 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-Guided Unsupervised Semantic-Aware Exposure Correction
Jan 27, 2026Improper exposure often leads to severe loss of details, color distortion, and reduced contrast. Exposure correction still faces two critical challenges: (1) the ignorance of object-wise regional semantic information causes the color shift artifacts; (2) real-world exposure images generally have no ground-truth labels, and its labeling entails massive manual editing. To tackle the challenges, we propose a new unsupervised semantic-aware exposure correction network. It contains an adaptive semantic-aware fusion module, which effectively fuses the semantic information extracted from a pre-trained Fast Segment Anything Model into a shared image feature space. Then the fused features are used by our multi-scale residual spatial mamba group to restore the details and adjust the exposure. To avoid manual editing, we propose a pseudo-ground truth generator guided by CLIP, which is fine-tuned to automatically identify exposure situations and instruct the tailored corrections. Also, we leverage the rich priors from the FastSAM and CLIP to develop a semantic-prompt consistency loss to enforce semantic consistency and image-prompt alignment for unsupervised training. Comprehensive experimental results illustrate the effectiveness of our method in correcting real-world exposure images and outperforms state-of-the-art unsupervised methods both numerically and visually.
Fast and Safe Trajectory Optimization for Mobile Manipulators With Neural Configuration Space Distance Field
Jan 27, 2026Mobile manipulators promise agile, long-horizon behavior by coordinating base and arm motion, yet whole-body trajectory optimization in cluttered, confined spaces remains difficult due to high-dimensional nonconvexity and the need for fast, accurate collision reasoning. Configuration Space Distance Fields (CDF) enable fixed-base manipulators to model collisions directly in configuration space via smooth, implicit distances. This representation holds strong potential to bypass the nonlinear configuration-to-workspace mapping while preserving accurate whole-body geometry and providing optimization-friendly collision costs. Yet, extending this capability to mobile manipulators is hindered by unbounded workspaces and tighter base-arm coupling. We lift this promise to mobile manipulation with Generalized Configuration Space Distance Fields (GCDF), extending CDF to robots with both translational and rotational joints in unbounded workspaces with tighter base-arm coupling. We prove that GCDF preserves Euclidean-like local distance structure and accurately encodes whole-body geometry in configuration space, and develop a data generation and training pipeline that yields continuous neural GCDFs with accurate values and gradients, supporting efficient GPU-batched queries. Building on this representation, we develop a high-performance sequential convex optimization framework centered on GCDF-based collision reasoning. The solver scales to large numbers of implicit constraints through (i) online specification of neural constraints, (ii) sparsity-aware active-set detection with parallel batched evaluation across thousands of constraints, and (iii) incremental constraint management for rapid replanning under scene changes.
DAOS: A Multimodal In-cabin Behavior Monitoring with Driver Action-Object Synergy Dataset
Jan 17, 2026In driver activity monitoring, movements are mostly limited to the upper body, which makes many actions look similar. To tell these actions apart, human often rely on the objects the driver is using, such as holding a phone compared with gripping the steering wheel. However, most existing driver-monitoring datasets lack accurate object-location annotations or do not link objects to their associated actions, leaving a critical gap for reliable action recognition. To address this, we introduce the Driver Action with Object Synergy (DAOS) dataset, comprising 9,787 video clips annotated with 36 fine-grained driver actions and 15 object classes, totaling more than 2.5 million corresponding object instances. DAOS offers multi-modal, multi-view data (RGB, IR, and depth) from front, face, left, and right perspectives. Although DAOS captures a wide range of cabin objects, only a few are directly relevant to each action for prediction, so focusing on task-specific human-object relations is essential. To tackle this challenge, we propose the Action-Object-Relation Network (AOR-Net). AOR-Net comprehends complex driver actions through multi-level reasoning and a chain-of-action prompting mechanism that models the logical relationships among actions, objects, and their relations. Additionally, the Mixture of Thoughts module is introduced to dynamically select essential knowledge at each stage, enhancing robustness in object-rich and object-scarce conditions. Extensive experiments demonstrate that our model outperforms other state-of-the-art methods on various datasets.
SwiftMem: Fast Agentic Memory via Query-aware Indexing
Jan 13, 2026Agentic memory systems have become critical for enabling LLM agents to maintain long-term context and retrieve relevant information efficiently. However, existing memory frameworks suffer from a fundamental limitation: they perform exhaustive retrieval across the entire storage layer regardless of query characteristics. This brute-force approach creates severe latency bottlenecks as memory grows, hindering real-time agent interactions. We propose SwiftMem, a query-aware agentic memory system that achieves sub-linear retrieval through specialized indexing over temporal and semantic dimensions. Our temporal index enables logarithmic-time range queries for time-sensitive retrieval, while the semantic DAG-Tag index maps queries to relevant topics through hierarchical tag structures. To address memory fragmentation during growth, we introduce an embedding-tag co-consolidation mechanism that reorganizes storage based on semantic clusters to improve cache locality. Experiments on LoCoMo and LongMemEval benchmarks demonstrate that SwiftMem achieves 47$\times$ faster search compared to state-of-the-art baselines while maintaining competitive accuracy, enabling practical deployment of memory-augmented LLM agents.
Revisiting Judge Decoding from First Principles via Training-Free Distributional Divergence
Jan 08, 2026Judge Decoding accelerates LLM inference by relaxing the strict verification of Speculative Decoding, yet it typically relies on expensive and noisy supervision. In this work, we revisit this paradigm from first principles, revealing that the ``criticality'' scores learned via costly supervision are intrinsically encoded in the draft-target distributional divergence. We theoretically prove a structural correspondence between learned linear judges and Kullback-Leibler (KL) divergence, demonstrating they rely on the same underlying logit primitives. Guided by this, we propose a simple, training-free verification mechanism based on KL divergence. Extensive experiments across reasoning and coding benchmarks show that our method matches or outperforms complex trained judges (e.g., AutoJudge), offering superior robustness to domain shifts and eliminating the supervision bottleneck entirely.
Odysseus: Jailbreaking Commercial Multimodal LLM-integrated Systems via Dual Steganography
Dec 23, 2025By integrating language understanding with perceptual modalities such as images, multimodal large language models (MLLMs) constitute a critical substrate for modern AI systems, particularly intelligent agents operating in open and interactive environments. However, their increasing accessibility also raises heightened risks of misuse, such as generating harmful or unsafe content. To mitigate these risks, alignment techniques are commonly applied to align model behavior with human values. Despite these efforts, recent studies have shown that jailbreak attacks can circumvent alignment and elicit unsafe outputs. Currently, most existing jailbreak methods are tailored for open-source models and exhibit limited effectiveness against commercial MLLM-integrated systems, which often employ additional filters. These filters can detect and prevent malicious input and output content, significantly reducing jailbreak threats. In this paper, we reveal that the success of these safety filters heavily relies on a critical assumption that malicious content must be explicitly visible in either the input or the output. This assumption, while often valid for traditional LLM-integrated systems, breaks down in MLLM-integrated systems, where attackers can leverage multiple modalities to conceal adversarial intent, leading to a false sense of security in existing MLLM-integrated systems. To challenge this assumption, we propose Odysseus, a novel jailbreak paradigm that introduces dual steganography to covertly embed malicious queries and responses into benign-looking images. Extensive experiments on benchmark datasets demonstrate that our Odysseus successfully jailbreaks several pioneering and realistic MLLM-integrated systems, achieving up to 99% attack success rate. It exposes a fundamental blind spot in existing defenses, and calls for rethinking cross-modal security in MLLM-integrated systems.
LLaViDA: A Large Language Vision Driving Assistant for Explicit Reasoning and Enhanced Trajectory Planning
Dec 20, 2025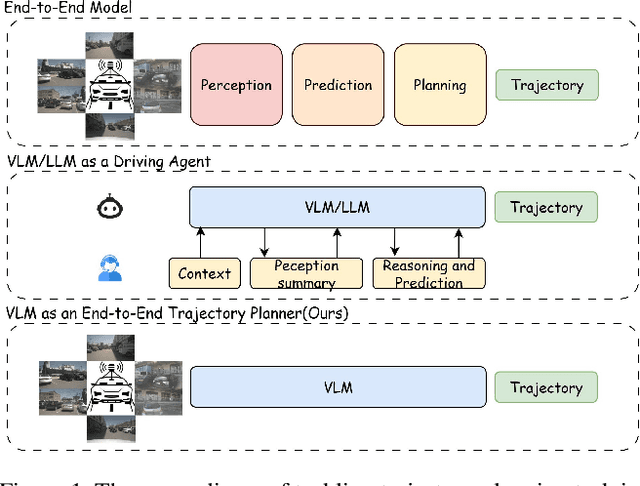
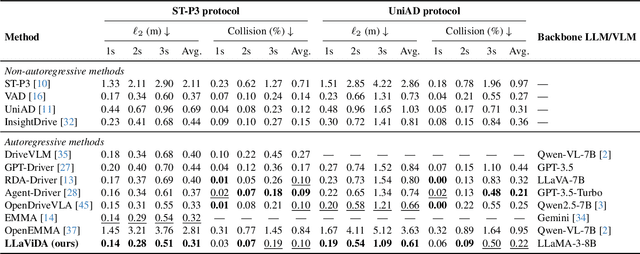
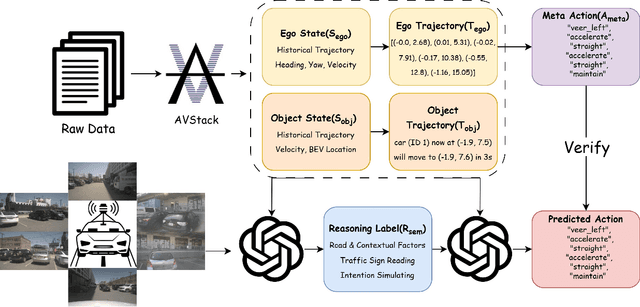
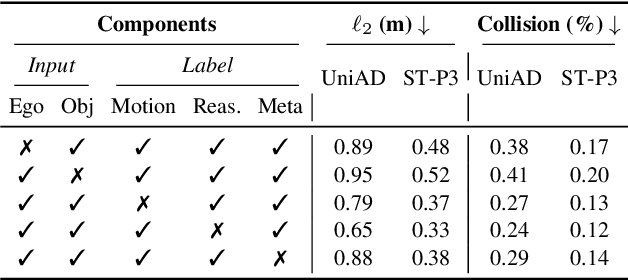
Trajectory planning is a fundamental yet challenging component of autonomous driving. End-to-end planners frequently falter under adverse weather, unpredictable human behavior, or complex road layouts, primarily because they lack strong generalization or few-shot capabilities beyond their training data. We propose LLaViDA, a Large Language Vision Driving Assistant that leverages a Vision-Language Model (VLM) for object motion prediction, semantic grounding, and chain-of-thought reasoning for trajectory planning in autonomous driving. A two-stage training pipeline--supervised fine-tuning followed by Trajectory Preference Optimization (TPO)--enhances scene understanding and trajectory planning by injecting regression-based supervision, produces a powerful "VLM Trajectory Planner for Autonomous Driving." On the NuScenes benchmark, LLaViDA surpasses state-of-the-art end-to-end and other recent VLM/LLM-based baselines in open-loop trajectory planning task, achieving an average L2 trajectory error of 0.31 m and a collision rate of 0.10% on the NuScenes test set. The code for this paper is available at GitHub.
Towards Efficient Agents: A Co-Design of Inference Architecture and System
Dec 20, 2025The rapid development of large language model (LLM)-based agents has unlocked new possibilities for autonomous multi-turn reasoning and tool-augmented decision-making. However, their real-world deployment is hindered by severe inefficiencies that arise not from isolated model inference, but from the systemic latency accumulated across reasoning loops, context growth, and heterogeneous tool interactions. This paper presents AgentInfer, a unified framework for end-to-end agent acceleration that bridges inference optimization and architectural design. We decompose the problem into four synergistic components: AgentCollab, a hierarchical dual-model reasoning framework that balances large- and small-model usage through dynamic role assignment; AgentSched, a cache-aware hybrid scheduler that minimizes latency under heterogeneous request patterns; AgentSAM, a suffix-automaton-based speculative decoding method that reuses multi-session semantic memory to achieve low-overhead inference acceleration; and AgentCompress, a semantic compression mechanism that asynchronously distills and reorganizes agent memory without disrupting ongoing reasoning. Together, these modules form a Self-Evolution Engine capable of sustaining efficiency and cognitive stability throughout long-horizon reasoning tasks. Experiments on the BrowseComp-zh and DeepDiver benchmarks demonstrate that through the synergistic collaboration of these methods, AgentInfer reduces ineffective token consumption by over 50%, achieving an overall 1.8-2.5 times speedup with preserved accuracy. These results underscore that optimizing for agentic task completion-rather than merely per-token throughput-is the key to building scalable, efficient, and self-improving intelligent systems.
ArcGen: Generalizing Neural Backdoor Detection Across Diverse Architectures
Dec 17, 2025Backdoor attacks pose a significant threat to the security and reliability of deep learning models. To mitigate such attacks, one promising approach is to learn to extract features from the target model and use these features for backdoor detection. However, we discover that existing learning-based neural backdoor detection methods do not generalize well to new architectures not seen during the learning phase. In this paper, we analyze the root cause of this issue and propose a novel black-box neural backdoor detection method called ArcGen. Our method aims to obtain architecture-invariant model features, i.e., aligned features, for effective backdoor detection. Specifically, in contrast to existing methods directly using model outputs as model features, we introduce an additional alignment layer in the feature extraction function to further process these features. This reduces the direct influence of architecture information on the features. Then, we design two alignment losses to train the feature extraction function. These losses explicitly require that features from models with similar backdoor behaviors but different architectures are aligned at both the distribution and sample levels. With these techniques, our method demonstrates up to 42.5% improvements in detection performance (e.g., AUC) on unseen model architectures. This is based on a large-scale evaluation involving 16,896 models trained on diverse datasets, subjected to various backdoor attacks, and utilizing different model architectures. Our code is available at https://github.com/SeRAlab/ArcGen.
* 16 pages, 8 figures. This article was accepted by IEEE Transactions on Information Forensics and Security. DOI: 10.1109/TIFS.2025.3610254
Towards Efficient and Effective Multi-Camera Encoding for End-to-End Driving
Dec 12, 2025We present Flex, an efficient and effective scene encoder that addresses the computational bottleneck of processing high-volume multi-camera data in end-to-end autonomous driving. Flex employs a small set of learnable scene tokens to jointly encode information from all image tokens across different cameras and timesteps. By design, our approach is geometry-agnostic, learning a compact scene representation directly from data without relying on the explicit 3D inductive biases, such as Bird-Eye-View (BEV), occupancy or tri-plane representations, which are common in prior work. This holistic encoding strategy aggressively compresses the visual input for the downstream Large Language Model (LLM) based policy model. Evaluated on a large-scale proprietary dataset of 20,000 driving hours, our Flex achieves 2.2x greater inference throughput while improving driving performance by a large margin compared to state-of-the-art methods. Furthermore, we show that these compact scene tokens develop an emergent capability for scene decomposition without any explicit supervision. Our findings challenge the prevailing assumption that 3D priors are necessary, demonstrating that a data-driven, joint encoding strategy offers a more scalable, efficient and effective path for future autonomous driving systems.