 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple Yet Effective Selective Imputation for Incomplete Multi-view Clustering
Dec 11, 2025Incomplete multi-view data, where different views suffer from missing and unbalanced observations, pose significant challenges for clustering. Existing imputation-based methods attempt to estimate missing views to restore data associations, but indiscriminate imputation often introduces noise and bias, especially when the available information is insufficient. Imputation-free methods avoid this risk by relying solely on observed data, but struggle under severe incompleteness due to the lack of cross-view complementarity. To address this issue, we propose Informativeness-based Selective imputation Multi-View Clustering (ISMVC). Our method evaluates the imputation-relevant informativeness of each missing position based on intra-view similarity and cross-view consistency, and selectively imputes only when sufficient support is available. Furthermore, we integrate this selection with a variational autoencoder equipped with a mixture-of-Gaussians prior to learn clustering-friendly latent representations. By performing distribution-level imputation, ISMVC not only stabilizes the aggregation of posterior distributions but also explicitly models imputation uncertainty, enabling robust fusion and preventing overconfident reconstructions. Compared with existing cautious imputation strategies that depend on training dynamics or model feedback, our method is lightweight, data-driven, and model-agnostic. It can be readily integrated into existing IMC models as a plug-in module. Extensive experiments on multiple benchmark datasets under a more realistic and challenging unbalanced missing scenario demonstrate that our method outperforms both imputation-based and imputation-free approaches.
Boosting MLLM Reasoning with Text-Debiased Hint-GRPO
Mar 31, 2025MLLM reasoning has drawn widespread research for its excellent problem-solving capability. Current reasoning methods fall into two types: PRM, which supervises the intermediate reasoning steps, and ORM, which supervises the final results. Recently, DeepSeek-R1 has challenged the traditional view that PRM outperforms ORM, which demonstrates strong generalization performance using an ORM method (i.e., GRPO). However, current MLLM's GRPO algorithms still struggle to handle challenging and complex multimodal reasoning tasks (e.g., mathematical reasoning). In this work, we reveal two problems that impede the performance of GRPO on the MLLM: Low data utilization and Text-bias. Low data utilization refers to that GRPO cannot acquire positive rewards to update the MLLM on difficult samples, and text-bias is a phenomenon that the MLLM bypasses image condition and solely relies on text condition for generation after GRPO training. To tackle these problems, this work proposes Hint-GRPO that improves data utilization by adaptively providing hints for samples of varying difficulty, and text-bias calibration that mitigates text-bias by calibrating the token prediction logits with image condition in test-time. Experiment results on three base MLLMs across eleven datasets demonstrate that our proposed methods advance the reasoning capability of original MLLM by a large margin, exhibiting superior performance to existing MLLM reasoning methods. Our code is available at https://github.com/hqhQAQ/Hint-GRPO.
PatchDPO: Patch-level DPO for Finetuning-free Personalized Image Generation
Dec 04, 2024



Finetuning-free personalized image generation can synthesize customized images without test-time finetuning, attracting wide research interest owing to its high efficiency. Current finetuning-free methods simply adopt a single training stage with a simple image reconstruction task, and they typically generate low-quality images inconsistent with the reference images during test-time. To mitigate this problem, inspired by the recent DPO (i.e., direct preference optimization) technique, this work proposes an additional training stage to improve the pre-trained personalized generation models. However, traditional DPO only determines the overall superiority or inferiority of two samples, which is not suitable for personalized image generation because the generated images are commonly inconsistent with the reference images only in some local image patches. To tackle this problem, this work proposes PatchDPO that estimates the quality of image patches within each generated image and accordingly trains the model. To this end, PatchDPO first leverages the pre-trained vision model with a proposed self-supervised training method to estimate the patch quality. Next, PatchDPO adopts a weighted training approach to train the model with the estimated patch quality, which rewards the image patches with high quality while penalizing the image patches with low quality. Experiment results demonstrate that PatchDPO significantly improves the performance of multiple pre-trained personalized generation models, and achieves state-of-the-art performance on both single-object and multi-object personalized image generation. Our code is available at https://github.com/hqhQAQ/PatchDPO.
Resolving Multi-Condition Confusion for Finetuning-Free Personalized Image Generation
Sep 26, 2024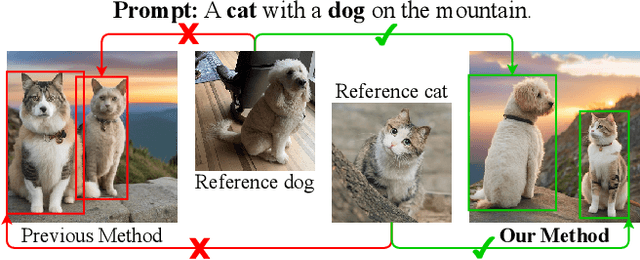

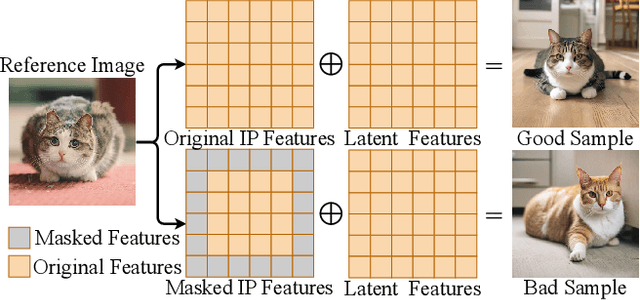
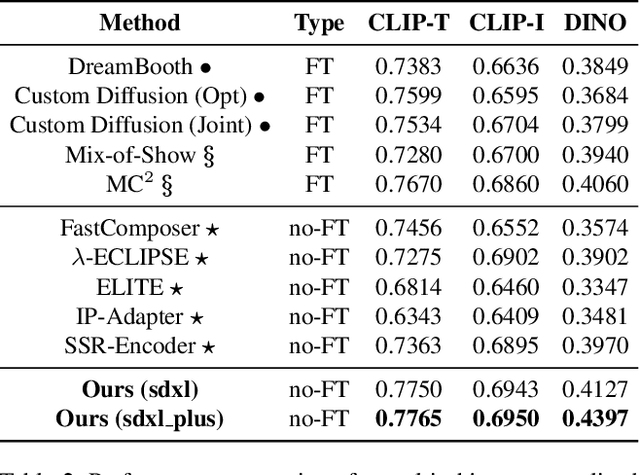
Personalized text-to-image generation methods can generate customized images based on the reference images, which have garnered wide research interest. Recent methods propose a finetuning-free approach with a decoupled cross-attention mechanism to generate personalized images requiring no test-time finetuning. However, when multiple reference images are provided, the current decoupled cross-attention mechanism encounters the object confusion problem and fails to map each reference image to its corresponding object, thereby seriously limiting its scope of application. To address the object confusion problem, in this work we investigate the relevance of different positions of the latent image features to the target object in diffusion model, and accordingly propose a weighted-merge method to merge multiple reference image features into the corresponding objects. Next, we integrate this weighted-merge method into existing pre-trained models and continue to train the model on a multi-object dataset constructed from the open-sourced SA-1B dataset. To mitigate object confusion and reduce training costs, we propose an object quality score to estimate the image quality for the selection of high-quality training samples. Furthermore, our weighted-merge training framework can be employed on single-object generation when a single object has multiple reference images. The experiments verify that our method achieves superior performance to the state-of-the-arts on the Concept101 dataset and DreamBooth dataset of multi-object personalized image generation, and remarkably improves the performance on single-object personalized image generation. Our code is available at https://github.com/hqhQAQ/MIP-Adapter.
Accelerating Large Batch Training via Gradient Signal to Noise Ratio (GSNR)
Sep 24, 2023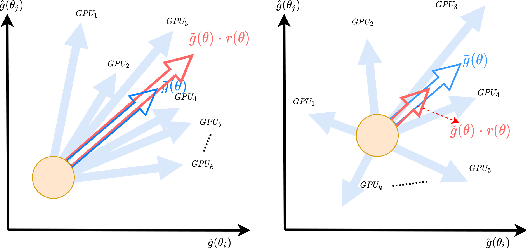
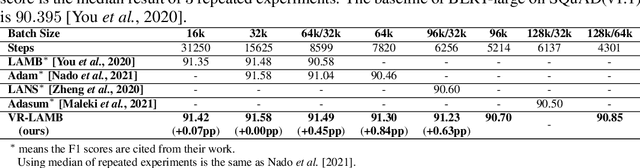
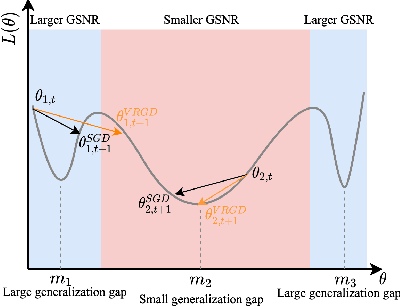

As models for nature language processing (NLP), computer vision (CV) and recommendation systems (RS) require surging computation, a large number of GPUs/TPUs are paralleled as a large batch (LB) to improve training throughput. However, training such LB tasks often meets large generalization gap and downgrades final precision, which limits enlarging the batch size. In this work, we develop the variance reduced gradient descent technique (VRGD) based on the gradient signal to noise ratio (GSNR) and apply it onto popular optimizers such as SGD/Adam/LARS/LAMB. We carry out a theoretical analysis of convergence rate to explain its fast training dynamics, and a generalization analysis to demonstrate its smaller generalization gap on LB training. Comprehensive experiments demonstrate that VRGD can accelerate training ($1\sim 2 \times$), narrow generalization gap and improve final accuracy. We push the batch size limit of BERT pretraining up to 128k/64k and DLRM to 512k without noticeable accuracy loss. We improve ImageNet Top-1 accuracy at 96k by $0.52pp$ than LARS. The generalization gap of BERT and ImageNet training is significantly reduce by over $65\%$.
OPV2V: An Open Benchmark Dataset and Fusion Pipeline for Perception with Vehicle-to-Vehicle Communication
Sep 17, 2021

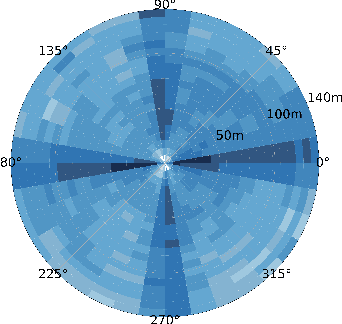
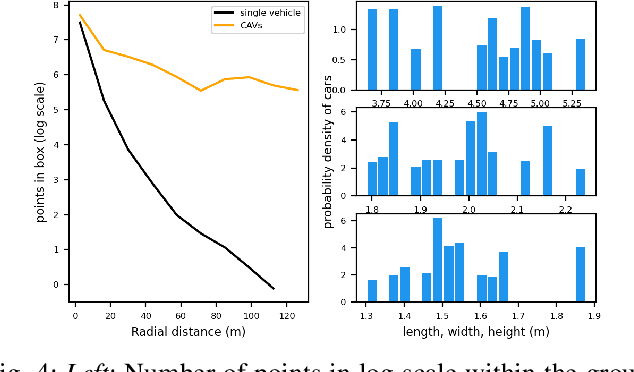
Employing Vehicle-to-Vehicle communication to enhance perception performance in self-driving technology has attracted considerable attention recently; however, the absence of a suitable open dataset for benchmarking algorithms has made it difficult to develop and assess cooperative perception technologies. To this end, we present the first large-scale open simulated dataset for Vehicle-to-Vehicle perception. It contains over 70 interesting scenes, 11,464 frames, and 232,913 annotated 3D vehicle bounding boxes, collected from 8 towns in CARLA and a digital town of Culver City, Los Angeles. We then construct a comprehensive benchmark with a total of 16 implemented models to evaluate several information fusion strategies~(i.e. early, late, and intermediate fusion) with state-of-the-art LiDAR detection algorithms. Moreover, we propose a new Attentive Intermediate Fusion pipeline to aggregate information from multiple connected vehicles. Our experiments show that the proposed pipeline can be easily integrated with existing 3D LiDAR detectors and achieve outstanding performance even with large compression rates. To encourage more researchers to investigate Vehicle-to-Vehicle perception, we will release the dataset, benchmark methods, and all related codes in https://mobility-lab.seas.ucla.edu/opv2v/.
Transforming the Latent Space of StyleGAN for Real Face Editing
May 29, 2021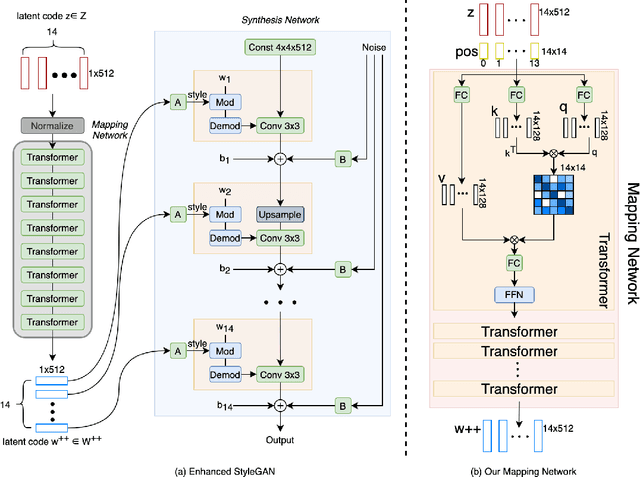

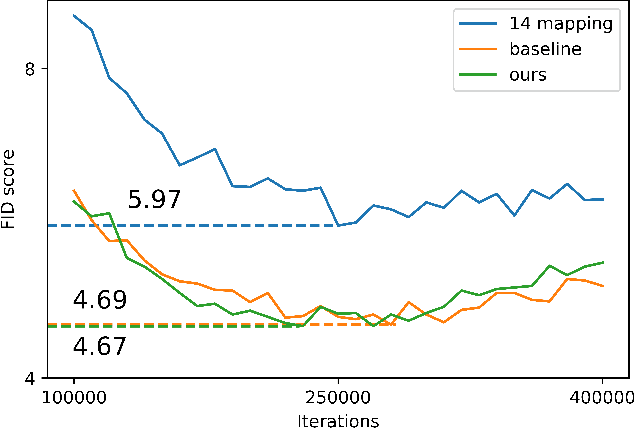

Despite recent advances in semantic manipulation using StyleGAN, semantic editing of real faces remains challenging. The gap between the $W$ space and the $W$+ space demands an undesirable trade-off between reconstruction quality and editing quality. To solve this problem, we propose to expand the latent space by replacing fully-connected layers in the StyleGAN's mapping network with attention-based transformers. This simple and effective technique integrates the aforementioned two spaces and transforms them into one new latent space called $W$++. Our modified StyleGAN maintains the state-of-the-art generation quality of the original StyleGAN with moderately better diversity. But more importantly, the proposed $W$++ space achieves superior performance in both reconstruction quality and editing quality. Despite these significant advantages, our $W$++ space supports existing inversion algorithms and editing methods with only negligible modifications thanks to its structural similarity with the $W/W$+ space. Extensive experiments on the FFHQ dataset prove that our proposed $W$++ space is evidently more preferable than the previous $W/W$+ space for real face editing. The code is publicly available for research purposes at https://github.com/AnonSubm2021/TransStyleGAN.
Investigating Label Bias in Beam Search for Open-ended Text Generation
May 22, 2020



Beam search is an effective and widely used decoding algorithm in many sequence-to-sequence (seq2seq) text generation tasks. However, in open-ended text generation, beam search is often found to produce repetitive and generic texts, sampling-based decoding algorithms like top-k sampling and nucleus sampling are more preferred. Standard seq2seq models suffer from label bias due to its locally normalized probability formulation. This paper provides a series of empirical evidence that label bias is a major reason for such degenerate behaviors of beam search. By combining locally normalized maximum likelihood estimation and globally normalized sequence-level training, label bias can be reduced with almost no sacrifice in perplexity. To quantitatively measure label bias, we test the model's ability to discriminate the groundtruth text and a set of context-agnostic distractors. We conduct experiments on large-scale response generation datasets. Results show that beam search can produce more diverse and meaningful texts with our approach, in terms of both automatic and human evaluation metrics. Our analysis also suggests several future working directions towards the grand challenge of open-ended text generation.
Understanding Why Neural Networks Generalize Well Through GSNR of Parameters
Feb 24, 2020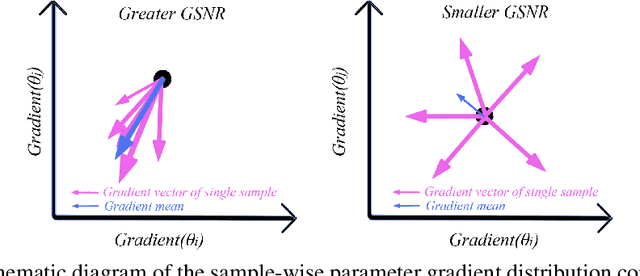
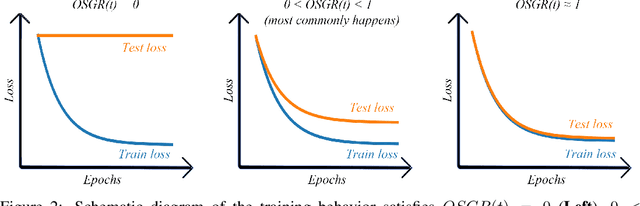

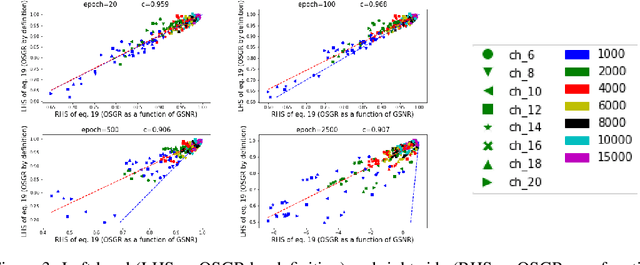
As deep neural networks (DNNs) achieve tremendous success across many application domains, researchers tried to explore in many aspects on why they generalize well. In this paper, we provide a novel perspective on these issues using the gradient signal to noise ratio (GSNR) of parameters during training process of DNNs. The GSNR of a parameter is defined as the ratio between its gradient's squared mean and variance, over the data distribution. Based on several approximations, we establish a quantitative relationship between model parameters' GSNR and the generalization gap. This relationship indicates that larger GSNR during training process leads to better generalization performance. Moreover, we show that, different from that of shallow models (e.g. logistic regression, support vector machines), the gradient descent optimization dynamics of DNNs naturally produces large GSNR during training, which is probably the key to DNNs' remarkable generalization ability.