 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS-BEVLoc: BEV-based Self-supervised Framework for Large-scale LiDAR Global Localization
Sep 11, 2025LiDAR-based global localization is an essential component of simultaneous localization and mapping (SLAM), which helps loop closure and re-localization. Current approaches rely on ground-truth poses obtained from GPS or SLAM odometry to supervise network training. Despite the great success of these supervised approaches, substantial cost and effort are required for high-precision ground-truth pose acquisition. In this work, we propose S-BEVLoc, a novel self-supervised framework based on bird's-eye view (BEV) for LiDAR global localization, which eliminates the need for ground-truth poses and is highly scalable. We construct training triplets from single BEV images by leveraging the known geographic distances between keypoint-centered BEV patches. Convolutional neural network (CNN) is used to extract local features, and NetVLAD is employed to aggregate global descriptors. Moreover, we introduce SoftCos loss to enhance learning from the generated triplets. Experimental results on the large-scale KITTI and NCLT datasets show that S-BEVLoc achieves state-of-the-art performance in place recognition, loop closure, and global localization tasks, while offering scalability that would require extra effort for supervised approaches.
VoxDet: Rethinking 3D Semantic Occupancy Prediction as Dense Object Detection
Jun 05, 20253D semantic occupancy prediction aims to reconstruct the 3D geometry and semantics of the surrounding environment. With dense voxel labels, prior works typically formulate it as a dense segmentation task, independently classifying each voxel. However, this paradigm neglects critical instance-centric discriminability, leading to instance-level incompleteness and adjacent ambiguities. To address this, we highlight a free lunch of occupancy labels: the voxel-level class label implicitly provides insight at the instance level, which is overlooked by the community. Motivated by this observation, we first introduce a training-free Voxel-to-Instance (VoxNT) trick: a simple yet effective method that freely converts voxel-level class labels into instance-level offset labels. Building on this, we further propose VoxDet, an instance-centric framework that reformulates the voxel-level occupancy prediction as dense object detection by decoupling it into two sub-tasks: offset regression and semantic prediction. Specifically, based on the lifted 3D volume, VoxDet first uses (a) Spatially-decoupled Voxel Encoder to generate disentangled feature volumes for the two sub-tasks, which learn task-specific spatial deformation in the densely projected tri-perceptive space. Then, we deploy (b) Task-decoupled Dense Predictor to address this task via dense detection. Here, we first regress a 4D offset field to estimate distances (6 directions) between voxels and object borders in the voxel space. The regressed offsets are then used to guide the instance-level aggregation in the classification branch, achieving instance-aware prediction. Experiments show that VoxDet can be deployed on both camera and LiDAR input, jointly achieving state-of-the-art results on both benchmarks. VoxDet is not only highly efficient, but also achieves 63.0 IoU on the SemanticKITTI test set, ranking 1st on the online leaderboard.
Structure-Aware Radar-Camera Depth Estimation
Jun 05, 2025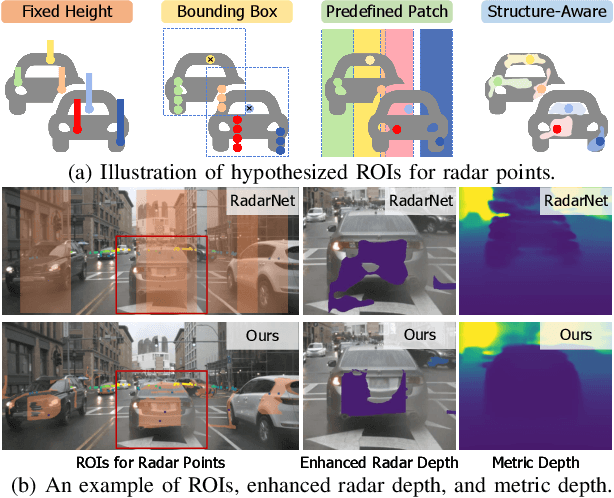
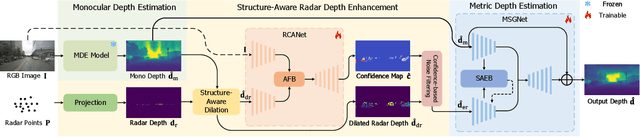
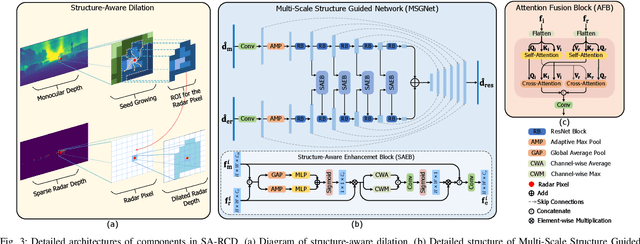
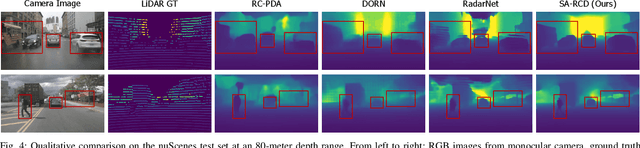
Monocular depth estimation aims to determine the depth of each pixel from an RGB image captured by a monocular camera. The development of deep learning has significantly advanced this field by facilitating the learning of depth features from some well-annotated datasets \cite{Geiger_Lenz_Stiller_Urtasun_2013,silberman2012indoor}. Eigen \textit{et al.} \cite{eigen2014depth} first introduce a multi-scale fusion network for depth regression. Following this, subsequent improvements have come from reinterpreting the regression task as a classification problem \cite{bhat2021adabins,Li_Wang_Liu_Jiang_2022}, incorporating additional priors \cite{shao2023nddepth,yang2023gedepth}, and developing more effective objective function \cite{xian2020structure,Yin_Liu_Shen_Yan_2019}. Despite these advances, generalizing to unseen domains remains a challenge. Recently, several methods have employed affine-invariant loss to enable multi-dataset joint training \cite{MiDaS,ZeroDepth,guizilini2023towards,Dany}. Among them, Depth Anything \cite{Dany} has shown leading performance in zero-shot monocular depth estimation. While it struggles to estimate accurate metric depth due to the lack of explicit depth cues, it excels at extracting structural information from unseen images, producing structure-detailed monocular depth.
Language Driven Occupancy Prediction
Nov 25, 2024



We introduce LOcc, an effective and generalizable framework for open-vocabulary occupancy (OVO) prediction. Previous approaches typically supervise the networks through coarse voxel-to-text correspondences via image features as intermediates or noisy and sparse correspondences from voxel-based model-view projections. To alleviate the inaccurate supervision, we propose a semantic transitive labeling pipeline to generate dense and finegrained 3D language occupancy ground truth. Our pipeline presents a feasible way to dig into the valuable semantic information of images, transferring text labels from images to LiDAR point clouds and utimately to voxels, to establish precise voxel-to-text correspondences. By replacing the original prediction head of supervised occupancy models with a geometry head for binary occupancy states and a language head for language features, LOcc effectively uses the generated language ground truth to guide the learning of 3D language volume. Through extensive experiments, we demonstrate that our semantic transitive labeling pipeline can produce more accurate pseudo-labeled ground truth, diminishing labor-intensive human annotations. Additionally, we validate LOcc across various architectures, where all models consistently outperform state-ofthe-art zero-shot occupancy prediction approaches on the Occ3D-nuScenes dataset. Notably, even based on the simpler BEVDet model, with an input resolution of 256 * 704,Occ-BEVDet achieves an mIoU of 20.29, surpassing previous approaches that rely on temporal images, higher-resolution inputs, or larger backbone networks. The code for the proposed method is available at https://github.com/pkqbajng/LOcc.
RestorerID: Towards Tuning-Free Face Restoration with ID Preservation
Nov 21, 2024



Blind face restoration has made great progress in producing high-quality and lifelike images. Yet it remains challenging to preserve the ID information especially when the degradation is heavy. Current reference-guided face restoration approaches either require face alignment or personalized test-tuning, which are unfaithful or time-consuming. In this paper, we propose a tuning-free method named RestorerID that incorporates ID preservation during face restoration. RestorerID is a diffusion model-based method that restores low-quality images with varying levels of degradation by using a single reference image. To achieve this, we propose a unified framework to combine the ID injection with the base blind face restoration model. In addition, we design a novel Face ID Rebalancing Adapter (FIR-Adapter) to tackle the problems of content unconsistency and contours misalignment that are caused by information conflicts between the low-quality input and reference image. Furthermore, by employing an Adaptive ID-Scale Adjusting strategy, RestorerID can produce superior restored images across various levels of degradation. Experimental results on the Celeb-Ref dataset and real-world scenarios demonstrate that RestorerID effectively delivers high-quality face restoration with ID preservation, achieving a superior performance compared to the test-tuning approaches and other reference-guided ones. The code of RestorerID is available at \url{https://github.com/YingJiacheng/RestorerID}.
InterNet: Unsupervised Cross-modal Homography Estimation Based on Interleaved Modality Transfer and Self-supervised Homography Prediction
Sep 26, 2024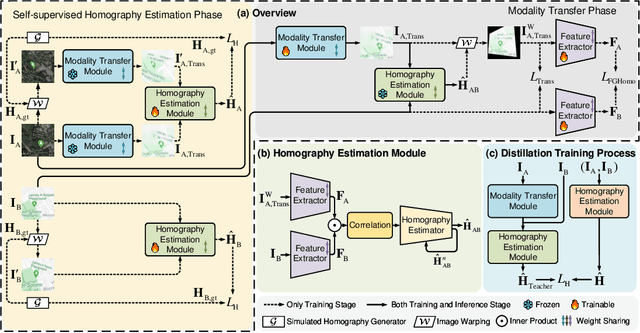
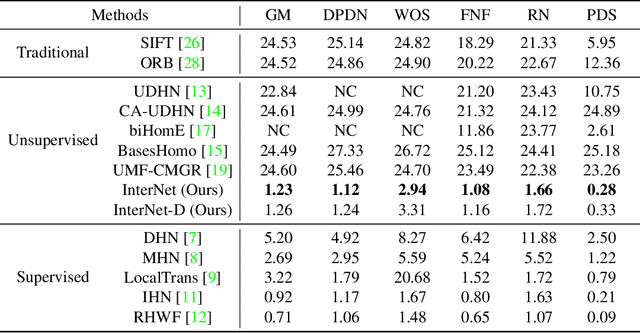


We propose a novel unsupervised cross-modal homography estimation framework, based on interleaved modality transfer and self-supervised homography prediction, named InterNet. InterNet integrates modality transfer and self-supervised homography estimation, introducing an innovative interleaved optimization framework to alternately promote both components. The modality transfer gradually narrows the modality gaps, facilitating the self-supervised homography estimation to fully leverage the synthetic intra-modal data. The self-supervised homography estimation progressively achieves reliable predictions, thereby providing robust cross-modal supervision for the modality transfer. To further boost the estimation accuracy, we also formulate a fine-grained homography feature loss to improve the connection between two components. Furthermore, we employ a simple yet effective distillation training technique to reduce model parameters and improve cross-domain generalization ability while maintaining comparable performance. Experiments reveal that InterNet achieves the state-of-the-art (SOTA) performance among unsupervised methods, and even outperforms many supervised methods such as MHN and LocalTrans.
BEVPlace++: Fast, Robust, and Lightweight LiDAR Global Localization for Unmanned Ground Vehicles
Aug 03, 2024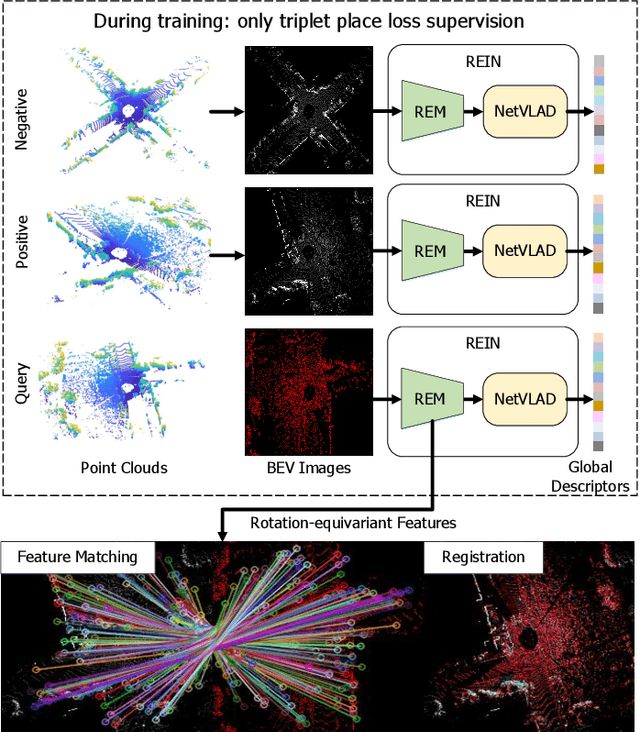
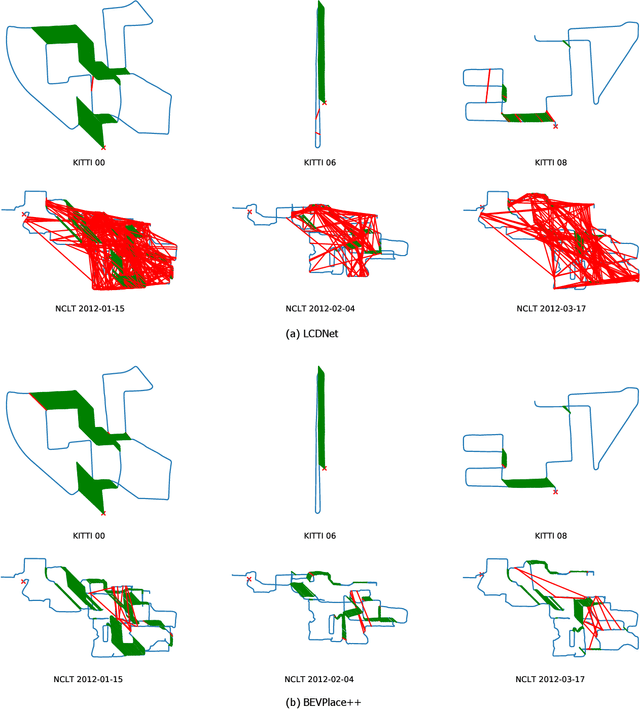
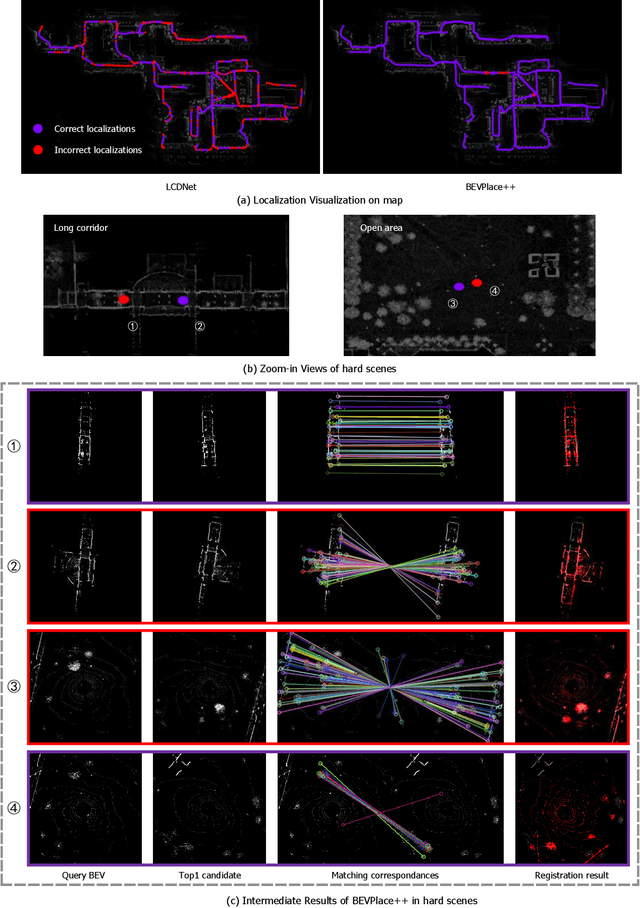
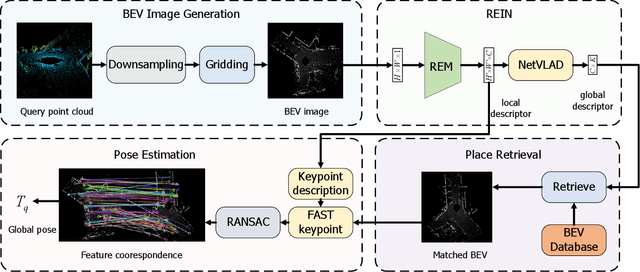
This article introduces BEVPlace++, a novel, fast, and robust LiDAR global localization method for unmanned ground vehicles. It uses lightweight convolutional neural networks (CNNs) on Bird's Eye View (BEV) image-like representations of LiDAR data to achieve accurate global localization through place recognition followed by 3-DoF pose estimation. Our detailed analyses reveal an interesting fact that CNNs are inherently effective at extracting distinctive features from LiDAR BEV images. Remarkably, keypoints of two BEV images with large translations can be effectively matched using CNN-extracted features. Building on this insight, we design a rotation equivariant module (REM) to obtain distinctive features while enhancing robustness to rotational changes. A Rotation Equivariant and Invariant Network (REIN) is then developed by cascading REM and a descriptor generator, NetVLAD, to sequentially generate rotation equivariant local features and rotation invariant global descriptors. The global descriptors are used first to achieve robust place recognition, and the local features are used for accurate pose estimation. Experimental results on multiple public datasets demonstrate that BEVPlace++, even when trained on a small dataset (3000 frames of KITTI) only with place labels, generalizes well to unseen environments, performs consistently across different days and years, and adapts to various types of LiDAR scanners. BEVPlace++ achieves state-of-the-art performance in subtasks of global localization including place recognition, loop closure detection, and global localization. Additionally, BEVPlace++ is lightweight, runs in real-time, and does not require accurate pose supervision, making it highly convenient for deployment. The source codes are publicly available at \href{https://github.com/zjuluolun/BEVPlace}{https://github.com/zjuluolun/BEVPlace}.
Context and Geometry Aware Voxel Transformer for Semantic Scene Completion
May 22, 2024



Vision-based Semantic Scene Completion (SSC) has gained much attention due to its widespread applications in various 3D perception tasks. Existing sparse-to-dense approaches typically employ shared context-independent queries across various input images, which fails to capture distinctions among them as the focal regions of different inputs vary and may result in undirected feature aggregation of cross-attention. Additionally, the absence of depth information may lead to points projected onto the image plane sharing the same 2D position or similar sampling points in the feature map, resulting in depth ambiguity. In this paper, we present a novel context and geometry aware voxel transformer. It utilizes a context aware query generator to initialize context-dependent queries tailored to individual input images, effectively capturing their unique characteristics and aggregating information within the region of interest. Furthermore, it extend deformable cross-attention from 2D to 3D pixel space, enabling the differentiation of points with similar image coordinates based on their depth coordinates. Building upon this module, we introduce a neural network named CGFormer to achieve semantic scene completion. Simultaneously, CGFormer leverages multiple 3D representations (i.e., voxel and TPV) to boost the semantic and geometric representation abilities of the transformed 3D volume from both local and global perspectives. Experimental results demonstrate that CGFormer achieves state-of-the-art performance on the SemanticKITTI and SSCBench-KITTI-360 benchmarks, attaining a mIoU of 16.87 and 20.05, as well as an IoU of 45.99 and 48.07, respectively. Remarkably, CGFormer even outperforms approaches employing temporal images as inputs or much larger image backbone networks. Code for the proposed method is available at https://github.com/pkqbajng/CGFormer.
SGDFormer: One-stage Transformer-based Architecture for Cross-Spectral Stereo Image Guided Denoising
Mar 30, 2024



Cross-spectral image guided denoising has shown its great potential in recovering clean images with rich details, such as using the near-infrared image to guide the denoising process of the visible one. To obtain such image pairs, a feasible and economical way is to employ a stereo system, which is widely used on mobile devices. Current works attempt to generate an aligned guidance image to handle the disparity between two images. However, due to occlusion, spectral differences and noise degradation, the aligned guidance image generally exists ghosting and artifacts, leading to an unsatisfactory denoised result. To address this issue, we propose a one-stage transformer-based architecture, named SGDFormer, for cross-spectral Stereo image Guided Denoising. The architecture integrates the correspondence modeling and feature fusion of stereo images into a unified network. Our transformer block contains a noise-robust cross-attention (NRCA) module and a spatially variant feature fusion (SVFF) module. The NRCA module captures the long-range correspondence of two images in a coarse-to-fine manner to alleviate the interference of noise. The SVFF module further enhances salient structures and suppresses harmful artifacts through dynamically selecting useful information. Thanks to the above design, our SGDFormer can restore artifact-free images with fine structures, and achieves state-of-the-art performance on various datasets. Additionally, our SGDFormer can be extended to handle other unaligned cross-model guided restoration tasks such as guided depth super-resolution.
I2P-Rec: Recognizing Images on Large-scale Point Cloud Maps through Bird's Eye View Projections
Mar 02, 2023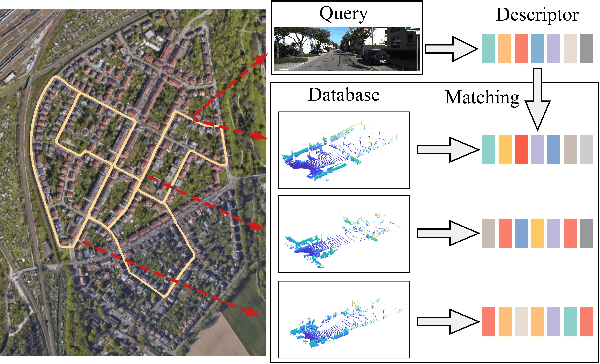
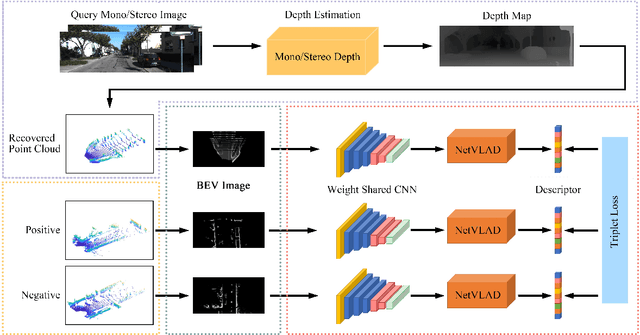
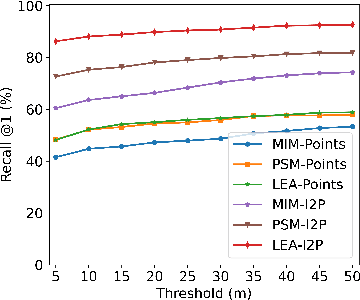

Place recognition is an important technique for autonomous cars to achieve full autonomy since it can provide an initial guess to online localization algorithms. Although current methods based on images or point clouds have achieved satisfactory performance, localizing the images on a large-scale point cloud map remains a fairly unexplored problem. This cross-modal matching task is challenging due to the difficulty in extracting consistent descriptors from images and point clouds. In this paper, we propose the I2P-Rec method to solve the problem by transforming the cross-modal data into the same modality. Specifically, we leverage on the recent success of depth estimation networks to recover point clouds from images. We then project the point clouds into Bird's Eye View (BEV) images. Using the BEV image as an intermediate representation, we extract global features with a Convolutional Neural Network followed by a NetVLAD layer to perform matching. We evaluate our method on the KITTI dataset. The experimental results show that, with only a small set of training data, I2P-Rec can achieve a recall rate at Top-1 over 90\%. Also, it can generalize well to unknown environments, achieving recall rates at Top-1\% over 80\% and 90\%, when localizing monocular images and stereo images on point cloud maps, respectively.