 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridgeSim: Unveiling the OL-CL Gap in End-to-End Autonomous Driving
Apr 12, 2026Open-loop (OL) to closed-loop (CL) gap (OL-CL gap) exists when OL-pretrained policies scoring high in OL evaluations fail to transfer effectively in closed-loop (CL) deployment. In this paper, we unveil the root causes of this systemic failure and propose a practical remedy. Specifically, we demonstrate that OL policies suffer from Observational Domain Shift and Objective Mismatch. We show that while the former is largely recoverable with adaptation techniques, the latter creates a structural inability to model complex reactive behaviors, which forms the primary OL-CL gap. We find that a wide range of OL policies learn a biased Q-value estimator that neglects both the reactive nature of CL simulations and the temporal awareness needed to reduce compounding errors. To this end, we propose a Test-Time Adaptation (TTA) framework that calibrates observational shift, reduces state-action biases, and enforces temporal consistency. Extensive experiments show that TTA effectively mitigates planning biases and yields superior scaling dynamics than its baseline counterparts. Furthermore, our analysis highlights the existence of blind spots in standard OL evaluation protocols that fail to capture the realities of closed-loop deployment.
The Eleventh NTIRE 2026 Efficient Super-Resolution Challenge Report
Apr 03, 2026This paper reviews the NTIRE 2026 challenge on efficient single-image super-resolution with a focus on the proposed solutions and results. The aim of this challenge is to devise a network that reduces one or several aspects, such as runtime, parameters, and FLOPs, while maintaining PSNR of around 26.90 dB on the DIV2K_LSDIR_valid dataset, and 26.99 dB on the DIV2K_LSDIR_test dataset. The challenge had 95 registered participants, and 15 teams made valid submissions. They gauge the state-of-the-art results for efficient single-image super-resolution.
Copyright Detective: A Forensic System to Evidence LLMs Flickering Copyright Leakage Risks
Feb 05, 2026We present Copyright Detective, the first interactive forensic system for detecting, analyzing, and visualizing potential copyright risks in LLM outputs. The system treats copyright infringement versus compliance as an evidence discovery process rather than a static classification task due to the complex nature of copyright law. It integrates multiple detection paradigms, including content recall testing, paraphrase-level similarity analysis, persuasive jailbreak probing, and unlearning verification, within a unified and extensible framework. Through interactive prompting, response collection, and iterative workflows, our system enables systematic auditing of verbatim memorization and paraphrase-level leakage, supporting responsible deployment and transparent evaluation of LLM copyright risks even with black-box access.
Audit After Segmentation: Reference-Free Mask Quality Assessment for Language-Referred Audio-Visual Segmentation
Feb 03, 2026Language-referred audio-visual segmentation (Ref-AVS) aims to segment target objects described by natural language by jointly reasoning over video, audio, and text. Beyond generating segmentation masks, providing rich and interpretable diagnoses of mask quality remains largely underexplored. In this work, we introduce Mask Quality Assessment in the Ref-AVS context (MQA-RefAVS), a new task that evaluates the quality of candidate segmentation masks without relying on ground-truth annotations as references at inference time. Given audio-visual-language inputs and each provided segmentation mask, the task requires estimating its IoU with the unobserved ground truth, identifying the corresponding error type, and recommending an actionable quality-control decision. To support this task, we construct MQ-RAVSBench, a benchmark featuring diverse and representative mask error modes that span both geometric and semantic issues. We further propose MQ-Auditor, a multimodal large language model (MLLM)-based auditor that explicitly reasons over multimodal cues and mask information to produce quantitative and qualitative mask quality assessments. Extensive experiments demonstrate that MQ-Auditor outperforms strong open-source and commercial MLLMs and can be integrated with existing Ref-AVS systems to detect segmentation failures and support downstream segmentation improvement. Data and codes will be released at https://github.com/jasongief/MQA-RefAVS.
TIC-VLA: A Think-in-Control Vision-Language-Action Model for Robot Navigation in Dynamic Environments
Feb 02, 2026Robots in dynamic, human-centric environments must follow language instructions while maintaining real-time reactive control. Vision-language-action (VLA) models offer a promising framework, but they assume temporally aligned reasoning and control, despite semantic inference being inherently delayed relative to real-time action. We introduce Think-in-Control (TIC)-VLA, a latency-aware framework that explicitly models delayed semantic reasoning during action generation. TIC-VLA defines a delayed semantic-control interface that conditions action generation on delayed vision-language semantic states and explicit latency metadata, in addition to current observations, enabling policies to compensate for asynchronous reasoning. We further propose a latency-consistent training pipeline that injects reasoning inference delays during imitation learning and online reinforcement learning, aligning training with asynchronous deployment. To support realistic evaluation, we present DynaNav, a physics-accurate, photo-realistic simulation suite for language-guided navigation in dynamic environments. Extensive experiments in simulation and on a real robot show that TIC-VLA consistently outperforms prior VLA models while maintaining robust real-time control under multi-second reasoning latency. Project website: https://ucla-mobility.github.io/TIC-VLA/
ClusIR: Towards Cluster-Guided All-in-One Image Restoration
Dec 11, 2025All-in-One Image Restoration (AiOIR) aims to recover high-quality images from diverse degradations within a unified framework. However, existing methods often fail to explicitly model degradation types and struggle to adapt their restoration behavior to complex or mixed degradations. To address these issues, we propose ClusIR, a Cluster-Guided Image Restoration framework that explicitly models degradation semantics through learnable clustering and propagates cluster-aware cues across spatial and frequency domains for adaptive restoration. Specifically, ClusIR comprises two key components: a Probabilistic Cluster-Guided Routing Mechanism (PCGRM) and a Degradation-Aware Frequency Modulation Module (DAFMM). The proposed PCGRM disentangles degradation recognition from expert activation, enabling discriminative degradation perception and stable expert routing. Meanwhile, DAFMM leverages the cluster-guided priors to perform adaptive frequency decomposition and targeted modulation, collaboratively refining structural and textural representations for higher restoration fidelity. The cluster-guided synergy seamlessly bridges semantic cues with frequency-domain modulation, empowering ClusIR to attain remarkable restoration results across a wide range of degradations. Extensive experiments on diverse benchmarks validate that ClusIR reaches competitive performance under several scenarios.
Token Expand-Merge: Training-Free Token Compression for Vision-Language-Action Models
Dec 10, 2025Vision-Language-Action (VLA) models pretrained on large-scale multimodal datasets have emerged as powerful foundations for robotic perception and control. However, their massive scale, often billions of parameters, poses significant challenges for real-time deployment, as inference becomes computationally expensive and latency-sensitive in dynamic environments. To address this, we propose Token Expand-and-Merge-VLA (TEAM-VLA), a training-free token compression framework that accelerates VLA inference while preserving task performance. TEAM-VLA introduces a dynamic token expansion mechanism that identifies and samples additional informative tokens in the spatial vicinity of attention-highlighted regions, enhancing contextual completeness. These expanded tokens are then selectively merged in deeper layers under action-aware guidance, effectively reducing redundancy while maintaining semantic coherence. By coupling expansion and merging within a single feed-forward pass, TEAM-VLA achieves a balanced trade-off between efficiency and effectiveness, without any retraining or parameter updates. Extensive experiments on LIBERO benchmark demonstrate that TEAM-VLA consistently improves inference speed while maintaining or even surpassing the task success rate of full VLA models. The code is public available on \href{https://github.com/Jasper-aaa/TEAM-VLA}{https://github.com/Jasper-aaa/TEAM-VLA}
RainDiff: End-to-end Precipitation Nowcasting Via Token-wise Attention Diffusion
Oct 16, 2025Precipitation nowcasting, predicting future radar echo sequences from current observations, is a critical yet challenging task due to the inherently chaotic and tightly coupled spatio-temporal dynamics of the atmosphere. While recent advances in diffusion-based models attempt to capture both large-scale motion and fine-grained stochastic variability, they often suffer from scalability issues: latent-space approaches require a separately trained autoencoder, adding complexity and limiting generalization, while pixel-space approaches are computationally intensive and often omit attention mechanisms, reducing their ability to model long-range spatio-temporal dependencies. To address these limitations, we propose a Token-wise Attention integrated into not only the U-Net diffusion model but also the spatio-temporal encoder that dynamically captures multi-scale spatial interactions and temporal evolution. Unlike prior approaches, our method natively integrates attention into the architecture without incurring the high resource cost typical of pixel-space diffusion, thereby eliminating the need for separate latent modules. Our extensive experiments and visual evaluations across diverse datasets demonstrate that the proposed method significantly outperforms state-of-the-art approaches, yielding superior local fidelity, generalization, and robustness in complex precipitation forecasting scenarios.
Exploring Training Data Attribution under Limited Access Constraints
Sep 16, 2025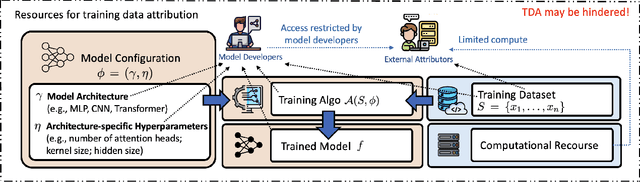
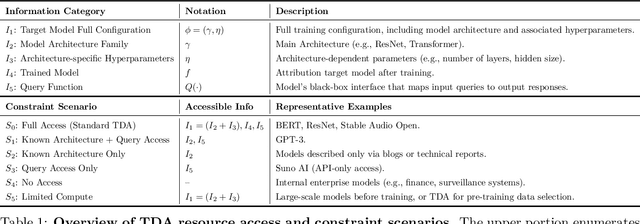
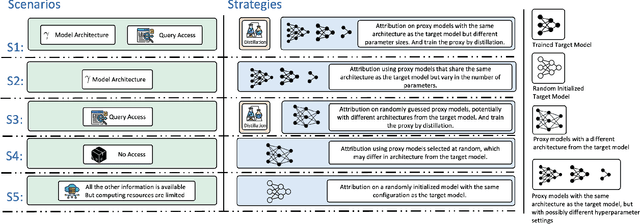

Training data attribution (TDA) plays a critical role in understanding the influence of individual training data points on model predictions. Gradient-based TDA methods, popularized by \textit{influence function} for their superior performance, have been widely applied in data selection, data cleaning, data economics, and fact tracing. However, in real-world scenarios where commercial models are not publicly accessible and computational resources are limited, existing TDA methods are often constrained by their reliance on full model access and high computational costs. This poses significant challenges to the broader adoption of TDA in practical applications. In this work, we present a systematic study of TDA methods under various access and resource constraints. We investigate the feasibility of performing TDA under varying levels of access constraints by leveraging appropriately designed solutions such as proxy models. Besides, we demonstrate that attribution scores obtained from models without prior training on the target dataset remain informative across a range of tasks, which is useful for scenarios where computational resources are limited. Our findings provide practical guidance for deploying TDA in real-world environments, aiming to improve feasibility and efficiency under limited access.
QuantV2X: A Fully Quantized Multi-Agent System for Cooperative Perception
Sep 03, 2025Cooperative perception through Vehicle-to-Everything (V2X) communication offers significant potential for enhancing vehicle perception by mitigating occlusions and expanding the field of view. However, past research has predominantly focused on improving accuracy metrics without addressing the crucial system-level considerations of efficiency, latency, and real-world deployability. Noticeably, most existing systems rely on full-precision models, which incur high computational and transmission costs, making them impractical for real-time operation in resource-constrained environments. In this paper, we introduce \textbf{QuantV2X}, the first fully quantized multi-agent system designed specifically for efficient and scalable deployment of multi-modal, multi-agent V2X cooperative perception. QuantV2X introduces a unified end-to-end quantization strategy across both neural network models and transmitted message representations that simultaneously reduces computational load and transmission bandwidth. Remarkably, despite operating under low-bit constraints, QuantV2X achieves accuracy comparable to full-precision systems. More importantly, when evaluated under deployment-oriented metrics, QuantV2X reduces system-level latency by 3.2$\times$ and achieves a +9.5 improvement in mAP30 over full-precision baselines. Furthermore, QuantV2X scales more effectively, enabling larger and more capable models to fit within strict memory budgets. These results highlight the viability of a fully quantized multi-agent intermediate fusion system for real-world deployment. The system will be publicly released to promote research in this field: https://github.com/ucla-mobility/QuantV2X.