 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAIL: Self-Amplified Iterative Learning for Diffusion Model Alignment with Minimal Human Feedback
Feb 05, 2026Aligning diffusion models with human preferences remains challenging, particularly when reward models are unavailable or impractical to obtain, and collecting large-scale preference datasets is prohibitively expensive. \textit{This raises a fundamental question: can we achieve effective alignment using only minimal human feedback, without auxiliary reward models, by unlocking the latent capabilities within diffusion models themselves?} In this paper, we propose \textbf{SAIL} (\textbf{S}elf-\textbf{A}mplified \textbf{I}terative \textbf{L}earning), a novel framework that enables diffusion models to act as their own teachers through iterative self-improvement. Starting from a minimal seed set of human-annotated preference pairs, SAIL operates in a closed-loop manner where the model progressively generates diverse samples, self-annotates preferences based on its evolving understanding, and refines itself using this self-augmented dataset. To ensure robust learning and prevent catastrophic forgetting, we introduce a ranked preference mixup strategy that carefully balances exploration with adherence to initial human priors. Extensive experiments demonstrate that SAIL consistently outperforms state-of-the-art methods across multiple benchmarks while using merely 6\% of the preference data required by existing approaches, revealing that diffusion models possess remarkable self-improvement capabilities that, when properly harnessed, can effectively replace both large-scale human annotation and external reward models.
Exchange Is All You Need for Remote Sensing Change Detection
Jan 12, 2026Remote sensing change detection fundamentally relies on the effective fusion and discrimination of bi-temporal features. Prevailing paradigms typically utilize Siamese encoders bridged by explicit difference computation modules, such as subtraction or concatenation, to identify changes. In this work, we challenge this complexity with SEED (Siamese Encoder-Exchange-Decoder), a streamlined paradigm that replaces explicit differencing with parameter-free feature exchange. By sharing weights across both Siamese encoders and decoders, SEED effectively operates as a single parameter set model. Theoretically, we formalize feature exchange as an orthogonal permutation operator and prove that, under pixel consistency, this mechanism preserves mutual information and Bayes optimal risk, whereas common arithmetic fusion methods often introduce information loss. Extensive experiments across five benchmarks, including SYSU-CD, LEVIR-CD, PX-CLCD, WaterCD, and CDD, and three backbones, namely SwinT, EfficientNet, and ResNet, demonstrate that SEED matches or surpasses state of the art methods despite its simplicity. Furthermore, we reveal that standard semantic segmentation models can be transformed into competitive change detectors solely by inserting this exchange mechanism, referred to as SEG2CD. The proposed paradigm offers a robust, unified, and interpretable framework for change detection, demonstrating that simple feature exchange is sufficient for high performance information fusion. Code and full training and evaluation protocols will be released at https://github.com/dyzy41/open-rscd.
CustomVideoX: 3D Reference Attention Driven Dynamic Adaptation for Zero-Shot Customized Video Diffusion Transformers
Feb 10, 2025Customized generation has achieved significant progress in image synthesis, yet personalized video generation remains challenging due to temporal inconsistencies and quality degradation. In this paper, we introduce CustomVideoX, an innovative framework leveraging the video diffusion transformer for personalized video generation from a reference image. CustomVideoX capitalizes on pre-trained video networks by exclusively training the LoRA parameters to extract reference features, ensuring both efficiency and adaptability. To facilitate seamless interaction between the reference image and video content, we propose 3D Reference Attention, which enables direct and simultaneous engagement of reference image features with all video frames across spatial and temporal dimensions. To mitigate the excessive influence of reference image features and textual guidance on generated video content during inference, we implement the Time-Aware Reference Attention Bias (TAB) strategy, dynamically modulating reference bias over different time steps. Additionally, we introduce the Entity Region-Aware Enhancement (ERAE) module, aligning highly activated regions of key entity tokens with reference feature injection by adjusting attention bias. To thoroughly evaluate personalized video generation, we establish a new benchmark, VideoBench, comprising over 50 objects and 100 prompts for extensive assessment. Experimental results show that CustomVideoX significantly outperforms existing methods in terms of video consistency and quality.
A Remote Sensing Image Change Detection Method Integrating Layer Exchange and Channel-Spatial Differences
Jan 19, 2025



Change detection in remote sensing imagery is a critical technique for Earth observation, primarily focusing on pixel-level segmentation of change regions between bi-temporal images. The essence of pixel-level change detection lies in determining whether corresponding pixels in bi-temporal images have changed. In deep learning, the spatial and channel dimensions of feature maps represent different information from the original images. In this study, we found that in change detection tasks, difference information can be computed not only from the spatial dimension of bi-temporal features but also from the channel dimension. Therefore, we designed the Channel-Spatial Difference Weighting (CSDW) module as an aggregation-distribution mechanism for bi-temporal features in change detection. This module enhances the sensitivity of the change detection model to difference features. Additionally, bi-temporal images share the same geographic location and exhibit strong inter-image correlations. To construct the correlation between bi-temporal images, we designed a decoding structure based on the Layer-Exchange (LE) method to enhance the interaction of bi-temporal features. Comprehensive experiments on the CLCD, PX-CLCD, LEVIR-CD, and S2Looking datasets demonstrate that the proposed LENet model significantly improves change detection performance. The code and pre-trained models will be available at: https://github.com/dyzy41/lenet.
RestorerID: Towards Tuning-Free Face Restoration with ID Preservation
Nov 21, 2024



Blind face restoration has made great progress in producing high-quality and lifelike images. Yet it remains challenging to preserve the ID information especially when the degradation is heavy. Current reference-guided face restoration approaches either require face alignment or personalized test-tuning, which are unfaithful or time-consuming. In this paper, we propose a tuning-free method named RestorerID that incorporates ID preservation during face restoration. RestorerID is a diffusion model-based method that restores low-quality images with varying levels of degradation by using a single reference image. To achieve this, we propose a unified framework to combine the ID injection with the base blind face restoration model. In addition, we design a novel Face ID Rebalancing Adapter (FIR-Adapter) to tackle the problems of content unconsistency and contours misalignment that are caused by information conflicts between the low-quality input and reference image. Furthermore, by employing an Adaptive ID-Scale Adjusting strategy, RestorerID can produce superior restored images across various levels of degradation. Experimental results on the Celeb-Ref dataset and real-world scenarios demonstrate that RestorerID effectively delivers high-quality face restoration with ID preservation, achieving a superior performance compared to the test-tuning approaches and other reference-guided ones. The code of RestorerID is available at \url{https://github.com/YingJiacheng/RestorerID}.
Resolving Multi-Condition Confusion for Finetuning-Free Personalized Image Generation
Sep 26, 2024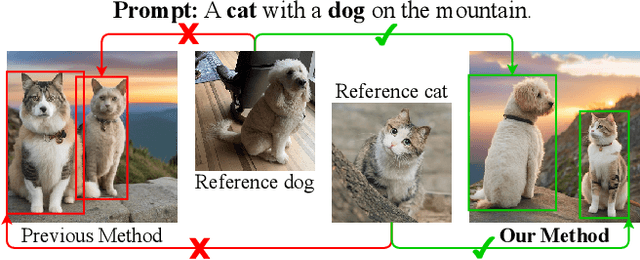

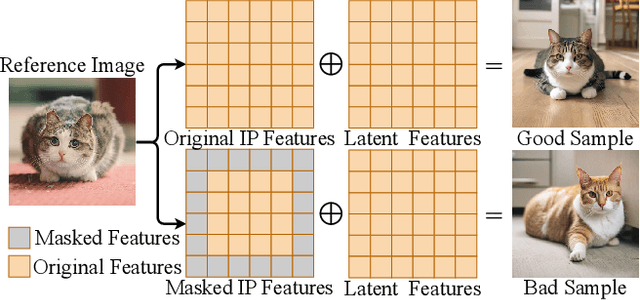
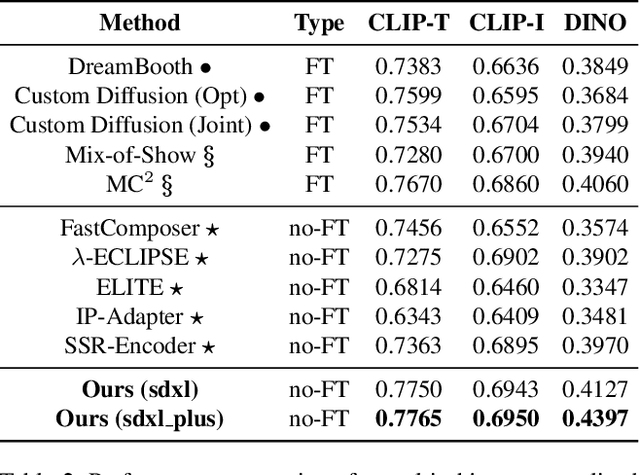
Personalized text-to-image generation methods can generate customized images based on the reference images, which have garnered wide research interest. Recent methods propose a finetuning-free approach with a decoupled cross-attention mechanism to generate personalized images requiring no test-time finetuning. However, when multiple reference images are provided, the current decoupled cross-attention mechanism encounters the object confusion problem and fails to map each reference image to its corresponding object, thereby seriously limiting its scope of application. To address the object confusion problem, in this work we investigate the relevance of different positions of the latent image features to the target object in diffusion model, and accordingly propose a weighted-merge method to merge multiple reference image features into the corresponding objects. Next, we integrate this weighted-merge method into existing pre-trained models and continue to train the model on a multi-object dataset constructed from the open-sourced SA-1B dataset. To mitigate object confusion and reduce training costs, we propose an object quality score to estimate the image quality for the selection of high-quality training samples. Furthermore, our weighted-merge training framework can be employed on single-object generation when a single object has multiple reference images. The experiments verify that our method achieves superior performance to the state-of-the-arts on the Concept101 dataset and DreamBooth dataset of multi-object personalized image generation, and remarkably improves the performance on single-object personalized image generation. Our code is available at https://github.com/hqhQAQ/MIP-Adapter.
LLaVA-MoD: Making LLaVA Tiny via MoE Knowledge Distillation
Aug 28, 2024We introduce LLaVA-MoD, a novel framework designed to enable the efficient training of small-scale Multimodal Language Models (s-MLLM) by distilling knowledge from large-scale MLLM (l-MLLM). Our approach tackles two fundamental challenges in MLLM distillation. First, we optimize the network structure of s-MLLM by integrating a sparse Mixture of Experts (MoE) architecture into the language model, striking a balance between computational efficiency and model expressiveness. Second, we propose a progressive knowledge transfer strategy to ensure comprehensive knowledge migration. This strategy begins with mimic distillation, where we minimize the Kullback-Leibler (KL) divergence between output distributions to enable the student model to emulate the teacher network's understanding. Following this, we introduce preference distillation via Direct Preference Optimization (DPO), where the key lies in treating l-MLLM as the reference model. During this phase, the s-MLLM's ability to discriminate between superior and inferior examples is significantly enhanced beyond l-MLLM, leading to a better student that surpasses its teacher, particularly in hallucination benchmarks. Extensive experiments demonstrate that LLaVA-MoD outperforms existing models across various multimodal benchmarks while maintaining a minimal number of activated parameters and low computational costs. Remarkably, LLaVA-MoD, with only 2B activated parameters, surpasses Qwen-VL-Chat-7B by an average of 8.8% across benchmarks, using merely 0.3% of the training data and 23% trainable parameters. These results underscore LLaVA-MoD's ability to effectively distill comprehensive knowledge from its teacher model, paving the way for the development of more efficient MLLMs. The code will be available on: https://github.com/shufangxun/LLaVA-MoD.
MARS: Mixture of Auto-Regressive Models for Fine-grained Text-to-image Synthesis
Jul 11, 2024



Auto-regressive models have made significant progress in the realm of language generation, yet they do not perform on par with diffusion models in the domain of image synthesis. In this work, we introduce MARS, a novel framework for T2I generation that incorporates a specially designed Semantic Vision-Language Integration Expert (SemVIE). This innovative component integrates pre-trained LLMs by independently processing linguistic and visual information, freezing the textual component while fine-tuning the visual component. This methodology preserves the NLP capabilities of LLMs while imbuing them with exceptional visual understanding. Building upon the powerful base of the pre-trained Qwen-7B, MARS stands out with its bilingual generative capabilities corresponding to both English and Chinese language prompts and the capacity for joint image and text generation. The flexibility of this framework lends itself to migration towards any-to-any task adaptability. Furthermore, MARS employs a multi-stage training strategy that first establishes robust image-text alignment through complementary bidirectional tasks and subsequently concentrates on refining the T2I generation process, significantly augmenting text-image synchrony and the granularity of image details. Notably, MARS requires only 9% of the GPU days needed by SD1.5, yet it achieves remarkable results across a variety of benchmarks, illustrating the training efficiency and the potential for swift deployment in various applications.
MS-Diffusion: Multi-subject Zero-shot Image Personalization with Layout Guidance
Jun 11, 2024



Recent advancements in text-to-image generation models have dramatically enhanced the generation of photorealistic images from textual prompts, leading to an increased interest in personalized text-to-image applications, particularly in multi-subject scenarios. However, these advances are hindered by two main challenges: firstly, the need to accurately maintain the details of each referenced subject in accordance with the textual descriptions; and secondly, the difficulty in achieving a cohesive representation of multiple subjects in a single image without introducing inconsistencies. To address these concerns, our research introduces the MS-Diffusion framework for layout-guided zero-shot image personalization with multi-subjects. This innovative approach integrates grounding tokens with the feature resampler to maintain detail fidelity among subjects. With the layout guidance, MS-Diffusion further improves the cross-attention to adapt to the multi-subject inputs, ensuring that each subject condition acts on specific areas. The proposed multi-subject cross-attention orchestrates harmonious inter-subject compositions while preserving the control of texts. Comprehensive quantitative and qualitative experiments affirm that this method surpasses existing models in both image and text fidelity, promoting the development of personalized text-to-image generation.
TrainerAgent: Customizable and Efficient Model Training through LLM-Powered Multi-Agent System
Nov 23, 2023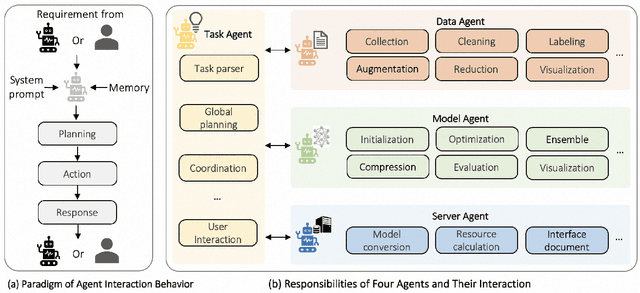
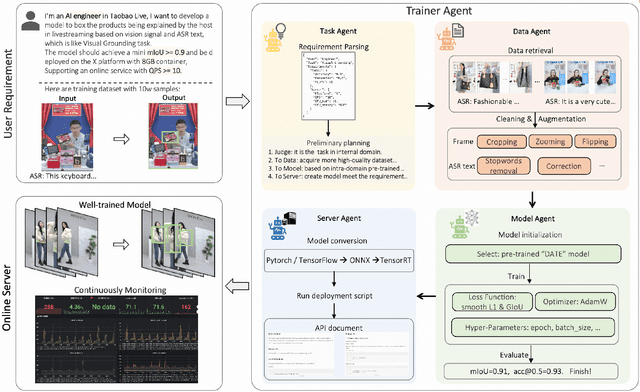
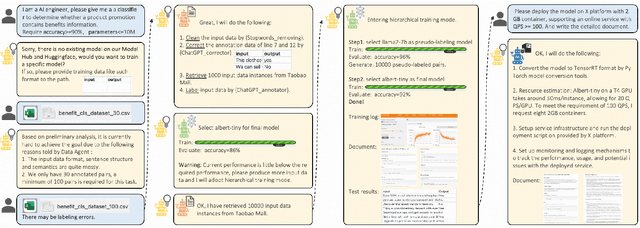
Training AI models has always been challenging, especially when there is a need for custom models to provide personalized services. Algorithm engineers often face a lengthy process to iteratively develop models tailored to specific business requirements, making it even more difficult for non-experts. The quest for high-quality and efficient model development, along with the emergence of Large Language Model (LLM) Agents, has become a key focus in the industry. Leveraging the powerful analytical, planning, and decision-making capabilities of LLM, we propose a TrainerAgent system comprising a multi-agent framework including Task, Data, Model and Server agents. These agents analyze user-defined tasks, input data, and requirements (e.g., accuracy, speed), optimizing them comprehensively from both data and model perspectives to obtain satisfactory models, and finally deploy these models as online service. Experimental evaluations on classical discriminative and generative tasks in computer vision and natural language processing domains demonstrate that our system consistently produces models that meet the desired criteria. Furthermore, the system exhibits the ability to critically identify and reject unattainable tasks, such as fantastical scenarios or unethical requests, ensuring robustness and safety. This research presents a significant advancement in achieving desired models with increased efficiency and quality as compared to traditional model development, facilitated by the integration of LLM-powered analysis, decision-making, and execution capabilities, as well as the collaboration among four agents. We anticipate that our work will contribute to the advancement of research on TrainerAgent in both academic and industry communities, potentially establishing it as a new paradigm for model development in the field of AI.