 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS-BEVLoc: BEV-based Self-supervised Framework for Large-scale LiDAR Global Localization
Sep 11, 2025LiDAR-based global localization is an essential component of simultaneous localization and mapping (SLAM), which helps loop closure and re-localization. Current approaches rely on ground-truth poses obtained from GPS or SLAM odometry to supervise network training. Despite the great success of these supervised approaches, substantial cost and effort are required for high-precision ground-truth pose acquisition. In this work, we propose S-BEVLoc, a novel self-supervised framework based on bird's-eye view (BEV) for LiDAR global localization, which eliminates the need for ground-truth poses and is highly scalable. We construct training triplets from single BEV images by leveraging the known geographic distances between keypoint-centered BEV patches. Convolutional neural network (CNN) is used to extract local features, and NetVLAD is employed to aggregate global descriptors. Moreover, we introduce SoftCos loss to enhance learning from the generated triplets. Experimental results on the large-scale KITTI and NCLT datasets show that S-BEVLoc achieves state-of-the-art performance in place recognition, loop closure, and global localization tasks, while offering scalability that would require extra effort for supervised approaches.
CDFormer: Cross-Domain Few-Shot Object Detection Transformer Against Feature Confusion
May 02, 2025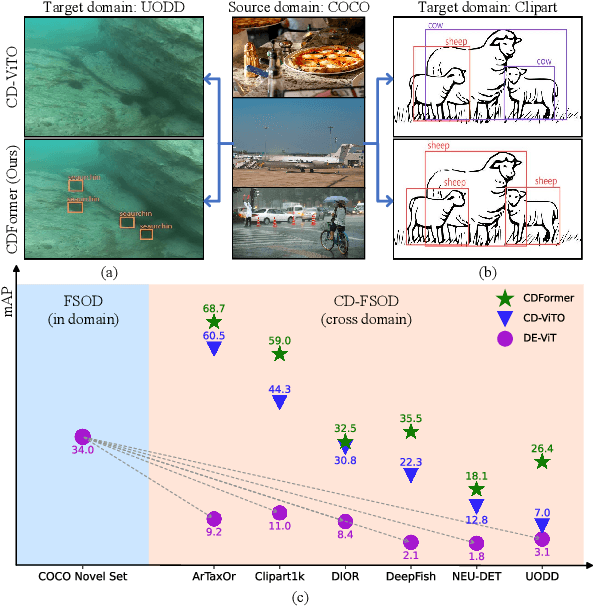
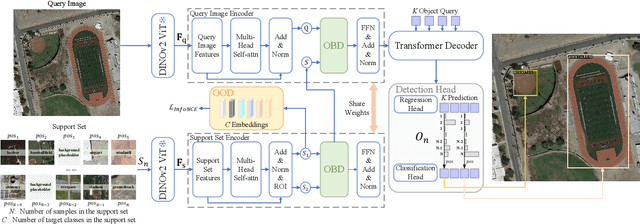

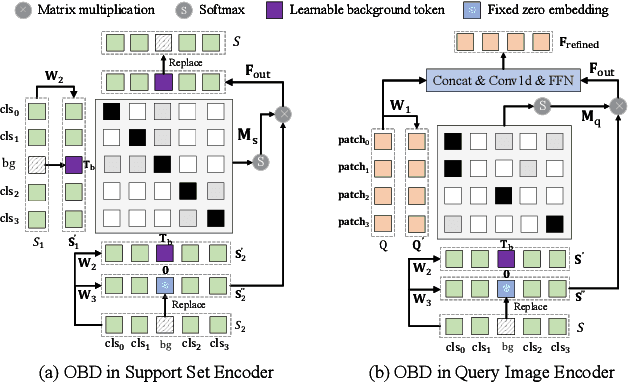
Cross-domain few-shot object detection (CD-FSOD) aims to detect novel objects across different domains with limited class instances. Feature confusion, including object-background confusion and object-object confusion, presents significant challenges in both cross-domain and few-shot settings. In this work, we introduce CDFormer, a cross-domain few-shot object detection transformer against feature confusion, to address these challenges. The method specifically tackles feature confusion through two key modules: object-background distinguishing (OBD) and object-object distinguishing (OOD). The OBD module leverages a learnable background token to differentiate between objects and background, while the OOD module enhances the distinction between objects of different classes. Experimental results demonstrate that CDFormer outperforms previous state-of-the-art approaches, achieving 12.9% mAP, 11.0% mAP, and 10.4% mAP improvements under the 1/5/10 shot settings, respectively, when fine-tuned.
SCPNet: Unsupervised Cross-modal Homography Estimation via Intra-modal Self-supervised Learning
Jul 11, 2024



We propose a novel unsupervised cross-modal homography estimation framework based on intra-modal Self-supervised learning, Correlation, and consistent feature map Projection, namely SCPNet. The concept of intra-modal self-supervised learning is first presented to facilitate the unsupervised cross-modal homography estimation. The correlation-based homography estimation network and the consistent feature map projection are combined to form the learnable architecture of SCPNet, boosting the unsupervised learning framework. SCPNet is the first to achieve effective unsupervised homography estimation on the satellite-map image pair cross-modal dataset, GoogleMap, under [-32,+32] offset on a 128x128 image, leading the supervised approach MHN by 14.0% of mean average corner error (MACE). We further conduct extensive experiments on several cross-modal/spectral and manually-made inconsistent datasets, on which SCPNet achieves the state-of-the-art (SOTA) performance among unsupervised approaches, and owns 49.0%, 25.2%, 36.4%, and 10.7% lower MACEs than the supervised approach MHN. Source code is available at https://github.com/RM-Zhang/SCPNet.
BEVPlace: Learning LiDAR-based Place Recognition using Bird's Eye View Images
Mar 15, 2023



Place recognition is a key module for long-term SLAM systems. Current LiDAR-based place recognition methods are usually based on representations of point clouds such as unordered points or range images. These methods achieve high recall rates of retrieval, but their performance may degrade in the case of view variation or scene changes. In this work, we explore the potential of a different representation in place recognition, i.e. bird's eye view (BEV) images. We observe that the structural contents of BEV images are less influenced by rotations and translations of point clouds. We validate that, without any delicate design, a simple VGGNet trained on BEV images achieves comparable performance with the state-of-the-art place recognition methods in scenes of slight viewpoint changes. For more robust place recognition, we design a rotation-invariant network called BEVPlace. We use group convolution to extract rotation-equivariant local features from the images and NetVLAD for global feature aggregation. In addition, we observe that the distance between BEV features is correlated with the geometry distance of point clouds. Based on the observation, we develop a method to estimate the position of the query cloud, extending the usage of place recognition. The experiments conducted on large-scale public datasets show that our method 1) achieves state-of-the-art performance in terms of recall rates, 2) is robust to view changes, 3) shows strong generalization ability, and 4) can estimate the positions of query point clouds. Source code will be made publicly available at https://github.com/zjuluolun/BEVPlace.
I2P-Rec: Recognizing Images on Large-scale Point Cloud Maps through Bird's Eye View Projections
Mar 02, 2023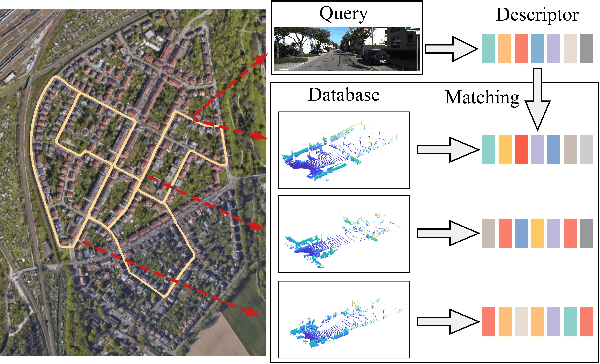
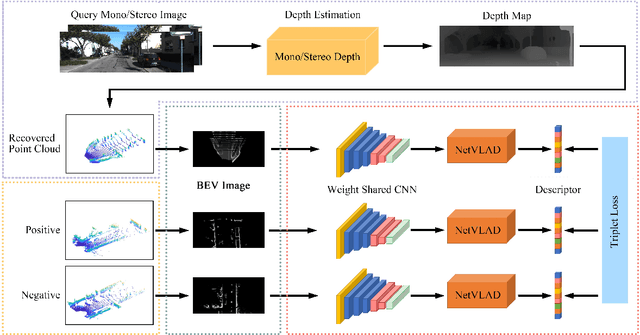
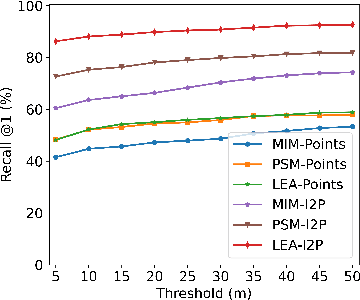

Place recognition is an important technique for autonomous cars to achieve full autonomy since it can provide an initial guess to online localization algorithms. Although current methods based on images or point clouds have achieved satisfactory performance, localizing the images on a large-scale point cloud map remains a fairly unexplored problem. This cross-modal matching task is challenging due to the difficulty in extracting consistent descriptors from images and point clouds. In this paper, we propose the I2P-Rec method to solve the problem by transforming the cross-modal data into the same modality. Specifically, we leverage on the recent success of depth estimation networks to recover point clouds from images. We then project the point clouds into Bird's Eye View (BEV) images. Using the BEV image as an intermediate representation, we extract global features with a Convolutional Neural Network followed by a NetVLAD layer to perform matching. We evaluate our method on the KITTI dataset. The experimental results show that, with only a small set of training data, I2P-Rec can achieve a recall rate at Top-1 over 90\%. Also, it can generalize well to unknown environments, achieving recall rates at Top-1\% over 80\% and 90\%, when localizing monocular images and stereo images on point cloud maps, respectively.