark comprising 22 multimodal datasets from diverse real-world applications, encompassing all 4 combinations of the 3 modalities. Across this benchmark, we scrutinize design choices related to multimodal fusion strategies, multimodal data augmentation, converting tabular data into text, cross-modal alignment, and handling missing modalities. Through extensive experimentation and analysis, we distill a collection of effective strategies and consolidate them into a unified pipeline, achieving robust performance on diverse datasets.
Octopus-Swimming-Like Robot with Soft Asymmetric Arms
Oct 15, 2024



Underwater vehicles have seen significant development over the past seventy years. However, bio-inspired propulsion robots are still in their early stages and require greater interdisciplinary collaboration between biologists and roboticists. The octopus, one of the most intelligent marine animals, exhibits remarkable abilities such as camouflaging, exploring, and hunting while swimming with its arms. Although bio-inspired robotics researchers have aimed to replicate these abilities, the complexity of designing an eight-arm bionic swimming platform has posed challenges from the beginning. In this work, we propose a novel bionic robot swimming platform that combines asymmetric passive morphing arms with an umbrella-like quick-return mechanism. Using only two simple constant-speed motors, this design achieves efficient swimming by replicating octopus-like arm movements and stroke time ratios. The robot reached a peak speed of 314 mm/s during its second power stroke. This design reduces the complexity of traditional octopus-like swimming robot actuation systems while maintaining good swimming performance. It offers a more achievable and efficient platform for biologists and roboticists conducting more profound octopus-inspired robotic and biological studies.
Learning to Generate Answers with Citations via Factual Consistency Models
Jun 19, 2024Large Language Models (LLMs) frequently hallucinate, impeding their reliability in mission-critical situations. One approach to address this issue is to provide citations to relevant sources alongside generated content, enhancing the verifiability of generations. However, citing passages accurately in answers remains a substantial challenge. This paper proposes a weakly-supervised fine-tuning method leveraging factual consistency models (FCMs). Our approach alternates between generating texts with citations and supervised fine-tuning with FCM-filtered citation data. Focused learning is integrated into the objective, directing the fine-tuning process to emphasise the factual unit tokens, as measured by an FCM. Results on the ALCE few-shot citation benchmark with various instruction-tuned LLMs demonstrate superior performance compared to in-context learning, vanilla supervised fine-tuning, and state-of-the-art methods, with an average improvement of $34.1$, $15.5$, and $10.5$ citation F$_1$ points, respectively. Moreover, in a domain transfer setting we show that the obtained citation generation ability robustly transfers to unseen datasets. Notably, our citation improvements contribute to the lowest factual error rate across baselines.
AutoGluon-Multimodal (AutoMM): Supercharging Multimodal AutoML with Foundation Models
Apr 30, 2024



AutoGluon-Multimodal (AutoMM) is introduced as an open-source AutoML library designed specifically for multimodal learning. Distinguished by its exceptional ease of use, AutoMM enables fine-tuning of foundation models with just three lines of code. Supporting various modalities including image, text, and tabular data, both independently and in combination, the library offers a comprehensive suite of functionalities spanning classification, regression, object detection, semantic matching, and image segmentation. Experiments across diverse datasets and tasks showcases AutoMM's superior performance in basic classification and regression tasks compared to existing AutoML tools, while also demonstrating competitive results in advanced tasks, aligning with specialized toolboxes designed for such purposes.
Convolution Meets LoRA: Parameter Efficient Finetuning for Segment Anything Model
Jan 31, 2024

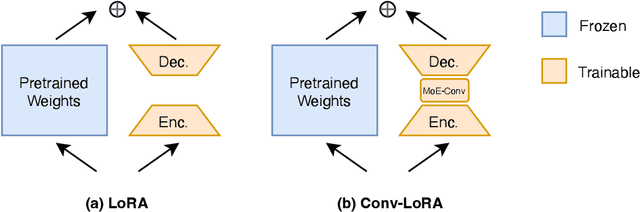

The Segment Anything Model (SAM) stands as a foundational framework for image segmentation. While it exhibits remarkable zero-shot generalization in typical scenarios, its advantage diminishes when applied to specialized domains like medical imagery and remote sensing. To address this limitation, this paper introduces Conv-LoRA, a simple yet effective parameter-efficient fine-tuning approach. By integrating ultra-lightweight convolutional parameters into Low-Rank Adaptation (LoRA), Conv-LoRA can inject image-related inductive biases into the plain ViT encoder, further reinforcing SAM's local prior assumption. Notably, Conv-LoRA not only preserves SAM's extensive segmentation knowledge but also revives its capacity of learning high-level image semantics, which is constrained by SAM's foreground-background segmentation pretraining. Comprehensive experimentation across diverse benchmarks spanning multiple domains underscores Conv-LoRA's superiority in adapting SAM to real-world semantic segmentation tasks.
Learning Multimodal Data Augmentation in Feature Space
Dec 29, 2022



The ability to jointly learn from multiple modalities, such as text, audio, and visual data, is a defining feature of intelligent systems. While there have been promising advances in designing neural networks to harness multimodal data, the enormous success of data augmentation currently remains limited to single-modality tasks like image classification. Indeed, it is particularly difficult to augment each modality while preserving the overall semantic structure of the data; for example, a caption may no longer be a good description of an image after standard augmentations have been applied, such as translation. Moreover, it is challenging to specify reasonable transformations that are not tailored to a particular modality. In this paper, we introduce LeMDA, Learning Multimodal Data Augmentation, an easy-to-use method that automatically learns to jointly augment multimodal data in feature space, with no constraints on the identities of the modalities or the relationship between modalities. We show that LeMDA can (1) profoundly improve the performance of multimodal deep learning architectures, (2) apply to combinations of modalities that have not been previously considered, and (3) achieve state-of-the-art results on a wide range of applications comprised of image, text, and tabular data.
Are Multimodal Models Robust to Image and Text Perturbations?
Dec 15, 2022



Multimodal image-text models have shown remarkable performance in the past few years. However, evaluating their robustness against distribution shifts is crucial before adopting them in real-world applications. In this paper, we investigate the robustness of 9 popular open-sourced image-text models under common perturbations on five tasks (image-text retrieval, visual reasoning, visual entailment, image captioning, and text-to-image generation). In particular, we propose several new multimodal robustness benchmarks by applying 17 image perturbation and 16 text perturbation techniques on top of existing datasets. We observe that multimodal models are not robust to image and text perturbations, especially to image perturbations. Among the tested perturbation methods, character-level perturbations constitute the most severe distribution shift for text, and zoom blur is the most severe shift for image data. We also introduce two new robustness metrics (MMI and MOR) for proper evaluations of multimodal models. We hope our extensive study sheds light on new directions for the development of robust multimodal models.